
오늘 한 일은,
- SQL 공부
- [코드카타 ] SQL 3문제 풀기 (94~96번)
- 파이썬 공부
- [코드카타] 알고리즘 1문제 풀기 (60번)
- [라이브 세션] 파이썬 6회차 수강하기
- [데이터 전처리 & 시각화] 어제 들은 matplotlib 라이브러리 부분 실습하기
- [데이터 전처리 & 시각화] 완강하기
- 파이썬 라이브러리 개인과제 제출하기
SQL 공부: [코드카타] SQL 문제 풀기 (94~96번)
94. (1633) Percentage of Users Attended a Contest
Write a solution to find the percentage of the users registered in each contest rounded to two decimals.
Return the result table ordered by percentage in descending order. In case of a tie, order it by contest_id in ascending order.
SELECT contest_id,
ROUND((COUNT(user_id) / (SELECT COUNT(*) FROM Users))*100, 2) percentage
FROM Register
GROUP BY contest_id
ORDER BY percentage DESC, contest_id기억할 것!! 전체 중 일부에 대한 비율을 구할 때 전체의 수는 스칼라 서브쿼리로 구하기!
저번에도 코드카타 76번 문제를 풀 때 같은 부분에서 고전했는데 오늘도 똑같은 부분에서 스칼라 서브쿼리로 구하는 것을 바로 떠올리지 못하고 난항을 겪었다.
95. (1211) Queries Quality and Percentage
Write a solution to find each query_name, the quality and poor_query_percentage.
Both quality and poor_query_percentage should be rounded to 2 decimal places.
Return the result table in any order.
- quality : The average of the ratio between query rating and its position.
- poor query percentage : The percentage of all queries with rating less than 3
WITH pq AS ( --rating이 3점 미만인 쿼리들의 개수 세기
SELECT query_name,
COUNT(*) poor_cnt
FROM Queries
WHERE rating <= 2
GROUP BY query_name
)
SELECT q1.query_name,
ROUND(avg(q1.rating / q1.position), 2) quality,
IFNULL(ROUND(((q2.poor_cnt / COUNT(q1.rating)) * 100), 2), 0) poor_query_percentage
FROM Queries q1 LEFT JOIN pq q2 ON q1.query_name = q2.query_name
GROUP BY query_name(정말 리트 코드의 문제의 난이도 평가 기준을 알 수가 없다. 이게 난이도 쉬움이라니… 내가 그냥 어렵게 꼬아서 푸는 건가)
다른 부분은 특별히 어려운 점이 없었는데, poor_query_percentage를 계산하기 위해 고민하고 시도하는 데 많은 시간이 걸렸다.
메인 쿼리 기준 GROUP BY절에 query_name이 걸려있기 때문에 SELECT절에서 COUNT(rating) 하면 poor_query_percentage를 계산하는 분모값을 구할 수 있다.
이제 rating이 3점 미만인 것들만 세야 하는데, 처음엔 COUNT() 함수에 조건을 달아서 특정 조건에서만 집계할 수 있는 방법은 없는지 찾아봤다. 그런데 적당한 방법이 없어서 그냥 WITH 구문으로 해당 query_name에 따른 poor_query의 개수를 집계해 poor_cnt 컬럼에 나타내도록 했다.
그리고 가상의 테이블 pq를 Queries 테이블에 LEFT JOIN 해서 poor_query_percentage를 계산하는 분자값으로 poor_cnt를 취했다.
(근데 지금 보니까 혹시 스칼라 서브쿼리로 구했을 수도 있을 거 같은... 아니다. 아닌 거 같아, query_name을 공통 컬럼으로 JOIN 해서 풀었어야 하는 것 같다. 아냐, 모르겠어, 힘들다...)
96. (1193) Monthly Transactions 1
Write an SQL query to find for each month and country, the number of transactions and their total amount, the number of approved transactions and their total amount.
Return the result table in any order.
SELECT t1.month,
t1.country,
t1.trans_count,
IFNULL(t2.approved_count, 0) approved_count,
t1.trans_total_amount,
IFNULL(t2.approved_total_amount, 0) approved_total_amount
FROM (
SELECT SUBSTR(trans_date, 1, 7) month,
country,
COUNT(*) trans_count,
SUM(amount) trans_total_amount
FROM Transactions
GROUP BY month, country
) t1
LEFT JOIN
(
SELECT SUBSTR(trans_date, 1, 7) month,
country,
COUNT(*) approved_count,
SUM(amount) approved_total_amount
FROM Transactions
WHERE state = 'approved'
GROUP BY month, country
) t2
ON (t1.month = t2.month) AND
(t1.country = t2.country)
위의 쿼리로 풀었는데 country가 null이라고 하여 appoved_count와 approved_total_amount가 안 구해지는 것인지... 대체 왜야... 해당 15번 케이스의 입력 데이터를 가지고 테이블 t2 부분만도 실행해봤는데 그때는 또 요구한 대로 잘 연산해서 조회된다. 아무래도 JOIN 하면서 발생하는 문제 같은데 왜 이런 일이 발생하는지 이유를 알 수가 없다...
혹시나 해서 질문방에 이 문제에 대해 질문이 있는지 찾아봤는데 하나 있었다.

그러니까 이 문제를 JOIN 없이 풀 수 있다는 충격적인 사실.
SELECT SUBSTR(trans_date, 1, 7) month,
country,
COUNT(*) trans_count,
SUM(CASE WHEN state = 'approved' THEN 1 ELSE 0 END) approved_count, --COUNT()함수로 집계하는 것이 아니라 SUM()으로 하나씩 더해준다
SUM(amount) trans_total_amount,
SUM(CASE WHEN state = 'approved' THEN amount ELSE 0 END) approved_total_amount --이때는 조건에 일치하는 amount값을 모두 더해준다
FROM Transactions
GROUP BY month, country[참고] SQL CASE WHEN 구문 사용법 - 예제로 알아보기

근데 왜 IF가 아니라 CASE WHEN을 쓰는 건지 모르겠지만(라이브 세션에서 IF문 쓰지 말라고 들은 것 같긴 한데..흐릿),
CASE WHEN 구문을 집계함수와 함께 사용하여 특정 조건에 해당하는 값에 대해서만 집계 함수를 사용하고자 하는 경우에도 자주 사용한다고 한다.

파이썬 공부①: [코드카타] 알고리즘 문제 풀기 (60번)
60. 기사단원의 무기
아휴 길다, 길어
#첫 번째로 시도한 코드 (많은 케이스에서 시간 초과 발생으로 틀림)
def solution(number, limit, power):
answer = 0
for i in range(1, number+1): #기사 1번부터 number번까지 보겠다
cnt = 0 #각 기사당 약수의 개수를 저장할 변수 선언
for j in range(1, i+1): #해당 반복문을 통해 약수의 개수를 구함
if i % j == 0:
cnt += 1
if cnt > limit: #약수의 개수를 cnt에 구한 후, cnt가 limit을 넘는 경우와 아닌 경우를 달리 계산함
answer += power
else:
answer += cnt
return answer
첫 번째로 시도한 코드다.
어제 분명히 for문 2중 중첩의 위험성을 알게 됐지만, 문제를 보자마자 다른 방법이 생각이 안 나서 '우선 돌려보고 문제가 생기면 그때 생각하자' 하고 제출했다. 그런데 제출하자마자 금방 통과 안 되는 거 보고 '안 되는 구나' 직감했다.

어떻게 for문을 이중으로 사용하지 않을 수 있는지는 모르겠지만, 내가 제출한 코드의 비효율적인 면을 금방 감이 왔다. 나의 코드는,
- (1) 각 기사의 약수를 for문으로 세서 cnt(=약수의 개수)를 구하고
- (2) cnt가 limit을 초과하면 power를, 아니면 cnt를 더한다
이렇게 2개의 과정으로 이뤄져 있는데, 사실 cnt를 1씩 더해가며 세다가 cnt가 limit을 넘기면 더 이상 계산하지 않고 바로 answer에 power를 더하고 마치면 불필요한 연산을 막을 수 있다.
그래서 원래는 cnt가 limit을 넘어가면 answer에 power를 더하고 연산을 중지하고, 아니라면 계속 약수의 개수를 세도록 코드로 구현해보려고 while문을 이리저리 굴려봤는데 좀처럼 맘대로 돌아가지 않았다.
그 다음으로는 혹시 약수 구하는 공식이 있는지 찾아봤다.
[참고1] 소인수분해를 이용하여 약수 구하기, 약수 개수 구하기

방법은 간단했다. 그 숫자를 소인수분해 해서 각 소인수의 지수에 1을 더하여 전부 곱하면 된다. 근데 내가 푸는 거야, 그렇다쳐도 이걸 어떻게 코드로 구현하지… 아니, 구현한다 해도 결국 끝까지 약수의 개수를 구하는 것이나 소인수분해를 하는 거나 크게 시간이 절약되는 것 같진 않았다. 더 찾아봤다.
[참고2] [노트] 모든 약수를 구하는 알고리즘은 O(sqrt(n))이다.
[참고3] [Java] 약수의 개수 구하기


그러니까 숫자 N의 약수를 구할 때 √N의 약수의 개수를 구하는 것만으로도 약수의 총개수를 알 수 있다는 것이었다.
#두 번째로 시도한 코드 (정답 처리됨)
def solution(number, limit, power):
answer = 0
for i in range(1, number+1):
cnt = 0
for j in range(1, int((i**0.5)+1)): #약수의 개수를 √i 해준 것만큼만 구함
if i % j == 0:
cnt += 1
if i**0.5 == int(i**0.5): #최종적인 약수의 개수를 구하기 위한 판별식:
cnt = (cnt*2)-1 #√i가 i의 제곱근이면 2배한 것에서 1을 빼고
else:
cnt = cnt*2 #√i가 i의 제곱근이 아니라면 2배만 함
if cnt > limit: #약수의 개수가 limit을 초과하는지 판단하기
answer += power
else:
answer += cnt
return answer코드는 조금 더 길어졌지만 이번에는 코드가 금방 통과됐다.
파이썬 공부②: [데이터 전처리 & 시각화] 완강하기

오늘은 앞으로 혼자서 데이터 분석을 하거나 이에 대한 공부를 할 때 알아두면 좋은 팁들을 배우는 시간이었다.
혼자서 데이터 분석 공부하는 법
- 찾아보기
- 1️⃣ 10 minutes to pandas로 pandas 라이브러리를 사용하는 문법 자주 써보기 근데 이거 10분짜리 아님.. 더 걸리더라
- 2️⃣ 모르는 함수나 특정 함수가 기억나지 않을 때 구글에 검색하는 습관 들이기
- 데이터 분석을 시작하기 전에,
- 데이터 전처리와 데이터 시각화를 하기 전에 항상 무엇을 위해 데이터를 확인하고자 하는지 메모하고 시작하기!
- 무엇을 위해 데이터 전처리와 시각화를 진행하고자 하는지
- 데이터 처리 및 시각화를 통해 어떤 결과물을 얻을 것이라 예상하고 있는지
- 'As-Is, To-Be 기법'에 입각해 현재의 문제 상황과 달성하고자 하는 목표에 이르기 위해 어떻게 개선할 것인지 방향성 설정하기
- 데이터 전처리와 데이터 시각화를 하기 전에 항상 무엇을 위해 데이터를 확인하고자 하는지 메모하고 시작하기!
파이썬 공부③: 파이썬 라이브러리 개인 과제
컨디션 난조로 그만 눕고 싶었지만 정말이지 안타깝게도 개인 과제가 있었다. 4번까진 풀어놓은 걸 다행으로 여겨야 할까.

문제 유형: 필수
문제 1
#필수 1. 데이터 불러오기
import pandas as pd
#구글 드라이브의 csv 파일을 DataFrame으로 읽어오기
df = pd.read_csv("/content/drive/MyDrive/[내배캠] Data_6기_파이썬/flight_data_homework.csv") #파일을 데이터프레임으로 불러오기
#테이블의 행과 열의 개수 확인하기
df.shape
print(f'{df.shape} 행 수: {df.shape[0]} 열 수: {df.shape[1]}')
#테이블의 처음 5줄 확인하기
df.head()


문제 2
#필수 2. 결측치 처리
import pandas as pd
#컬럼별 결측치 개수 구하기
df.isnull().sum()
#결측치가 있는 행 제거하기
df.dropna()

문제 3
#필수 3. 조건에 맞는 데이터 추출하기
import pandas as pd #numpy 라이브러리를 불러오지 않아도 pandas에서도 기본적인 통계 함수들을 제공함
#Destination 컬럼 기준 price의 평균값과 중앙값 구하기(값은 소수점 첫 번째 자리까지만)
df.groupby('Destination')['Price'].agg(['mean','median']).round(1)
#Airline, Total_Stops 컬럼 기준 Route 컬럼을 중복값 없이 추출하고, 인덱스 재정렬하고, 이를 df2라는 이름으로 받기
df2 = df.groupby(['Airline', 'Total_Stops'])['Route'].nunique()
df2.reset_index()

문제 4
#필수 4. 조건에 맞는 데이터 추출하기2
import pandas as pd
#피봇테이블을 구현해, 출발지와 도착지를 기준으로 한 Airline 세고 개수 기준 내림차순으로 정렬하기
pivot = pd.pivot_table(df, index = ['Source', 'Destination'], values = 'Airline', aggfunc = 'count').sort_values(by='Airline', ascending=False)
#Airline 컬럼이 Air India이고, Price 컬럼이 7000 이상인 데이터를 필터링하기
df[(df['Airline'] == 'Air India') & (df['Price'] >= 7000)]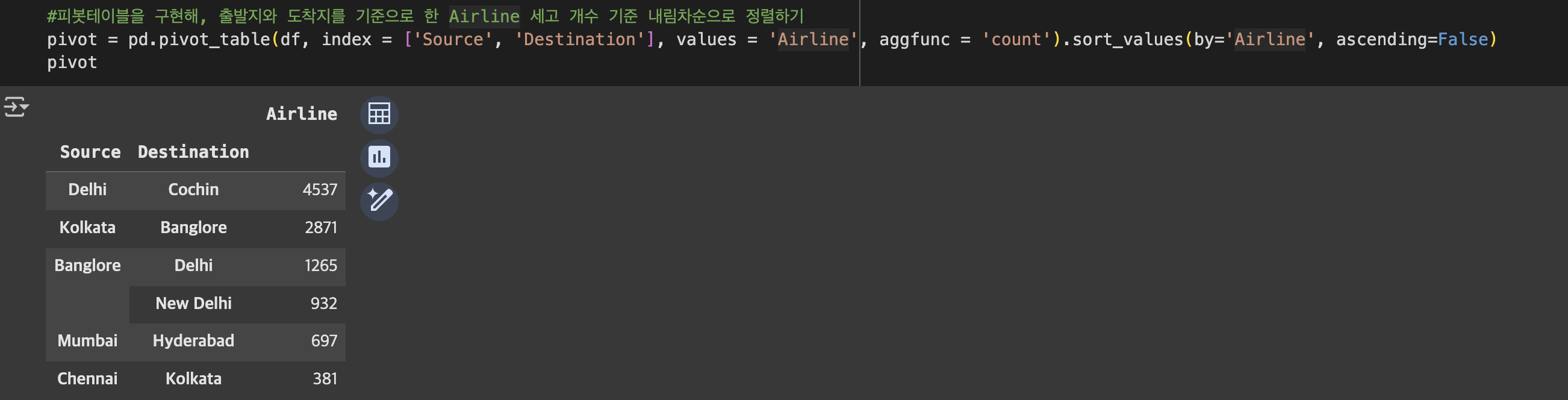

문제 유형: 도전
문제 5
import pandas as pd
from datetime import datetime
#Date_of_Journey 기준 수요일에 예약된 경우의 평균 가격 구하기
df['Date_of_Journey'] = pd.to_datetime(df['Date_of_Journey'])
df['Weekday'] = df['Date_of_Journey'].dt.weekday
Average_Price_of_Wednesday = df[df['Weekday'] == 2]['Price'].mean().round(2)
print(f'수요일로 예약된 경우의 평균 가격은 [{Average_Price_of_Wednesday}]입니다.')
(어렵다..)
rrule() 함수 써보려고는 했는데, 사용법이 아직도 감이 잘 안 와서 그냥 '이래도 되나..?' 하면서 풀었다.
문제 6
#도전 2. 조건에 맞는 데이터 추출하기4
import pandas as pd
from datetime import datetime
#Dep_Time 컬럼 기준으로 lambda 함수를 활용해 아침, 오후, 저녁, 밤 비행기로 Airline을 분류해 그 수를 집계하기
df['Dep_Time'] = pd.to_datetime(df['Dep_Time'])
df['Hour'] = df['Dep_Time'].dt.hour
df['Time_Range'] = df['Hour'].transform(lambda x: pd.cut(x, [0, 5, 12, 18, 24], labels=['Night', 'Morning', 'Afternoon', 'Evening']))
df.groupby('Time_Range')['Airline'].count()

[참고1] [Pandas] 판다스 Cut 함수로 데이터 구간 나누기(설명 및 예시)
[참고2] [파이썬 (Python) :: 핵심 함수편] Transform() 함수란?

왜 내일 주말이 아니지........
'[내배캠] 데이터분석 6기 > 본캠프 기록' 카테고리의 다른 글
| [본캠프 24일차] SQL 코드카타, 파이썬 코드카타, 기초 프로젝트 준비② (1) | 2025.03.21 |
|---|---|
| [본캠프 23일차] SQL 코드카타, 파이썬 코드카타, 기초 프로젝트 준비 (0) | 2025.03.20 |
| [본캠프 21일차] SQL 코드카타, 파이썬 코드카타, 파이썬 공부 (0) | 2025.03.19 |
| [본캠프 20일차] 파이썬 공부, 파이썬 코드카타, SQL 코드카타 (0) | 2025.03.17 |
| [본캠프 19일차] SQL 코드카타, QCC ②, 파이썬 코드카타, 파이썬 공부, 아티클 스터디 ④ (0) | 2025.03.14 |