[내배캠] 데이터분석 6기/본캠프 기록
[본캠프 53일차] SQL 공부, 머신러닝 공부, 태블로 공부
물맨두
2025. 5. 1. 22:26

벌써 4월이 가고 5월이다. 오늘 4월 한 달 동안 함께했던 조를 떠나 다시 새로운 조원분들을 만났고, 새롭게 태블로 공부를 시작하고, 또 SQLD 시험도 접수했다. 여러모로 새롭게 시작하는 5월이다. 프로젝트 기간 동안 정신 없어서 일주일 정도 방치해뒀던 블로그에도 다시 TIL을 쓰고 주말에는 지난 프로젝트 동안 한 내용도 회고하며 정리해둬야겠다.
5월도 아자아자 화이팅이닷!
오늘 한 일은,
- SQL 공부
- [코드카타] SQL 3문제 풀기(166~168번)
- 머신러닝 공부
- [머신러닝 특강 - 최적화] 복습하기
- 태블로 공부
- 태블로 환경 설정하기
- [태블로 라이브세션] 1회차 수강하기
- [실습으로 배우는 태블로] 1주차 수강하기
- ADsP 공부
- [ADsP 자격증 챌린지] 7주차 수강하기
- 제57회 SQL 개발자(SQLD) 접수하기
SQL 공부: [코드카타] SQL 문제 풀기(166~168번)
166. African Cities
Given the CITY and COUNTRY tables, query the names of all cities where the CONTINENT is 'Africa'.
SELECT ci.name
FROM country co LEFT JOIN city ci ON co.code = ci.countrycode
WHERE (co.continent = 'Africa') AND
(ci.name IS NOT NULL)
167. Average Population of Each Continent
Given the CITY and COUNTRY tables, query the names of all the continents (COUNTRY.Continent) and their respective average city populations (CITY.Population) rounded down to the nearest integer.
SELECT co.continent,
FLOOR(AVG(ci.population))
FROM city ci INNER JOIN country co ON ci.countrycode = co.code
GROUP BY co.continent
168. Binary Tree Nodes
You are given a table, BST, containing two columns: N and P, where N represents the value of a node in Binary Tree, and P is the parent of N.
SELECT DISTINCT a.n,
CASE WHEN a.p IS NULL THEN 'Root'
WHEN b.p IS NULL THEN 'Leaf'
ELSE 'Inner' END
FROM bst a LEFT JOIN bst b ON a.n = b.p
ORDER BY a.n
오랜만에 SQL 문제 푸니까 새롭다.. 내일 QCC 어떡하지.
머신러닝 공부: [머신러닝 특강 - 최적화] 복습하기
머신러닝 챕터가 끝났지만 끝나지 않는 머신러닝 공부~~
약간 지금 다시 보면 지난 프로젝트 회고하면서 내용이 더 잘 이해될 것 같아서 학습 주차에 다시 보려고 한다.

모델의 일반화
underfitting vs overfitting
- 과소적합(underfitting) : 모델이 너무 단순하여 데이터의 패턴을 충분히 학습하지 못한 상태
- 훈련 데이터조차 잘 설명하지 못하고, 새로운 데이터가 들어왔을 때 오차가 크게 발생하는 현상
- 높은 편향 = 추정값들이 실제값들로부터 멀리 떨어져 있음
- [해결] 모델 복잡도를 높이고, feature를 추가하기
- 과적합(overfitting) : 모델이 너무 복잡하여 훈련 데이터의 노이즈나 불필요한 패턴까지 학습한 상태
- 훈련 데이터를 과하게 학습하여 훈련 데이터에선 노이즈가 낮으나 새로운 데이터에선 오차가 크게 발생하는 현상
- 높은 분산 = 추정값들이 서로 많이 퍼져 있음
- [해결] 모델을 단순화하고, 모델 정규화를 하고, 데이터 크기를 늘리기
모델 단순화: 너무 많이 파라미터를 설정했다면 덜어내고, depth를 너무 깊게 설정했다면 줄이기 등
모델 정규화: 특정 feature에 의존하지 않도록 가중치를 조절하기 등
데이터 크기 증가: 다양한 패턴을 일반화하는데 도움이 되도록 더 많은 데이터를 모으기 등
모델 복잡도와 일반화 성능 간 관계
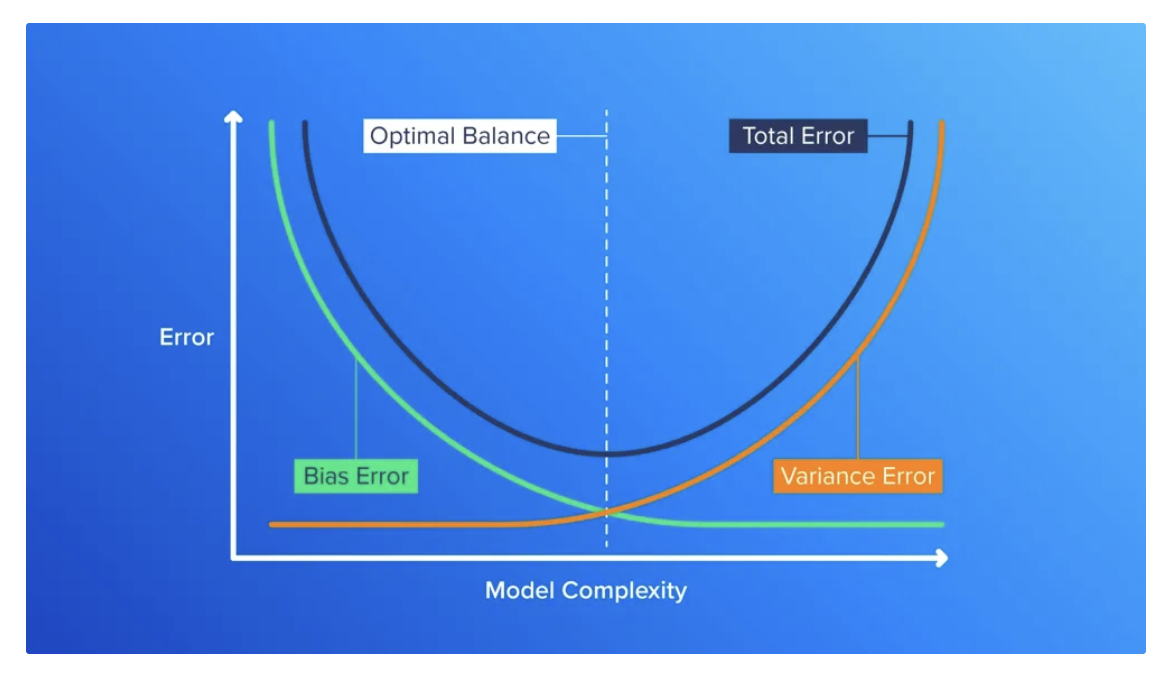
- 모델 복잡도가 너무 낮으면 훈련 데이터와 검증 데이터 모두 오차가 높게 나타남
- 모델 복잡도가 증가할수록 훈련 데이터와 검증 데이터 모두 점점 오차가 줄어들고 편향도 줄어듦
- 모델 복잡도가 일정 수준을 지나쳐 계속 증가하면 갈수록 검증 데이터에서 오차가 증가하기 시작하면서 전체적인 오차가 다시 늘어나게 됨
- 이런 점을 고려하여 총 오차가 가장 적은, 편향-분산이 잘 균형 잡힌 모델을 만드는 것이 중요함
sklearn.model_selection의 validation_curve를 사용해 이를 계산할 수 있음
Train/Test split의 한계와 교차검증의 필요
- train/test split의 한계
- 데이터 사용에서의 효율 문제; 전체 데이터 중 일부는 test에만 사용되고 버려지기에 이것을 모델 훈련에 사용할 수 없음
- 분할 편향의 문제; 특정 분할에 우연히 좋은 성능을 보였고, 다른 분할에서는 성능이 낮아질 수 있음
- 평가 결과의 불안정성; 한 번의 train/test 평가로 얻은 점수는 신뢰도가 낮을 수 있음
- [해결] 교차 검증(cross-validation)
- 데이터를 여러 번 나누어 여러 번 평가함으로써, 보다 신뢰할 수 있는 성능 추정치를 얻는 기법
= 모델의 일반화 성능을 보다 정확하고 안정적으로 추정할 수 있음 - 방법: K-Fold, Stratified K-Fold
- K-Fold: 데이터를 K등분하여 K번의 훈련-검증을 수행
- Stratified K-Fold: 분류 문제에서 각 클래스의 비율을 폴드마다 원본 데이터의 분포와 유사하게 유지하도록 데이터를 분할해 K번의 훈련-검증을 수행
- 데이터를 여러 번 나누어 여러 번 평가함으로써, 보다 신뢰할 수 있는 성능 추정치를 얻는 기법
하이퍼파라미터
하이퍼파라미터(Hyperparameter)
- 하이퍼파라미터: 모델 학습 과정에서 사용자가 직접 설정해야 하는 값 ↔︎ 모델 파라미터 (ex. 회귀계수 등)
- 하이퍼파라미터 방법론: ①경험적 튜닝, ②GridSearch, ③RandomSearch
- 하이퍼파라미터 변화에 따른 모델의 훈련 및 검증 성능을 선 그래프나 히트맵을 통해 시각화할 수도 있음!
하이퍼파라미터 튜닝 방법
- Grid Search: 탐색하고자 설정한 하이퍼파라미터 값들의 목록을 완전 탐색하여 최적의 점수를 낸 조합을 선택
sklearn.model_selection에서 GridSearchCV를 사용 - Random Search: 탐색하고자 설정한 하이퍼파라미터 값들의 목록에서 입력한 탐색 횟수만큼 무작위로 값을 뽑아서 조합을 탐색해서 그 중 최적의 점수를 낸 조합을 선택
sklearn.model_selection에서 RandomizedSearchCV를 사용
앙상블 방법론
- Bagging: 같은 종류의 모델을 여러 개 학습시키고 그 예측을 평균/투표한 것을 종합
ex.랜덤 포레스트 - Boosting: 순차적으로 모델들을 학습시키되, 이전 모델이 못 맞춘 부분에 가중치를 두어 다음 모델이 학습
ex. AdaBoost, Gradient Boosting, XGBoost, LightGBM- 모델이 많아지면 과적합 우려가 있으므로 조기 종료나 규제를 함께 사용함
- Voting: 서로 다른 종류의 모델의 예측을 투표로 결합
- 일반적으로 단일 모델을 썼을 때보다 성능이 향상되는 편이지만, 구성된 모델들이 충분히 다양해야 효과가 큼
- Stacking: Voting과 달리 단순 투표가 아닌, 기저 모델들이 예측한 결과를 특성으로 하여 메타 모델이 최종 예측을 하도록 학습
- 메타 모델 선정 기준은 일반적으로,
단순 선형 모델이면 메타 모델로 로지스틱 회귀나 선형 회귀 모델을
분류하는 트리 기반 모델이면 Gradient Boosting이나 랜덤 포레스트를,
그리고 규제가 있는 모델을 사용했다면 엘라스틱 넷이나 LightGBM을 사용함
- 메타 모델 선정 기준은 일반적으로,
태블로 공부: [실습으로 배우는 태블로] 1주차 수강하기
BI(Business Intelligence)
BI 개요
- BI : 비즈니스 데이터를 분석하고 실행 가능한 인사이트로 전환해 조직의 모든 사용자가 더 합리적인 의사결정을 내리도록 하는 데 사용되는 과정(비즈니스 분석, 데이터 마이닝, 데이터 시각화 등)과 도구 과정과 도구를 모두 BI라고 지칭한다고 함
- 실무에서 BI 도구를 사용하면 흩어져있는 각 팀들의 엑셀 파일을 수작업으로 정리할 필요 없이,
전사 BI 자동화로 BI 대시보드에서 쉽게 파악할 수 있음 업무 효율 향상! - [참고] Tableau가 소개하는 "비즈니스 인텔리전스: 개념 및 중요한 이유"
- 실무에서 BI 도구를 사용하면 흩어져있는 각 팀들의 엑셀 파일을 수작업으로 정리할 필요 없이,
- 실무에서의 BI 과정
- 대시보드에 어떤 지표를 추가할지 유관 부서와 의견을 조율
- 대시보드를 설계함에 있어서 어떤 지표를 선정할지 고민
- 데이터가 잘못 적재됐을 경우에 데이터 엔지니어와 소통
- ➡️ "현업에서 데이터 분석가는 대시보드를 구축해 다양한 팀들의 의사결정을 지원하는 역할을 한다"
BI 업무 절차
- 데이터 인프라: 데이터 레이크 → 데이터 웨어하우스 → 데이터 마트
- 데이터 레이크(data lake): 모든 raw data(정형 데이터, 로그 데이터, 테이블 등) 저장소
- 데이터 웨어하우스(DW, data warehouse): 장기적으로 보존할 목적으로 데이터를 통합, 정제, 분석하여 정리한 저장소
ex. AWS Redshift, Snowflake, Google Bigquery - 데이터 마트(DM, data mart): 부서별로, 또 목적에 따라 분석하기 위해 만든 데이터 웨어하우스의 데이터 일부
- 이 부분의 설명은 이전에 ADsP 온라인 강의 들으면서 정리한 '데이터 마트' 부분을 참고해도 좋을 듯
- BI 업무 절차
- ① BI를 위한 데이터 마트 설계 및 구축하기; 데이터 엔지니어/백엔드 엔지니어, 애널리틱스 엔지니어, BI 엔지니어
- ② BI 대시보드 구축하기; 데이터 분석가, BI 분석가
SQL 혹은 태블로 문법으로 계산식 및 함수를 활용해 대시보드를 시각화함 - ③ BI 대시보드를 기반으로 의사결정하기; 경영진, 프로덕트 오너, 프로덕트 매니저
BI 도구
태블로(Tableau)
- 장점
- 엑셀, csv, 스프레드시트 등 다양한 형식의 파일을 대시보드로 만들어 쉽게 공유할 수 있음
- 간단한 사용만으로 대화형 대시보드와 시각화 그래프를 생성할 수 있음
- 최근 많은 회사들이 BI도구로 사용함
- 활발한 커뮤니티와 많은 무료 템플릿 및 강의들을 참고하기 좋음
- 단점
- 데이터 용량이 크거나 개발한 대시보드의 양이 많아지면 대시보드 로딩 속도가 느려짐
- 다른 BI도구에 비해 비쌈 무료인 BI도구들도 많아서..
다른 BI 도구들
- BI 대시보드 도구 전사 데이터를 연결해 지표들을 시각화하는 도구, 즉 비즈니스 전반
- Google Locker Studio 구글 스프레트시트와 연동 가능, 일부 유료이긴 하나 무료 기능만으로도 많은 기능들을 활용할 수 있어 현업에서 많이 씀
- Microsoft PowerBI MS 프로그램으로 사용하는 조직은 PowerBI를 전사 BI툴로 많이 사용하는 편
- Redash
- Apache Superset
- Microstrategy(MSTR)
- 프로덕트 대시보드 도구 특정 웹/앱 사용자 행동 데이터를 중심으로 분석하는 도구
- GA4
- Amplitude
- Mixpanel
- 파이썬 라이브러리를 활용한 대시보드
- plotly dash
- streamlit
- gradio