[내배캠] 데이터분석 6기/본캠프 기록
[본캠프 55일차] 머신러닝 개인 과제, 태블로 공부
물맨두
2025. 5. 7. 23:22

믿기지 않는다. 연휴 아껴 썼는데(?) 벌써 끝이라니.
...일어나서 할 일을 하자.
오늘 한 일은,
- 태블로 공부
- [태블로 라이브세션] 2회차 수강하기
- [실습으로 배우는 태블로] 3주차 수강하기
- 머신러닝 공부
- [머신러닝 개인 과제 - 해설 세션] 수강하기
- ADsP 공부
- ADsP 모의고사 오답 정리하기
- 첫 번째 아티클 스터디하기 (누적은 26번째(11+4+5+5+1))
머신러닝 공부: 머신러닝 개인 과제 정리하기
오늘 10시까지 머신러닝 개인 과제를 제출해야 해서 어제 자기 전에 조금 풀고서 제출했다. 문제들이 크게 어려운 것은 없었고 오히려 지난 챕터의 내용들을 가볍게 되짚어 볼 수 있게끔 튜터님이 출제해주셔서 다시 복습할겸 블로그에도 해당 내용을 정리해두는 게 좋을 것 같았다. 문제는 필수 6문제, 도전 2문제로 총 8문제였다. 어제 자기 전에 7번까지 풀고 제출했고, 도전 2번은 오늘 아침에 혼자서 풀었다.
필수 1. pandas 응용
# 라이브러리 불러오기
import pandas as pd
# statistics 파일 불러오기
df = pd.read_csv('statistics.csv')
# Category 기준 Customer ID 컬럼은 Count, Purchase Amount(USD) 컬럼은 Sum 연산 (한번의 group by)
df2 = df.groupby('Category').agg({'Customer ID' : 'count', 'Purchase Amount (USD)' : 'sum'})
- df.groupby('기준 컬럼').agg()
- 기준 컬럼을 2개 이상 설정할 수도 있다. 그럴 시에는 리스트 형태로 기입해야 한다.
ex) df.groupby(['Age', 'Gender']) - .agg() 자리에 mean(), sum() 등의 통계함수를 바로 작성할 수도 있다.
그러면 df 내에 통계 계산이 가능한 모든 수치형 컬럼들에 대해서 결과를 산출한다.
ex) df.groupby('Category').mean() - .agg()를 활용해 통계함수를 2개 이상 설정할 수 있다. 마찬가지로 리스트 형태로 기입하면 된다.
ex) df.groupby('Category').agg(['count', 'median']) - .agg()를 활용해 다중 통계량을 구할 때, 컬럼별로 통계함수를 다르게 적용할 수 있다.
ex) df.groupby('Category').agg({'Customer ID' : 'count', 'Purchase Amount (USD)' : 'sum'})
- 기준 컬럼을 2개 이상 설정할 수도 있다. 그럴 시에는 리스트 형태로 기입해야 한다.
필수 2. pandas 응용
# 라이브러리 불러오기
import pandas as pd
# df에 "Purchase Amount(USD)_누적" 컬럼 생성하기
df['Purchase Amount (USD)_누적'] = df['Purchase Amount (USD)'].expanding().sum()
df[['Purchase Amount (USD)', 'Purchase Amount (USD)_누적']]
- df['컬럼 명'].expanding().통계함수
- 입력한 컬럼의 누적합을 구하고자 한다면 통계함수에 sum()을 작성하고
입력한 컬럼의 누적 평균을 구하고자 한다면 통계함수에 mean()을 작성하면 된다.
- 입력한 컬럼의 누적합을 구하고자 한다면 통계함수에 sum()을 작성하고
필수 3. 기초 통계
# 라이브러리 불러오기
import pandas as pd
# 소수점 자릿수 설정하기
pd.options.display.float_format = '{:.2f}'.format
# 성별에 따른 Review Rating의 평균과 중앙값 구하기 (소수점 둘째 자리까지 표시)
pivot = pd.pivot_table(df, index='Gender', values='Review Rating', aggfunc=['mean', 'median'])
해석:
여성과 남성의 평균 평점은 비슷해보이나, 평균과 중앙값을 같이 보면
여성의 경우 평균보다 중앙값이 낮은 것으로 보아 평균보다 낮은 평점을 준 사람이 많아 보이고,
남성은 평균보다 중앙값이 더 높은 것으로 보아 평균보다 높은 평점을 준 사람이 많은 것으로 보입니다.
- pd.pivot_table(df, index='컬럼명', columns=' ', values=' ', aggfunc=' ')
- index: 인덱스로 사용할 컬럼명
- columns: 열로 사용할 컬럼명
- values: 값으로 사용할 컬럼명
- aggfunc: 어떻게 계산할지
- 각 파라미터는 리스트를 통해 둘 이상을 입력할 수 있다.
필수 4. 통계적 가설검정
# 귀무가설: 남성과 여성의 평균 평점에 차이가 없을 것이다
# 대립가설: 남성과 여성의 평균 평점에 차이가 있을 것이다.
# 라이브러리 불러오기
import pandas as pd
import scipy.stats as stats
# 성별에 따른 review rating 컬럼만 가져오기
mask_f = (df['Gender'] == 'Female')
mask_m = (df['Gender'] == 'Male')
df_f = df[mask_f]
df_m = df[mask_m]
df_f = df_f[['Review Rating']]
df_m = df_m[['Review Rating']]
# t-test 진행하기
t, pvalue = stats.ttest_ind(df_f, df_m, equal_var=True)
t, pvalue # (array([-0.50971475]), array([0.61028017]))
# p값이 0.05보다 크므로 귀무가설을 기각할 수 없다. 이는 남성과 여성간 평균 평점에 유의미한 차이가 없다고 해석할 수 있다.
해석:
성별에 따른 Review Rating 컬럼에 따른 t-test를 진행하기에 앞서 다음과 같이 귀무가설과 대립가설을 세운다.
- 귀무가설: 남성과 여성의 평균 평점에는 차이가 없을 것이다.
- 대립가설: 남성과 여성의 평균 평점에는 차이가 있을 것이다.
t-test를 진행한 결과, p값(0.61028017)이 0.05보다 크므로 귀무가설을 기각할 수 없다. 즉 귀무가설을 채택한다.
이는 남성과 여성간 평균 평점에 유의미한 차이가 없다고 해석할 수 있다.
- t-검정(t-test) : 두 집간 간 평균의 차이가 통계적으로 유의미한지 확인하는 검정 방법
- 연속형 자료를 대상으로, 모집단의 분산을 알 수 없는 경우에 주로 활용한다
- 독립표본 t-test와 대응표본 t-test
- 독립표본 t-test : 두 독립된 그룹의 평균을 비교한다
- 대응표본 t-test : 동일한 그룹의 사전/사후 평균을 비교한다
- 독립된 두 그룹의 평균을 비교할 때는 scipy 라이브러리에서 stats.ttest_ind() 함수를 사용한다
- t-score와 p-value를 구할 수 있다
- 파라미터 equal_var: 입력한 두 그룹의 분산이 동일한지
- t-score : 그룹 간 얼마나 차이가 있는지를 보여주는 지표
- t-score가 크면 두 그룹 간 차이가 크다는 의미
- t-score > 0: 첫 번째 그룹의 평균이 큼
t-score < 0: 두 번째 그룹의 평균이 큼
- p-value : 어떤 사건이 우연히 발생할 확률(0 이상, 1 이하의 값)
- p-value가 유의수준 0.05보다 작아야만 대립가설을 채택할 수 있다
필수 5. 통계적 가설검정
# 귀무가설: Color와 Season은 독립적일 것이다
# 대립가설: Color와 Season은 관련이 있을 것이다.
# 라이브러리 불러오기
import pandas as pd
from scipy.stats import chi2_contingency
# 두 범주형 변수에 대한 빈도표 생성하기
crosstab = pd.crosstab(df['Color'], df['Season'])
# 카이제곱 통계량과 p값 구하기
chi2, p, dof, expected = chi2_contingency(crosstab)
print(f'카이제곱 통계량: {chi2:.3f}, p값: {p:.3f}, 자유도: {dof}') # 카이제곱 통계량: 64.651, p값: 0.719, 자유도: 72
# p값이 유의 수준인 0.05보다 크므로 귀무가설을 채택한다. 따라서 Color와 Season은 서로 독립적인 변수라고 판단할 수 있다.
해석:
두 범주형 변수에 대한 카이제곱 검정을 진행하기에 앞서 다음과 같이 귀무가설과 대립가설을 세운다.
- 귀무가설: Color와 Season은 독립적일 것이다.
- 대립가설: Color와 Season은 관련이 있을 것이다.
카이제곱 검정을 진행한 결과, 카이제곱 통계량(64.651)과 자유도(72)를 비교했을 때에 카이제곱 통계량이 자유도보다 낮으므로 기대값과 실제값이 그리 다르지 않아 독립적일 가능성이 크고,
또한 p값(0.719)이 유의수준 0.05보다 크므로 이는 우연히 나올 수 있는 수준이기에 귀무가설을 채택해 Color와 Season은 서로 관련이 없다고 해석할 수 있다.
- 카이제곱 검정
: 범주형 데이터의 표본 분포가 모집단 분포와 일치하는지를 검정하거나(적합도 검정), 두 범주형 변수 간 독립성을 확인하는(독립성 검정) 검정 방법- 범주형 변수를 대상으로 한다
- 적합도 검정: 관찰된 분포와 기대된 분포가 일치하는가
- 독립성 검정: 두 범주형 변수 간 독립성이 있는가 (서로 연관성 있음 → 독립성 없음, 서로 연관성 없음 → 독립성 있음)
- 독립성 검정은 ①두 범주형 변수의 빈도표를 만들어 → ②scipy 라이브러리의 chi2_contingency() 함수로 카이제곱 통계량을 구한다
- pd.crosstab(컬럼 1, 컬럼 2) : 빈도표 만들기
- chi2 : 카이제곱 통계량
(값이 클수록 실제 빈도와 기대 빈도와 차이가 큼 → 독립성이 없을 가능성이 큼) - p: p-value로, 귀무가설이 발생할 확률
- dof: 자유도
(카이제곱 통계량을 해석하는 기준선으로, 카이제곱 통계량이 얼마나 큰지를 판단할 수 있음)
필수 6. 머신러닝
# 라이브러리 불러오기
import numpy as np
from sklearn.linear_model import LinearRegression
import statsmodels.api as sm
# X와 y 선언하기
X = np.array([10, 20, 30, 40, 60, 100]).reshape(-1, 1) # 광고 예산
y = np.array([50, 60, 70, 80, 90, 120]) # 일일 매출
# 선형 회귀 모델로 회귀 계수와 절편 구하기
model = LinearRegression()
model.fit(X, y)
a = model.coef_[0]
b = model.intercept_
print(f'회귀식: y = {a:.3f}x + {b:.3f}') # 회귀식: y = 0.756x + 45.562
# 광고 예산이 1,000만원일 경우의 매출 예측하기
predicted_sales = model.predict([[1000]])
print(f'새로운 광고 예산이 1,000만 원일 경우의 예상된 매출: {predicted_sales[0]:.2f}만 원') # 801.81만 원
# 회귀 분석 결과 해석하기
results_lr = sm.OLS(y, sm.add_constant(X)).fit()
results_lr.summary()
# 주어진 X와 y로 선형 회귀 모델을 학습시켰을 때 회귀식 'y = 0.756x + 45.562'이 나왔고, 해당 모델로 광고 예산이 1,000만 원일 때에 매출이 801.81만 원 나올 것을 예측해 볼 수 있다. 이는 R제곱 값이 0.99로 99%만큼의 설명력을 가진다고 판단할 수 있습니다.
태블로 공부: [실습으로 배우는 태블로] 3주차 수강하기
태블로로 데이터 시각화하기 - 기본
1. 선 그래프
- 시계열 데이터를 시각화하여, 변화량과 트렌드를 한 눈에 파악하기에 용이함
- 연속적인 데이터에 적합함
[실습] - 연도별 에어비앤비 호스트 수 증가 추이를 선 그래프로 시각화하기

- ① listings.csv에서 열에는 Host Since 컬럼을, 행에는 Host Id 컬럼을 끌어와 가져온다
- Host Since는 연도별로 표시되도록 변경한다
- Host Id는 측정값 / 카운트(고유)로 지정한다
- ② 그러면 자동으로 선 그래프가 생성된다
- 선 그래프가 아닌 다른 그래프로 생성되었을 경우, 좌측 메뉴 중 '마크'에서 '라인'으로 설정한다
- ③ 마크 메뉴에서 레이블, 색상, 경로 등을 통해 원하는 형태로 선 그래프를 구성한다
- 레이블: '마크 레이블 표시' 체크 → 동그랗게 선 그래프 위에 강조됨
- 색상: 원하는 색상으로 그래프 색상 변경
- 경로: 원하는 선의 형태로 변경
2. 막대 그래프
- 범주 간 차이나 분포를 확인하기 좋음
- 범주형 데이터에 사용하기 적합함
- 주로 현황을 파악할 때 자주 활용됨
[실습] - 동네별로 평균적인 숙소 가격을 막대 그래프로 시각화하기

- ① listings.csv에서 행에는 Neighbourhood Cleansed 컬럼을, 열에는 Price 컬럼을 끌어와 가져온다
- Price는 측정값 / 평균으로 지정한다
- ② 그러면 자동으로 막대 그래프가 생성된다
- 선 그래프가 아닌 다른 그래프로 생성되었을 경우, 좌측 메뉴 중 '마크'에서 '막대'로 설정한다
- ③ 마크 메뉴에서 색상 등을 통해 원하는 형태로 막대 그래프를 구성한다
- 색상: 원하는 색상으로 그래프 색상 변경 (테두리까지!)
- ④ 상단 메뉴 중 '맞춤' 메뉴에서 맞춤 / 높이 맞추기로 지정해 모든 동네 이름이 한 페이지에 나타나도록 한다
3. 맵 차트
- 각 지역별 데이터의 분포 및 비중을 한 눈에 확인하기 용이함
[실습] - 보스턴 지역의 구역별 평균 후기 평점 분포를 맵 차트로 시각화하기

- ① listings.csv에서 Zipcode 컬럼을 끌어와 필드에 가져온다
- ② 우측 상단의 '표현 방식' 메뉴에서 맵 차트를 클릭한다
- ③ listings.csv에서 Review Scores Rating 컬럼을 마크 메뉴의 '색상'에 끌어와 가져온다
- Review Scores Rating을 측정값 / 평균으로 지정한다
- ④ listings.csv에서 Review Scores Rating 컬럼, Neighbourhood Cleansed 컬럼을 마크 메뉴의 '레이블'에 끌어와 가져온다
- Review Scores Rating을 측정값 / 평균으로 지정한다
- 마크 메뉴 / 레이블 / 레이블 편집에서 Neighbourhood Cleansed를 글자 크기 10, 굵게로 스타일을 변경한다
- ⑤ '백그라운드 레이어' 메뉴에서 투명도를 100%로 설정한다
- ⑥ 마크 / 도구 설명 / 도구 설명 편집에서 '도구 설명 표시'를 마우스오버로 변경한다
4. 파이 차트
- 각 부분이 전체에서 차지하는 비중을 이해하기에 좋음
- 단 변수가 적을 때 직관적으로 사용하기 용이함
[실습] - 룸 타입 비중을 파이 차트로 시각화하기

- ① listings.csv에서 Room Type 컬럼을 마크 메뉴의 '색상'에 끌어와 가져온다
- 색상 / 색상 편집의 '색상표 선택'에서 원하는 색상표를 고른다
- ② listings.csv에서 Id 컬럼을 마크 메뉴의 '각도'에 끌어와 가져온다
- Id를 측정값 / 카운트(고유 )로 지정한다
- Id를 퀵 테이블 계산 / 구성 비율로 지정한다
- ③ listings.csv에서 Room Type 컬럼, Id 컬럼을 마크 메뉴의 '레이블'에 끌어와 가져온다
- Id를 측정값 / 카운트(고유)로 지정한다
- ④ 상단 메뉴의 '맞춤'에서 맞춤 / 전체 보기를 지정해 파이 차트의 크기를 키운다
- Review Scores Rating을 측정값 / 평균으로 지정한다
- 마크 메뉴 / 레이블 / 레이블 편집에서 Neighbourhood Cleansed를 글자 크기 10, 굵게로 스타일을 변경한다
- ⑤ 마크 / 레이블 / 레이블 편집에서 원하는 방식으로 레이블이 나타나도록 순서, 글자 크기, 글자 굵기, 글자 색상 등을 수정한다
5. 트리맵 차트
- 데이터를 계층적으로 표현
- 카테고리별 특정 데이터 집합이 전체 데이터에서 차지하는 비율을 면적으로 표현해 카테고리별 구성 요소를 한 눈에 파악하기에 좋음
[실습] - 숙소 가격 합계가 큰 순서대로 가장 많이 리스트된 호스트를 트리맵 차트로 시각화하기

- ① listings.csv에서 행에는 Host Name 컬럼을, 열에는 Host Listings Count 컬럼을 끌어와 가져온다
- Host Listings Count를 측정값 / 합계로 지정한다
- ② 우측 상단의 '표현 방식' 메뉴에서 트리맵을 선택한다
- ③ listings.csv에서 Price 컬럼을 마크 메뉴의 '레이블'에 끌어와 가져온다
- Price를 측정값 / 평균으로 지정한다
- ④ listings.csv에서 Price 컬럼을 마크 메뉴의 '색상'에 끌어와 가져온다
- 마크 / 색상 / 색상 편집에서 색상표에서 원하는 방식으로 나타나도록 선택한다
태블로로 데이터 시각화하기 - 심화
6. 도넛 차트
- 파이 차트의 특성과 비슷함
- 태블로에서 대시보드의 KPI 카드로 많이 활용됨
7. 히트맵
- 태블로에서 히트맵을 하이라이트 테이블이라고 지칭함
- 색상의 그라데이션을 통해 측정값들을 한눈에 비교할 수 있음 대체로 가장 큰 값을 진하게 표시함
8. 영역 차트
- 선 아래 영역을 색으로 채워서 데이터의 영역 크기를 파악할 수 있음
- 시간에 따라서 데이터의 변화 및 흐름을 쉽게 파악할 수 있음
9. 스택 플롯
- 상대적인 비율을 직관적으로 파악하기 좋음
- 시간에 따라 데이터가 어떻게 변하는지 표현하기에 용이함
- 단, 단순 누적 그래프는 기준선이 일정하지 않기 때문에 비교하기가 어려움
[실습] - 일반 호스트와 슈퍼 호스트의 응답 시간별 비중을 스택 플롯으로 시각화하기
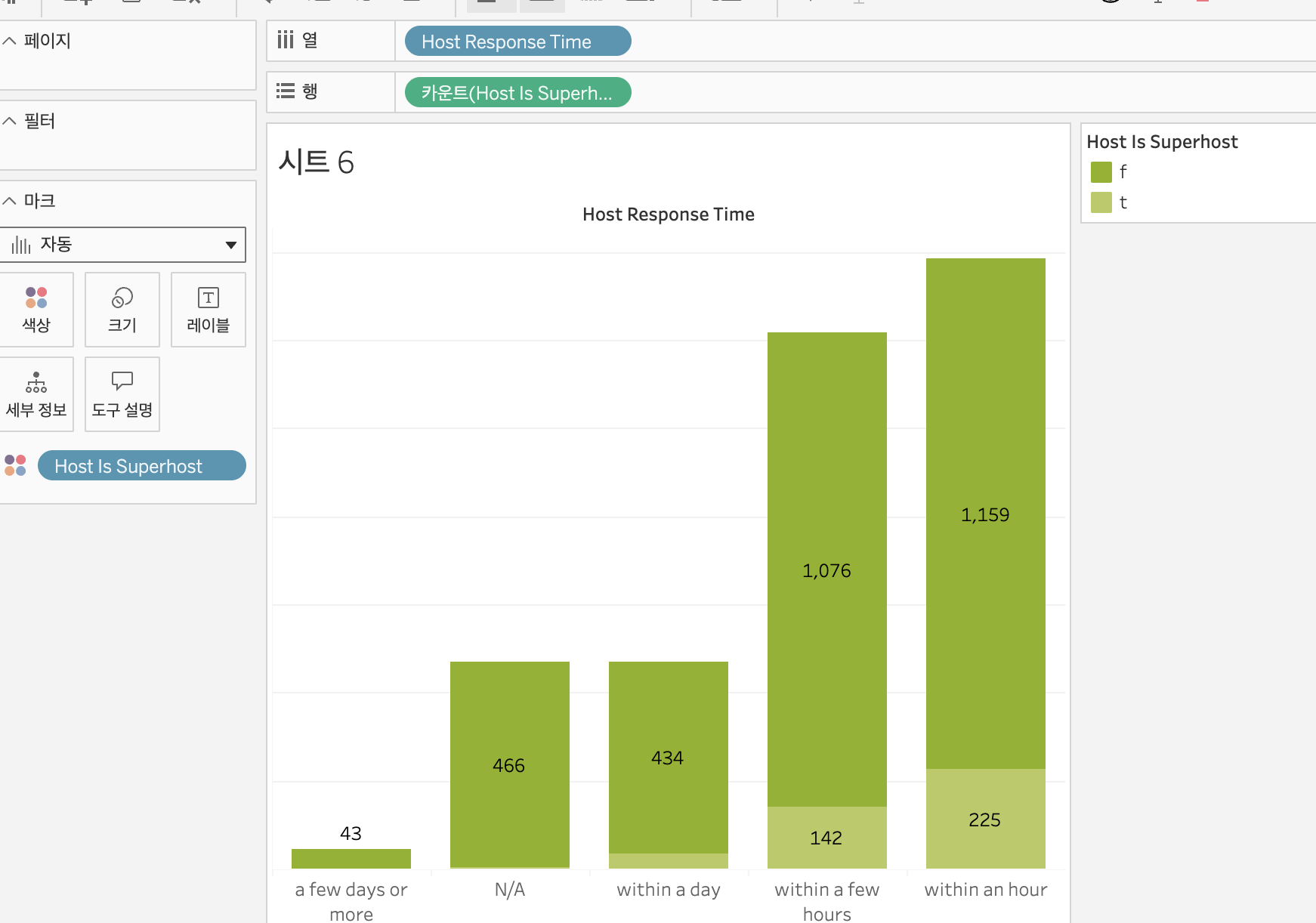
- ① listings.csv에서 열에는 Host Response Time 컬럼을, 행에는 Host Is Superhost 컬럼을 끌어와 가져온다
- 행으로 끌어오기 전에 Host Is Superhost는 boolean값으로 설정해놓는다 (아닌 경우에 데이터 유형 변경 / '부울'로 선택함)
- Host Is Superhost를 측정값 / 카운트로 지정한다
- ② Host Is Superhost 컬럼을 마크 메뉴의 '색상'에 끌어와 가져온다
- 마크 메뉴 / 색상 / 색상 편집의 '색상표 선택'에서 원하는 색상표를 선택한 후 색상표 할당 버튼을 누른다
- ③ 마크 메뉴 / 레이블에서 '마크 레이블 표시' 옵션을 선택한다
- ④ 그래프에서 좌측의 y축 'Host Is Superhost의 카운트'를 클릭해 '머리글 표시'를 해제해 숨긴다
- ⑤ 상단 메뉴의 '맞춤'에서 맞춤 / '너비 맞추기'를 지정해 그래프를 보기 좋게 키운다
태블로로 데이터 시각화하기 - 고급
10. 이중 축(콤보 차트)
- 하나의 차원을 두 개 이상의 측정값으로 동시에 파악하고자 할 때 효과적임
- 단, 축에 서로 다른 단위나 기준을 가지고 있다면 한 눈에 그래프를 파악하기 어려움
11. 평균선 / 참조선
- 분석 패널에서 평균선 라인/상수 라인/참조선을 추가하여 의사결정에 더욱 용이하도록 시각화를 할 수 있음
태블로로 데이터 분석하기
1. 박스 플롯
- 데이터의 분포와 이상치를 파악하기에 용이함
- 데이터를 분석할 때, 이상치를 제거하는 것이 능사가 아닌 이상치가 자사의 제품/서비스에서 의미하는 바가 무엇인지 해석하는 것이 중요함 현업에서 데이터 분석가로서 종사하게 되면 이상치의 특성을 깊이 파보는 작업을 한다고 함
[실습] - 숙박 시설 유형별 가격 분포를 박스 플롯으로 시각화하기
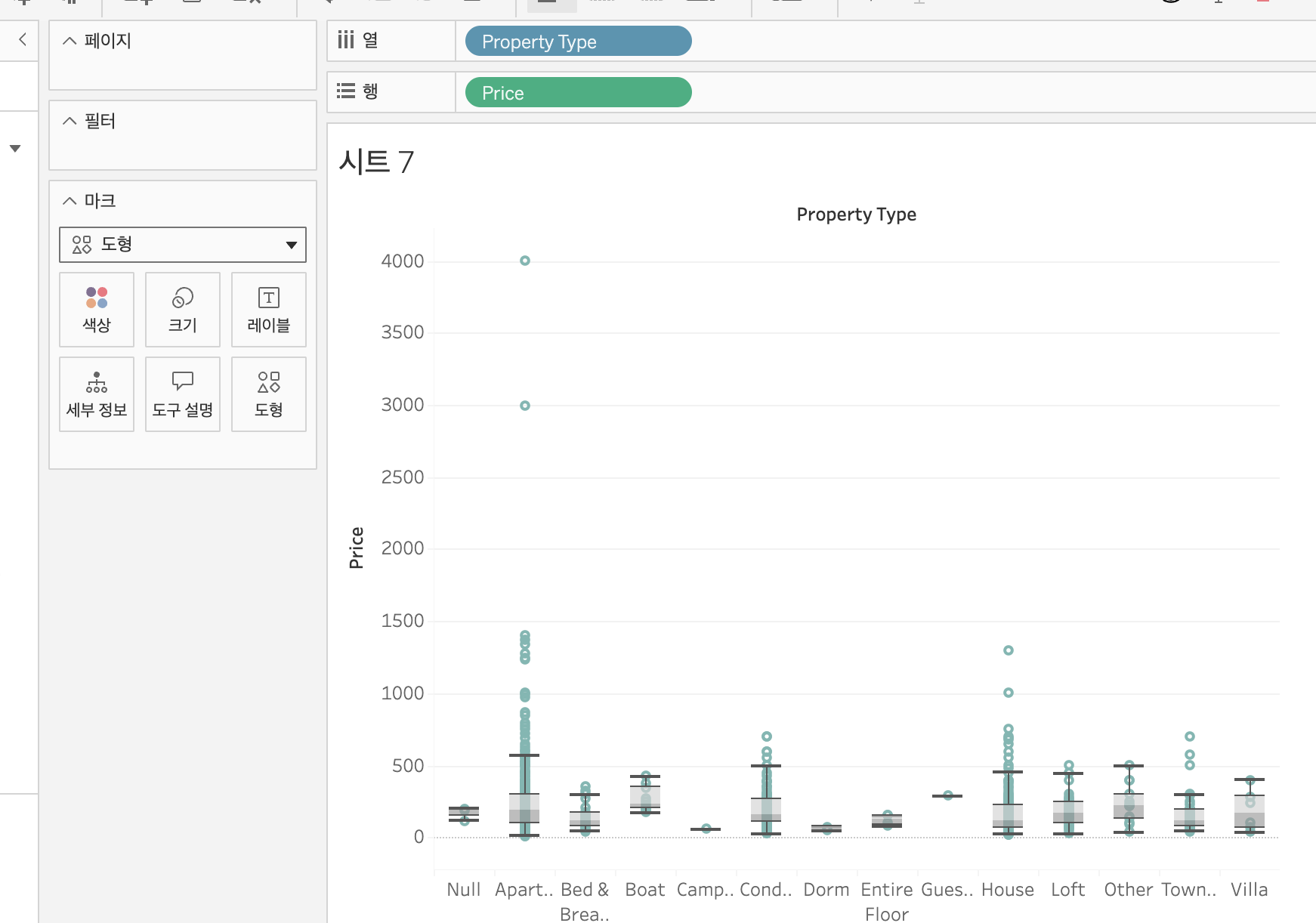
- ① listings.csv에서 행에는 Price 컬럼을, 열에는 Property Type 컬럼을 끌어와 가져온다
- Price를 '차원'으로 지정한다
- ② 마크 메뉴에서 '도형'으로 지정한다
- ③ 마크 메뉴 / 색상에서 원하는 색상으로 변경한다
2. 파레토 차트
3. 산점도
- 지표 간 어떤 선형적인 관계가 있는지 알아보기 위해 상관 분석을 자주 활용함
4. 시계열 예측
- 태블로에서 지수 평활법(exponential smoothing)을 활용해 과거 데이터에 기반하여 미래를 예측함
[실습] - 일별 에어비앤비 매출 예측을 시계열 예측으로 시각화하기

- ① calendar.csv에서 열에는 Date 컬럼을 4번 끌어와 가져와서 '분기'는 제거한다 (그러면 년, 월, 일 3개만 남음)
- ② calendar.csv에서 행에는 Price 컬럼을 끌어와 가져온다
- ③ 우측 상단의 '표현 방식' 메뉴에서 라인(연속형) 차트를 선택한다
- 그러면서 동시에 열이 일별로 바뀐다
- ④ 그래프에서 ctrl을 누른 채 클릭하여 뜨는 메뉴에서 예측 / '예측 표시'를 선택한다
- ⑤ 마크 메뉴 / 색상 / 색상 편집에서 원하는 색상표를 선택해 할당한다
- ⑥ 예측값을 표시하기 위해 마크 메뉴 / 레이블 / '마크 레이블 표시' 옵션을 체크하고, 레이블 지정할 마크에서 '라인 끝'을 선택한다
- ⑦ 우측에 있는 범례는 숨긴다
- ⑧ 상단 메뉴에서 서식 / 워크시트 / 음영 / 채우기에서 원하는 색상으로 워크시트의 배경색을 변경한다