
[본캠프 24일차] 부록: [chap 2] 기초 프로젝트 준비①
어제부터 주제를 정해서 기초 프로젝트 과제를 해나가고 있다. 어제도 하긴 했는데, 낡고 지친 관계로 어제 TIL에 해당 내용을 적지 못했다. 비주얼 코드 스튜디오와 씨름하기만도 지치고 바빠
maandoo.tistory.com

어제에 이어서(오늘은 월요일인데도 어제에 이어서라니... 흑) 오늘은 구매 건수에 따른 고객의 특성을 파악해보기로 한다.
구매 건수에 따른 고객군 분석하기
transactions 테이블의 기본적인 고객 데이터에 관한 정보 짚고 넘어가기
# 이전 데이터 분석으로 알아놓은 부분이지만 오늘 살펴볼 부분과 관련 있는 것들을 한 곳에 모아봄
# 구매 고객 수 세기
구매_회원_수 = tra['customer_id'].nunique() # transactions 테이블의 회원 수 집계
전체_회원_수 = cus['customer_id'].nunique() # customers 테이블의 회원 수 집계
print(f'전체 회원 수: {전체_회원_수}, 구매 회원 수: {구매_회원_수} 구매 회원이 차지하는 비율은 {(구매_회원_수/전체_회원_수)*100}%')
# 고객당 구매 건수(customer_id별로 거래일자가 등장한 횟수 집계)
purchase_cnt = pd.DataFrame(tra.groupby('customer_id')['t_dat'].count())- transactions 테이블은 2019년(2019-01-01~2019-12-31)의 거래 내역을 담은 데이터
- transactions 테이블에 집계된 고객 수는 458,235명 (이는 customers 테이블의 전체 회원 중 43.7%)
- transactions 테이블은 한 행이 [구매 고객 ID]+[구매 제품 ID]+[해당 제품의 가격] 이렇게 고객 한 명에, 제품 한 개 구매에 대한 정보가 담겨 있음
- ( = 즉, 하루에 여러 개의 제품을 구매했든, 여러 번의 구매를 했든 구매한 제품 내역이 한 행 한 행 기록됨)
- ( = 구매 건수: 2019년 동안 몇 개의 제품을 구매했는지(≠거래 횟수) )
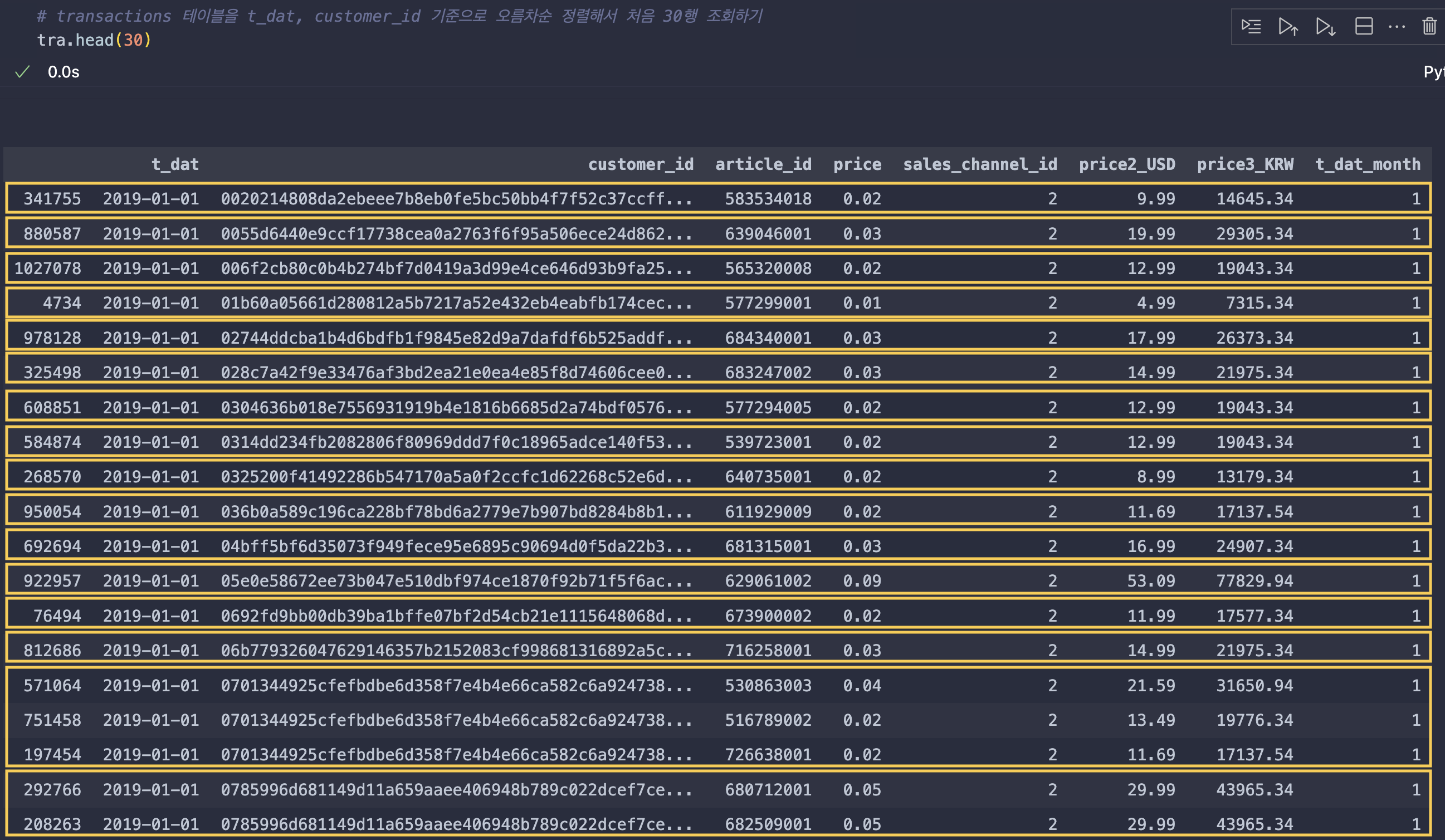
하나씩 살펴보다가 transactions 테이블이 가진 특성에 따라 구매 건수와 재구매율을 정확히 정의하고 넘어가야 할 필요성을 느끼게 됐다.
위의 transactions 테이블은 거래일자, 그리고 고객ID 기준으로 오름차순으로 정렬한 모습 중 일부다. 보다시피 날짜 순으로 정렬되고, 날짜가 동일할 경우 고객ID를 기준으로 정렬했다.
앞서 언급했듯이 transactions 테이블은 한 행이 어떤 고객이 어떤 제품 한 개를 구매했는지 담고 있다.
그래서 이 점에서 착안해서 처음에 구매 건수를 집계할 때에 customer_id를 기준으로 t_dat을(사실 t_dat이 굳이 아니어도 괜찮음) count()로 집계하면 해당 고객ID에 해당하는 행이 몇 행 있는지 집계해 구매 건수를 계산할 수 있다고 생각했으나,
위의 transactions 테이블에서 고객 아이디가 '0701344…' 해당하는 고객을 보면 2019년 1월 1일에 물건 3개를 구매함으로써 행이 3개 잡히는 모습을 볼 수 있다. 이렇게 되면 구매 건수는 해당 고객ID가 물건을 몇 개 구매했는지를 집계하고 있음을 알 수 있다.
이에 재구매율을 계산하려면 구매 건수를 사용할 수 없겠다는 판단이 들었다.
만약 어떤 이가 H&M에서 하루만 거래했음에도 품목 3개를 구매함으로써 구매 건수가 3으로 집계된 것을 가지고 재구매했다고 얘기할 수 없는 것은 당연하기 때문이다. 그래서 t_dat에 시간 데이터는 없는 관계로 customer_id를 기준으로 t_dat(이번엔 t_dat이어야 함)을 nunique()로 집계하면 재방문 횟수로 사용할 수 있겠다 싶었다. 이를 방문 횟수로 정의하여 해당 고객ID가 몇 번 H&M에서 물건을 구매하러 왔는지를 집계하기로 했다.

해당 고객의 총 구매 제품 수와 총 방문 횟수
# 구매 건수 집계 (구매 건수: 해당 고객이 2019년 동안 구매한 제품의 수)
trapt_buycnt = tra.pivot_table(index='customer_id', values='t_dat', aggfunc='count')
trapt_buycnt.rename(columns={'t_dat':'total_article_cnt'}, inplace=True)
# 방문 횟수 집계 (방문 횟수: 해당 고객이 2019년 동안 방문한 횟수) *거래일이 중복값 없이 집계
trapt_visitcnt = tra.pivot_table(index='customer_id', values='t_dat', aggfunc='nunique')
trapt_visitcnt.rename(columns={'t_dat':'visit_cnt'}, inplace=True)
trapt_cnt = pd.merge(trapt_buycnt, trapt_visitcnt, how='left', left_on='customer_id', right_on='customer_id')
- ['total_article_cnt']: 해당 customer_id가 2019년 동안 제품을 총 몇 개 샀는가
- ['visit_cnt']: 해당 customer_id가 2019년 동안 총 몇 번 우리 매장을/쇼핑몰을 방문했는가 (온/오프 구분 안 하고 집계)


#고객의 방문 횟수에 따른 해당 고객의 객단가(AOV) 계산하기
# 고객ID별, 거래일자별 총 소비금액 계산하기
amount_iddate = pd.DataFrame(tra_final.groupby(['customer_id', 't_dat'])['price3_KRW'].sum())
amount_iddate = amount_iddate.reset_index()
amount_iddate.rename(columns={'price3_KRW':'total_sum'}, inplace=True)
# 고객ID별 방문횟수 집계
visitcnt_id = pd.DataFrame(amount_iddate.groupby('customer_id')['t_dat'].nunique())
visitcnt_id = visitcnt_id.reset_index()
visitcnt_id.rename(columns={'t_dat':'visit_cnt'})
# 고객ID별 총 소비금액 계산하기
amount_id = pd.DataFrame(amount_iddate.groupby('customer_id')['total_sum'].sum())
amount_id = amount_id.reset_index()
# 고객ID별 객단가 계산 (총 소비금액 / 방문횟수)
aov_id = pd.merge(amount_id, visitcnt_id, how='left', left_on='customer_id', right_on='customer_id')
aov_id['AOV'] = aov_id['total_sum']/aov_id['t_dat']
...
.....
이제 저 테이블을 갖고 방문 횟수별로 피벗 테이블로 총 판매액, 고객 수, 일인 평균 소비 금액(총 판매액/고객 수), 객단가의 중앙값(..필요 없나? 잘 모르겠음) 등을 구매봤어야 하는데 너무 머리가 아파서 잠시 퍼져있었다.
그랬는데 오늘 오후에 고객 세그먼트에 있어서 자료 조사를 하면서 좀 더 방향을 잡아보려다가... 그냥 우선 자려고. 하.


'[내배캠] 데이터분석 6기 > 프로젝트 기록' 카테고리의 다른 글
| [본캠프 28일차] 부록: [chap 2] 기초 프로젝트 준비⑤ (0) | 2025.03.27 |
|---|---|
| [본캠프 27일차] 부록: [chap 2] 기초 프로젝트 준비④ (0) | 2025.03.26 |
| [본캠프 26일차] 부록: [chap 2] 기초 프로젝트 준비③ (0) | 2025.03.25 |
| [본캠프 24일차] 부록: [chap 2] 기초 프로젝트 준비① (0) | 2025.03.21 |