
오늘 한 일은,
- 두 번째 아티클 스터디 (누적은 13번)
- SQL 공부
- 코드카타 한 문제 풀기
- 파이썬 공부
- 코드카타 열 문제 풀기
- [ADsP 자격증 챌린지] 2주차 수강하기 (2-2까지)
아티클 스터디 ②:
오늘 읽은 아티클 :
데이터 분석이란 무엇일까? | 요즘IT
오늘날 데이터는 어디에나 있습니다. 그리고 우리가 생산하는 데이터는 해를 거듭할수록 증가하고 있습니다. 우리가 사용할 수 있는 데이터의 양은 방대하지만, 이 모든 데이터로 무엇을 할 수
yozm.wishket.com
사실 오늘 읽은 아티클은 사전캠프 아티클 스터디에서 이미 읽은 아티클이다.
(👇이전 아티클 스터디 기록 보러가기👇)
[사전캠프 1일차] 내배캠 데이터분석6기 OT 및 데이터 분석 아티클 스터디
첫 만남은 너무 어려워~ 계획대로 되는 게 없어서~오늘은 내일배움캠프의 사전캠프 첫 날이다. 내배캠 사전캠프 총괄 매니저 조수진 님께 줌으로 OT를 받았다. 사전캠프가 전체적으로 진행되는
maandoo.tistory.com
그렇지만 본캠프에 접어들면서 새롭게 만난 조원분들 중 사전캠프에 참여하지 않고 합류하신 분들도 있기도 해서 사전캠프 기간에 이미 본 아티클이어도 스터디를 진행할 아티클로 선정하기로 했다.
사실 사전캠프 때 읽었어도 다시 읽으면 달라진 내 상황에 따라 달리 눈에 들어오는 점도 있을 것 같아 읽은 아티클을 한 번 더 읽어도 괜찮을 것 같다.

지난 스터디 때는 데이터에 맥락과 의미를 부여하는 스토리텔러로서의 데이터 분석가의 측면에 집중해 데이터를 다루는 과정에서 인문학적 소양이 필요할 듯하다고 생각했는데, 내일배움캠프의 데이터 분석 코스를 한 달 정도 참여하며 공부하고서 다시 보니 곧 다가올 팀 프로젝트 걱정에선지 데이터 분석의 과정 파트가 지난 번보다 눈에 들어왔다.
데이터 분석의 5단계에서 앞선 단계의 내용들이 결국 유의미하려면 마지막 '결과 공유' 단계에서 데이터 분석가의 커뮤니케이션 스킬에 많은 영향을 받겠구나 싶었다. 조직에서 동료들과 일하면서 커뮤니케이션 능력을 당연히 중요한 점이지만, 그 중에서도 기본 중에 기본은 역시 내가 말하고자 하는 바를 청자 역시 그대로 이해할 수 있도록 말하기를 잊지 말아야겠다.
파이썬 공부: 코드카타 풀기(21~30번)
021. 하샤드 수
양의 정수 x가 하샤드 수이려면 x의 자릿수의 합으로 x가 나누어져야 합니다. 예를 들어 18의 자릿수 합은 1+8=9이고, 18은 9로 나누어 떨어지므로 18은 하샤드 수입니다. 자연수 x를 입력받아 x가 하샤드 수인지 아닌지 검사하는 함수, solution을 완성해주세요.
def solution(x):
arr_x = list(map(int,str(x)))
if x % sum(arr_x) == 0:
answer = True
else:
answer = False
return answer우선 x의 자릿수의 합을 위해 변수 arr_x를 정의했다.
들어오는 숫자를 자릿수대로 찢기 위해 str() 함수를 사용했고
이를 문자 상태에선 연산할 수 없으니 다시 숫자로 바꿔주기 위해 map() 함수를 사용했다.
- map(함수, iterable 객체) : iterable 객체의 각 요소마다 함수를 적용하시오
그리고 이 숫자들을 담을 수 있게 list() 함수로 묶어준다.
마지막으로 if문을 사용해 x를 arr_x의 총합으로 나눴을 때 나머지가 없으면 True를, 있으면 False를 출력하도록 하여 하샤드 수인지 판별할 수 있도록 했다.
022. 두 정수 사이의 합
두 정수 a, b가 주어졌을 때 a와 b 사이에 속한 모든 정수의 합을 리턴하는 함수, solution을 완성하세요.
예를 들어 a = 3, b = 5인 경우, 3 + 4 + 5 = 12이므로 12를 리턴합니다.
def solution(a, b):
answer = 0
for i in range(a, b+1):
answer += i
return answer처음엔 위와 같이 작성했다.
그런데 오류가 발생해 확인했더니 a와 b엔 대소 구분이 없다는 조건이 있다.
그래서 (2, 4)나 (5,12) 같이 작은 수부터 순서대로 주어지면 연산하는 데 문제 없지만, (4, 2)처럼 주어지면 0을 출력한 것이다.
def solution(a, b):
answer = 0
if a < b :
for i in range(a, b+1):
answer += i
elif a > b :
for i in range(b, a+1):
answer += i
else :
answer = a
return answer그래서 if문을 사용해서 a < b 일 때, b < a 일 때, 그리고 a = b 일 때를 구분하여 각각 무사히 연산하도록 수정했다.
023. 콜라츠 추측
주어진 수가 1이 될 때까지 다음 작업을 반복하면, 모든 수를 1로 만들 수 있다는 추측입니다. 작업은 다음과 같습니다.
1-1. 입력된 수가 짝수라면 2로 나눕니다.
1-2. 입력된 수가 홀수라면 3을 곱하고 1을 더합니다.
2. 결과로 나온 수에 같은 작업을 1이 될 때까지 반복합니다. 위 작업을 몇 번이나 반복해야 하는지 반환하는 함수, solution을 완성해 주세요. 단, 주어진 수가 1인 경우에는 0을, 작업을 500번 반복할 때까지 1이 되지 않는다면 –1을 반환해 주세요.
def solution(num):
answer = 0
while answer < 500:
if num % 2 == 0:
num /= 2
answer += 1
else :
num *= 3
num += 1
answer += 1
if num == 1:
break
if answer == 500:
answer = -1
return answer우선 처음 입력한 코드는 이와 같다. 해당 코드로 샘플 테스트는 통과했는데 채점했을 때 틀린 부분이 발견됐다.
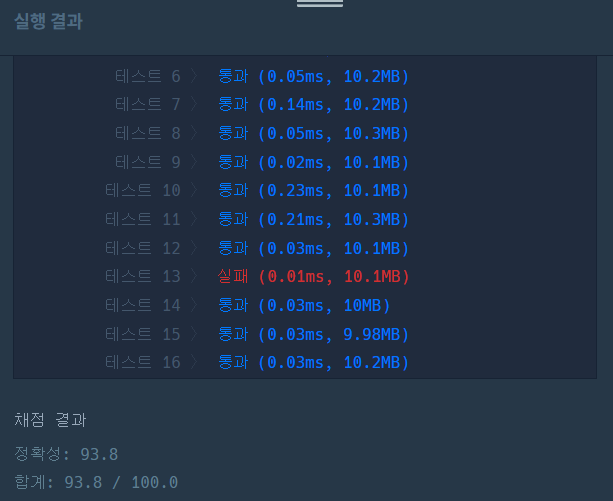
왜일까 싶어서 살펴보는데 문제 밑에 달린 공지가 눈에 들어왔다.
※ 공지 - 2022년 6월 10일 다음과 같이 지문이 일부 수정되었습니다.
주어진 수가 1인 경우에 대한 조건 추가
num = 1 일 때 0을 반환해야 하는 조건을 고려하지 않아 오류가 있었던 것 같다.
def solution(num):
answer = 0
while num != 1:
if num % 2 == 0:
num /= 2
answer += 1
else :
num = (num*3)+1
answer += 1
if num == 1:
break
if answer == 500:
answer = -1
break
return answerwhile에 적은 조건을 num != 1로 바꿔서, num이 1이면 while문을 실행하지 않고 0을 출력하게끔 했다.
024. 서울에서 김서방 찾기
String형 배열 seoul의 element중 "Kim"의 위치 x를 찾아, "김서방은 x에 있다"는 String을 반환하는 함수, solution을 완성하세요. seoul에 "Kim"은 오직 한 번만 나타나며 잘못된 값이 입력되는 경우는 없습니다.
def solution(seoul):
x = seoul.index('Kim')
answer = f'김서방은 {x}에 있다'
return answer주어진 입출력 예를 보니 seoul이라는 리스트에 사람 이름들이 들어가 있고, seoul이라는 리스트에서 "Kim"이 몇 번째에 위치하는지를 반환한다.
[참고] "파이썬(Python) 기초_리스트(list) 다루기, index사용, 유용한 함수 모음"
그래서 리스트에서 해당 값이 몇 번째에 위치하는지를 찾기 위해 list.index() 함수를 사용해서 x를 정의하고
answer에 f-string에 {}를 사용해서 요구한 대로 답을 반환하도록 작성했다.
026. 음양 더하기
어떤 정수들이 있습니다. 이 정수들의 절댓값을 차례대로 담은 정수 배열 absolutes와 이 정수들의 부호를 차례대로 담은 불리언 배열 signs가 매개변수로 주어집니다. 실제 정수들의 합을 구하여 return 하도록 solution 함수를 완성해주세요.
def solution(absolutes, signs):
answer = []
for i in range(len(absolutes)):
if signs[i] == True:
answer.append(absolutes[i])
else:
answer.append(absolutes[-i])
return sum(answer)이렇게 처음에 작성했더니 오류가 떠서 print를 추가해서 어떻게 연산했는지를 확인했다.

'왜 false에서 음수로 변환하지 않고 그냥 담기지?', '아니 왜 테스트 1과 테스트 2가 같은 패턴으로 값들을 담고 있지?' 등
뭔가 잘못됐음을 바라보다가 다음과 같이 코드를 수정했다.
def solution(absolutes, signs):
answer = []
for i in range(len(absolutes)):
if signs[i] == True:
answer.append(absolutes[i])
else:
answer.append(-absolutes[i]) #마이너스의 위치 변경
return sum(answer)처음엔 answer에 추가할 값을 적을 때 absolutes[-i]라고 적었더니 절대값에 음수가 추가되는 것이 아니라 absolutes 리스트에서 가져올 값의 위치만 달라질 뿐이었다.
그래서 테스트 1과 테스트 2의 sings 리스트 속 true/false 배열이 달랐어도 같은 패턴으로 값을 담았던 것이다.
음수 부호를 다시 올바른 위치로 수정하니 원하는 결과를 얻을 수 있었다.
029. 제일 작은 수 제거하기
정수를 저장한 배열, arr 에서 가장 작은 수를 제거한 배열을 리턴하는 함수, solution을 완성해주세요. 단, 리턴하려는 배열이 빈 배열인 경우엔 배열에 -1을 채워 리턴하세요.
def solution(arr):
arr.remove(min(arr))
answer = arr
if len(answer) == 0:
answer.append(-1)
return answer[참고] [python] 리스트(list) - 특정 값 제거 list.remove(), del(), pop(), clear() 등
우선 리스트에서 특정 값을 제거할 수 있는 함수를 찾아봤다.
list. remove() 함수를 이용해서 arr에서 최솟값을 제거했다.
그리고 list에 아무것도 들어있지 않으면 -1을 담아서 반환하도록 if문을 사용해 적어줬다.
ADsP 공부: [ADsP 자격증 챌린지] 2주차 수강하기
빅데이터
빅데이터의 정의
- 가트너그룹의 더그래니(Doug Laney)의 정의 (3V)
- 빅데이터는 데이터의 양(Volume), 데이터 유형과 소스 측면의 다양성(Variety), 데이터 수집과 처리 측면에서 속도(Velocity)가 급격히 증가하면서 나타난 현상
- 빅데이터의 새로운 특징 4V
- 더그 래니의 3V에 Value(가치) 또는 veracity(정확성)을 추가
빅데이터의 출현 배경 (환경 변화의 측면에서)
- 산업계 : 고객 데이터 축적
- 산업계에서 일어난 빅데이터 현상을 양질 전환 법칙으로 설명
- 이는 양적인 변화가 축적되면 질적인 변화도 이루어진다는 개념
- 학계 : 거대 데이터 활용 과학 확산
- 학계에서도 빅데이터를 다루는 현상들이 늘어나면서 필요한 기술 아키텍처 및 통계 도구들이 지속적으로 발전
- 기술발전 : 관련 기술의 발달
- 디지털 화의 급진전, 저장 기술의 발전과 가격 하락, 인터넷의 발전과 모바일 시대의 진전에 따른 클라우드 컴퓨팅 보편화와 분산처리 기술 등이 모두 빅데이터 출현과 직간접적 관련
- 클라우드 컴퓨팅은 빅데이터의 처리 비용을 획기적으로 낮춘 측면에서 그 중요성을 아무리 강조해도 지나치지 않음
빅데이터의 기능과 변화
- 빅데이터의 기능
- 빅데이터는 ‘산업혁명의 석탄, 철’
: 제조업뿐만 아니라 서비스 분야의 생산성을 획기적으로 끌어올려 사회, 경제, 문화, 생활 전반에 혁명적 변화를 가져올 것으로 기대 - 빅데이터는 ‘21세기의 원유’
: 경제 성장에 필요한 정보를 제공함으로써 산업 전반의 생산성을 향상시키고 새로운 범주의 산업을 만들어낼 것으로 전망 - 빅데이터는 ‘렌즈’
: 렌즈를 통해 현미경이 생물학 발전에 미쳤던 영향만큼, 빅데이터도 산업 발전에 큰 영향을 미칠 것으로 기대 - 빅데이터는 ‘플랫폼’
: 공동 활용의 목적으로 구축된 유무형의 구조물을 말하며, 다양한 서드파티 비즈니스에 활용되어 플랫폼 역할을 할 것으로 기대
- 빅데이터는 ‘산업혁명의 석탄, 철’
- 빅데이터가 만들어내는 변화 (과거에서 현재로)
- 사전처리 → 사후처리
: 기존 필요한 정보만 수집하고 필요하지 않은 정보를 버리는 시스템에서 가능한 많은 데이터를 모으고 다양한 방식으로 조합하여 숨은 인사이트를 발굴 - 표본조사 → 전수조사
: 데이터 수집 비용의 감소와 클라우드 기술의 발전으로 데이터 처리 비용이 감소하게 되면서 데이터 활용 방법이 전수조사로 변화 - 질 → 양
: 수집 데이터의 양이 증가할 경우 양질의 정보가 오류 정보보다 많기에 전체적으로 좋은 결과 산출에 긍정적인 영향을 미친다는 추론에 바탕 - 인과관계 → 상관관계
: 실시간 상관관계 분석에서 도출된 인사이트를 바탕으로 그에 상응하는 행동을 추천하는 일이 점점 늘어나고 있음
- 사전처리 → 사후처리
빅데이터의 가치
- 빅데이터의 가치 산정이 어려운 이유
- 데이터 활용 방식 :
빅데이터의 재사용이나 재조합, 다목적용 데이터 개발 등이 일반화되면서 특정 데이터를 누가, 언제, 어떻게 활용하는지 파악할 수 없게 됨에 따라 가치 산정이 어려워짐 - 새로운 가치 창출 :
데이터가 기존에 없던 가치를 창출함에 따라 그 가치를 산정하기 어려워짐 - 분석 기술의 발전 :
현재는 가치 없는 데이터일지라도 추후 새로운 분석 기법이 등장함에 따라 큰 가치를 만들어낼 재료가 될 수 있음
- 데이터 활용 방식 :
- 미래의 빅데이터 활용에 필요한 3요소
- 데이터 : 모든 것을 데이터화
- 기술 : 진화하는 알고리즘, 인공지능
- 인력 : 데이터 사이언티스트, 알고리즈미스트
빅데이터 활용 기본 7가지 기술
- ① 연관규칙 학습
- 변인들 간에 주목할 만한 상관관계가 있는지 찾아내는 방법
- ex) 우유 구매자가 기저귀를 더 많이 구매하는가?
- ② 유형 분석
- 새로운 사건이 속할 범주/분류를 찾아내는 방법 (이 사용자는 어떤 특성을 가진 집단에 속하는가?)
- ex) 온라인 수강생들을 특성에 따라 어떻게 분류할 것인가?
- ③ 유전 알고리즘
- 최적화가 필요한 문제의 해결책을 자연선택, 돌연변이 등과 같은 메커니즘을 통해 점진적으로 진화(Evolve)시켜 나가는 방법
- ex) 응급실에서 의사를 어떻게 배치하는 것이 가장 효율적인가?
최적화된 택배 차량 배치
- ④ 기계 학습
- 훈련 데이터로부터 얻은 특성을 활용해 예측하는 방법 (데이터 학습 → 예측 모형)
- 특정한 하나의 분석 방법이 아닌 다양한 분석 알고리즘을 활용해 예측하는 분석 모델 자체를 말함
=> 머신러닝의 범위는 넓음 (딥러닝도 머신러닝에 포함)
- ⑤ 회귀 분석
- 원인과 결과를 이용한 분석 (영향력 분석)
- 독립변수를 조작하며 종속변수가 어떻게 변하는지를 보고 두 변인의 관계를 파악하는 방법
- ⑥ 감정 분석
- 특정 주제에 대해 말하거나 글을 쓴 사람의 감정을 분석하는 방법
- ⑦ 소셜 네트워크 분석
- 사회관계망 분석으로도 불리며, 유저 사이의 관계를 분석하여 오피니언 리더, 즉 영향력 있는 사람을 찾아내는 데 활용
내일은 SQL 실시간 강의 2회차와 직무 스터디 발표회가 있다.
그래서 ADsP 강의고, 코드카타 문제고, 진도를 새로 많이 빼기보단 ADsP는 오늘 못 들은 분량을 마저 듣고 코드카타는 지금까지 푼 문제들을 빠르게 복습해보는 시간을 가지려고 한다.

'[내배캠] 데이터분석 6기 > 본캠프 기록' 카테고리의 다른 글
| [본캠프 6일차] 팀플 주제 선정, 파이썬 코드카타, SQL 코드카타, SQL 공부, ADsP 공부 (0) | 2025.02.24 |
|---|---|
| [본캠프 5일차] SQL 공부, 코드카타 복습(SQL, 파이썬), ADsP 공부 (0) | 2025.02.21 |
| [본캠프 3일차] SQL 코드카타, 파이썬 코드카타, MySQL 설치, ADsP 공부 (0) | 2025.02.19 |
| [본캠프 2일차] 파이썬 코드카타, 아티클 스터디①, SQLD 공부 (1) | 2025.02.18 |
| [본캠프 1일차] SQL 코드카타, SQLD 공부, 직무 스터디 (0) | 2025.02.17 |