중꺾그마
(중요한 꺾여도 그냥 하는 마음)

사전캠프 TIL을 작성한 지 벌써 두 자릿수라니 시간은 빠.. 사실 빠르다고 생각되진 않는다. 사전캠프가 2월 14일 기준으로 6일(주말 미포함) 남았는데 그동안 나갈 진도나가자. 사실 오늘따라 일어날 때 피곤해서 좀처럼 잠에서 벗어나기 힘들었다. 늦게 잠들어서일지도, 적게 자서일지도, 혹은 운동 부족으로 체력이 떨어져서일지도, 짚히는 구석이 많다. 그런데 오늘은 피곤하다고 내 사정을 봐줘서 할 일이 줄어드는 것도 아니고 힘들든 어쩌든 할 일을 해서 할 일을 줄여나가는 수밖에 없다. 중요한 건 어쨌든 그냥 하는 마음. 꾸준히 나아가야겠지.
오늘 한 일은,
- SQL 공부
- 개인 퀘스트(달리기반) - [SQL 실전!] Lv3. 이용자의 포인트 조회하기
- SQLD 공부
- [SQLD 자격증 챌린지] 3주차
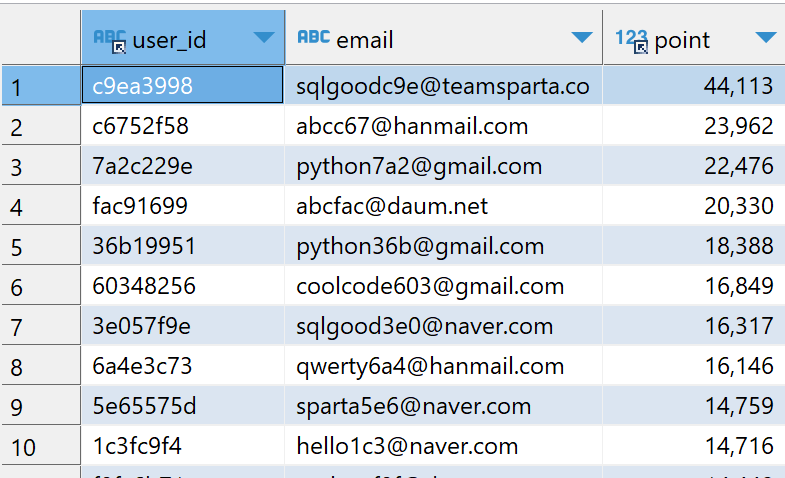
SQL 공부: 개인퀘스트(달리기반) - [SQL 실전!]
Lv3. 이용자의 포인트 조회하기
Q. 이용자별 획득 포인트를 각자에게 이메일로 보내려고 한다. 이를 위한 자료를 가공하여 다음과 같은 결과 테이블을 만드시오.
(단, users 테이블에는 있지만 point_users에는 없는 user는 포인트가 없으므로 0으로 처리하고, 포인트 기준으로 내림차순 정렬하시오)

SELECT u.user_id ,
u.email,
pu.point
FROM users u LEFT JOIN point_users pu ON u.user_id =pu.user_id
우선 users 테이블과 point_users 테이블을 JOIN으로 묶어줬다. 주어진 조건에서 users 테이블에만 데이터가 있더라고 조회되게 요구했으니 LEFT JOIN을 사용했다.
그리고 결과 테이블에서 보이는 user_id 컬럼, email 컬럼, point 컬럼을 조회하도록 불러준다.
이제 point에 NULL값이 뜨면 0으로 대체하여 데이터를 채우도록 해야 하는데, 음 기억이 안 나서 바로 구글을 켰다.
[참고] Ilhwanee, "MySQL에서 NULL을 치환하는 3가지 방법"
대충 "sql null 대체" 이런 식으로 검색했더니 SQL에서 NULL값을 다른 값으로 대체하는 방법들을 찾을 수 있었다. 그 중에서 IFNULL() 함수를 이용하여 NULL값일 경우 0으로 채우도록 작성했다.
- IFNULL(컬럼명, 'a') : 해당 컬럼에서 NULL값이 조회될 경우 a로 값을 입력해주세요
SELECT u.user_id ,
u.email,
IFNULL(pu.point, 0) point
FROM users u LEFT JOIN point_users pu ON u.user_id =pu.user_id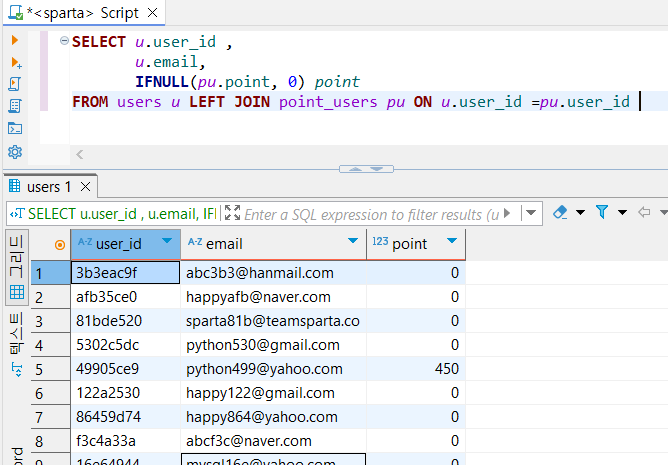
그러면 이젠 결과 테이블에서 NULL값이 아니라 0으로 대체해 입력한 것을 볼 수 있다.
SELECT u.user_id ,
u.email,
IFNULL(pu.point, 0) point
FROM users u LEFT JOIN point_users pu ON u.user_id =pu.user_id
ORDER BY 3 DESC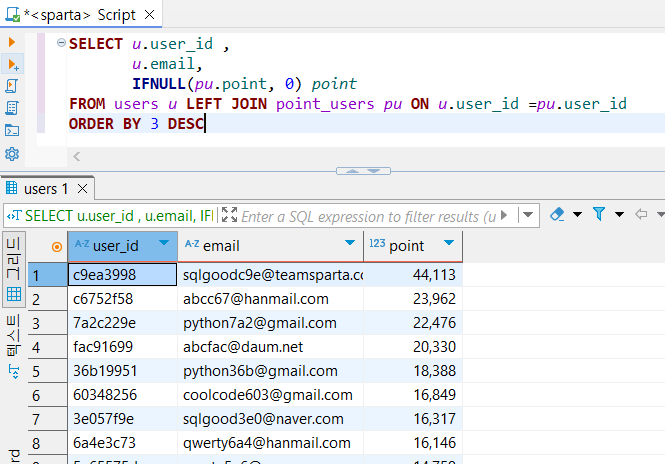
그리고 마지막으로 ORDER BY를 사용해 point 컬럼을 기준으로 내림차순 정렬을 해주면 쿼리 작성 끝~!!

SQLD 공부: [SQLD 자격증 챌린지] 수강하기
1️⃣엔터티 (Entity)
엔터티의 개념
- 엔터티 : 개체. 데이터베이스에서 레코드가 개체에 해당
- 엔터티와 인스턴스
- 엔터티가 데이터로 표현하고자 하는 하나의 테이블이라고 친다면, 인스턴스는 이 테이블에 들어가있는 각 데이터들(각 한 줄, 한 줄)을 지칭함 엔터티 = "인스턴스가 모인 집합"
엔터티 특징
- ①업무에서 필요로 하는 정보 엔터티는 업무에서 필요로 하는 정보들로 구성되어야 한다
- ②식별 가능 여부 인스턴스가 식별자에 의해 한 개씩만 존재하는지 검증해야 함
- ③인스턴스의 집합 엔터티 = 2개 이상의 인스턴스로 구성 (=> 인스턴스가 하나뿐이면 그건 엔터티 아님)
- ④업무 프로세스에 활용되어야 함
- ⑤속성을 포함해야 함 주식별자만 존재하고 일반 속성은 전혀 없는 경우 엔터티가 아님 (= 일반 속성 있어야 함!)
- ⑥관계의 존재 엔터티가 도출됨 = 해당 업무에서 어떠한 연관성을 갖고 다른 엔터티와의 연관성이 있음
( => 관계가 설정되지 않은 엔터티: 부적절한 엔터티 or 연결 관계를 아직 찾지 못한 것)
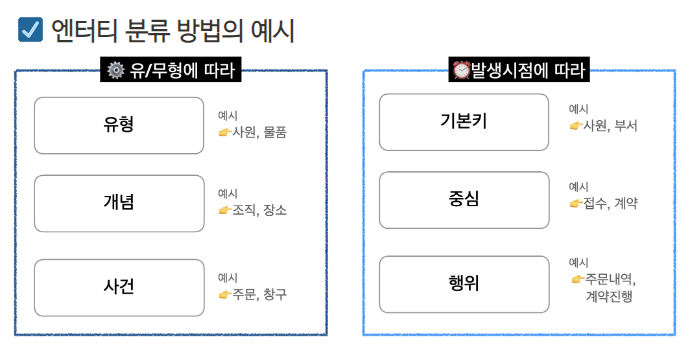
엔터티의 분류
- 유/무형에 따른 분류
- 유형 엔터티: 물리적 형태가 존재 ex)상품, 강사
- 개념 엔터티: 물리적 형태 X, 개념적인 정보 ex)학과, 코스닥 종목
- 사건 엔터티: 특정 이벤트에 종속됨, 수행에 따라 발생 ex)이벤트 응모, 주문
- 발생 시점에 따른 분류
- 기본/키 엔터티: 독립적인 생성 가능, 다른 엔터티의 부모 역할을 함 ex)고객, 상품
- 중심 엔터티: 기본 엔터티로부터 발생 ex)주문, 취소
- 행위 엔터티: 두 개 이상의 부모 엔터티로부터 발생 ex)주문내역, 취소내역
엔터티 이름 짓기 방식
- ①업무에서 사용하는 용어를 사용
- ②축약어(shortcut)를 사용하지 않음 짧은 게 좋긴 하나 너무 축약해선 안 됨. 의미가 온전히 드러나도록 작성
- ③단수 명사를 사용하고 띄어쓰기를 하지 않음
- ④모든 엔터티에서 유일한 이름이 부여되어야 함 엔터티 이름은 중복돼선 안 됨
- ⑤엔터티 생성 의미대로 이름을 부여해야 함
2️⃣속성 (Attribute)
속성의 개념
- 속성: 인스턴스가 가진 어떠한 성질(성격)
업무에서 필요로 하는 인스턴스로 관리하고자 하는 의미상 더 이상 분리되지 않는 최소의 데이터 단위 - 엔터티, 인스턴스, 속성, 속성값의 관계
- 한 개의 엔터티는 두 개 이상의 인스턴스의 집합이어야 함 ←
- 한 개의 엔터티는 두 개 이상의 속성으로 구성됨 ←
- 한 개의 속성은 한 개의 속성값을 가짐 ← 이 3가지 표현들이 선지로 자주 등장하니 잘 봐두기!!
- 속성 표기법
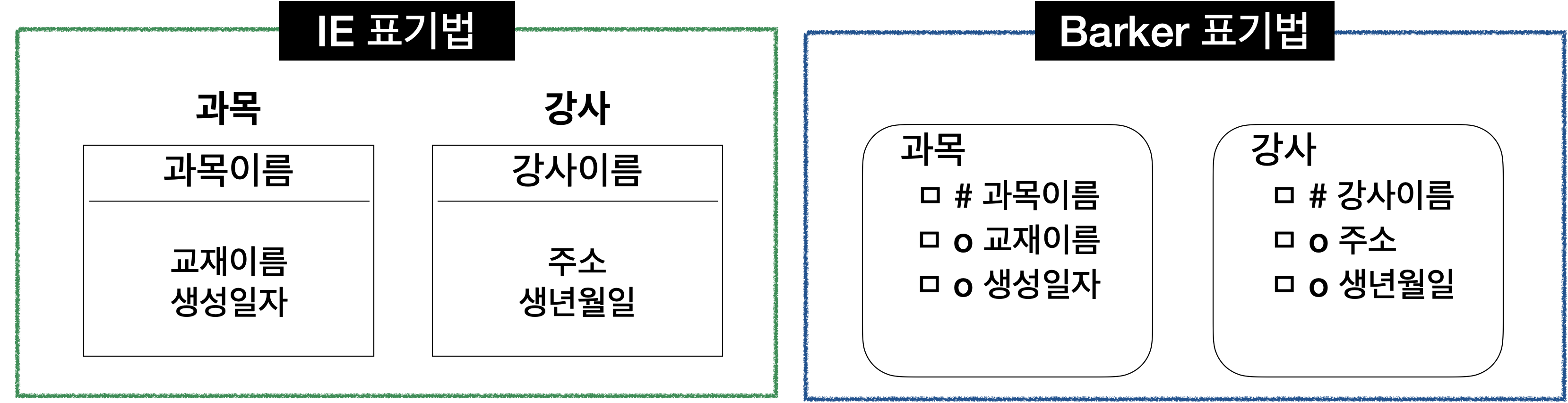
- 도메인
- 각 속성이 가질 수 있는 값의 범위
- 엔터티 내에서 속성에 대한 데이터 타입과 크기, 제약 사항 등을 지정함
속성의 특징
- ①속성은 업무에서 필요로 함 아무 요소나 모두 속성이 아님, 해당 업무에서 관리하고자 하는 정보여야 함
- ②의미상 더 이상 분리되지 않는 그 자체로 독립성을 유지 ( = 가장 작은 단위로 의미를 지님)
- ③엔터티를 설명하고 인스턴스의 구성요소임
- ④정규화 이론에 기반을 두고 정해진 주식별자에 함수적 종속성을 가져야 함
*함수적 종속성 = X값을 알면 Y값을 알 수 있고, X값에 따라 Y값이 변하면 Y는 X에 함수적 종속성을 갖는다 - ⑤하나의 속성은 한 개의 값만 가짐
=> 다중 값의 형태는 별도의 엔터티로 분류하여 관리
속성의 분류
- 속성의 특징에 따른 분류
- 기본 속성: 속성 중에서 가장 많은 종류를 차지 = '대부분이 기본 속성이다'
- 설계 속성: 데이터 모델링, 업무의 규칙화 등을 위해 새로 만들거나 변형하여 정의하는 속성
- 파생 속성: 다른 속성에 영향을 받아 발생하는 속성(=> 보통 계산된 값)
*데이터의 정합성(정확성)을 유지하기 위해서는 가급적 파생적 속성을 적게 정의하는 것이 좋음
- 엔터티 구성 방식에 따른 분류
- PK 속성: 엔터티를 식별할 수 있는 속성 주식별자로 사용하는 속성이 PK 속성
- FK 속성: 다른 엔터티와의 관계에 포함된 속성
- 일반 속성: PK 속성, FK 속성에 포함되지 않는 속성 = '대부분이 일반 속성이다'

+)
Q. 속성의 특징에 따른 분류로 옳지 않은 것은?
⑴ 설계 속성
⑵ 파생 속성
⑶ 일반 속성
⑷ 기본 속성
연습 문제 중에 속성의 분류에 대한 문제가 있었는데 풀면서 일반 속성이랑 기본 속성 헷갈리지 않도록 조심해야겠더라.
기본 속성 = 속성의 특징에 따른 분류!! / 일반 속성 = 엔터티 구성 방식에 따른 분류!!
속성의 이름 짓기 방식
- ①업무에서 사용하는 용어를 사용
- ②축약어(shortcut)를 사용하지 않음
- ③서술형보단 명사형을 사용
- ④수식어가 많이 붙지 않고 명확하게 의미를 파악하게끔 (= 명시적인 형태로 의미 전달하게끔)
- ⑤전체 데이터 모델에서 유일하게 작성해야 함
← 사실 현업이랑 좀 다르나 시험을 준비하는 입장이니 이렇게 알아두기
(∵ 데이터 정합성 유지와 반정규화 작업을 수행할 때 속성의 충돌을 해결하는 데 도움이 됨)
3️⃣관계 (Relationship)
관계의 개념
- 관계 : 상호 연관성 있는 상태
= "엔터티와 인스턴스 사이의 논리적인 연관성으로서 존재의 형태 행위로서 서로에게 연관성이 부여된 상태" - 페어링 : 엔터티 안에 인스턴스가 개별적으로 연결되어 있는 구조= 관계 = "페어링"
관계의 분류
- 존재에 의한 관계 : 소속/포함의 형태
- 행위에 의한 관계 : 행동/행위의 결과
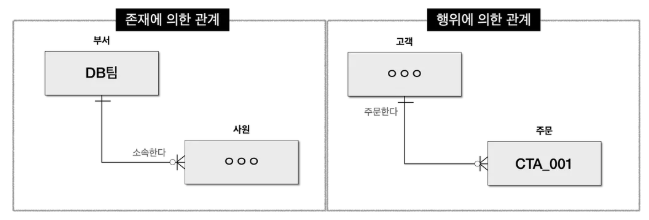
- ※UML(Unified Modeling Language, 통합 모델링 언어)의 '클래스 다이어그램'과 ERD 간 차이점
: ERD에서는 존재적 관계와 행위에 의한 관계를 구분하지 않고 표현했다면 클래스 다이어그램에서는 이를 구분하여 연관 및 의존 관계로 표현합니다 = 존재적 관계와 행위에 의한 관계를 구분하느냐의 차이 (ERD는 구분 안 해, 클래스~는 구분해)
관계의 표기법
- 관계명 : 엔터티가 관계에 참여하는 형태를 지칭, 각 관계는 2개의 관계명을 가짐
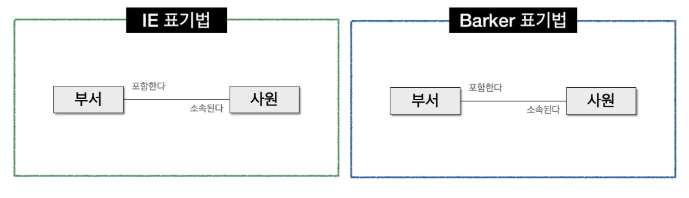
- 관계 표기법 : 개수와 식별/비식별 관계를 표현


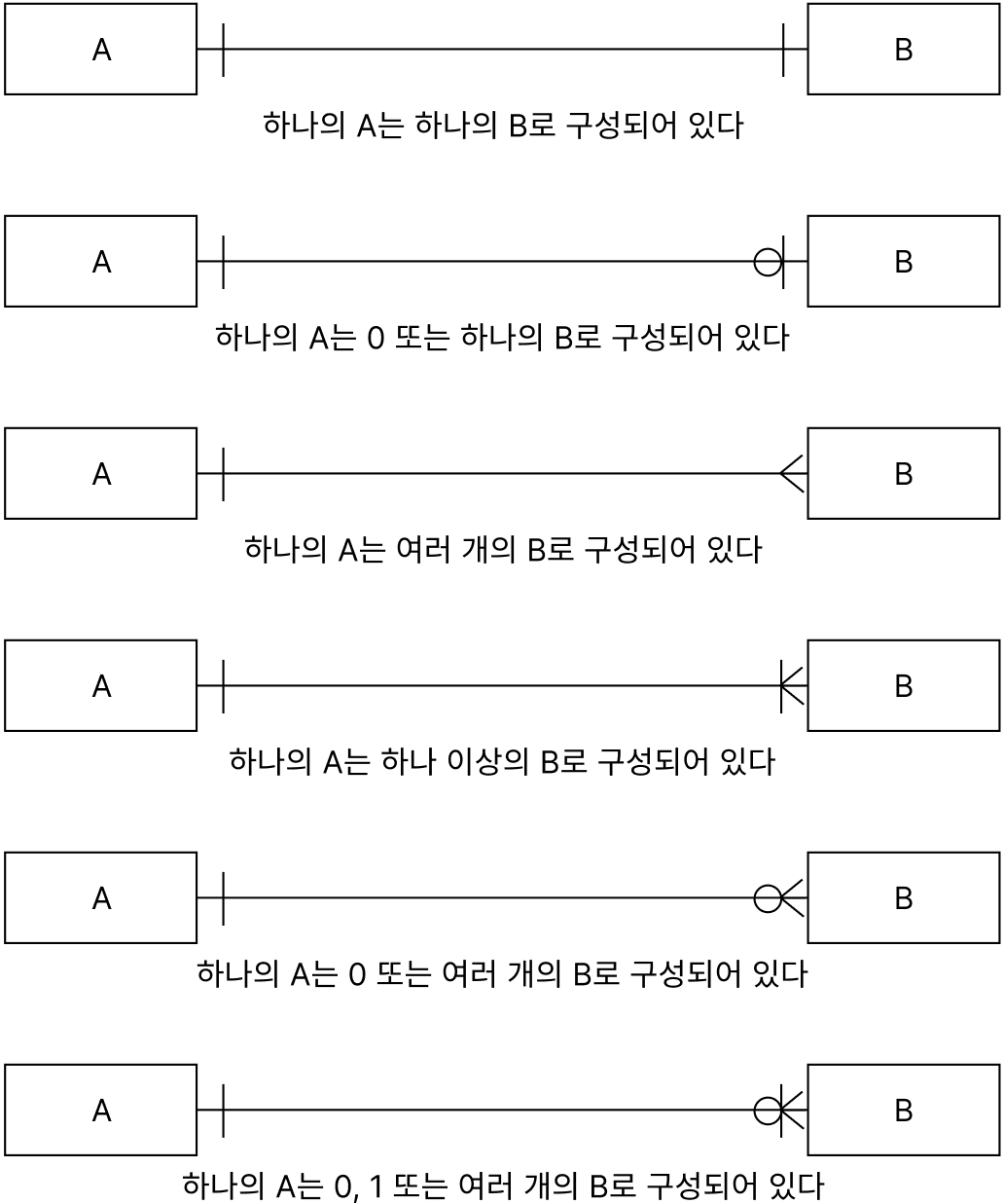
- 관계차수⭐ ⭐ ⭐ ⭐ ⭐ = 두 개의 엔터티 간 관계에서 참여자 수를 표현하는 것
- 1:1 관계 표시
- 관계에 참여하는 각 엔터티는 관계를 맺는 다른 엔터티에 대해 하나의 관계로 연결
- A Entity에 존재하는 데이터 1개와 관계되는 B Entity에 존재하는 데이터의 개수도 1개인 Entity 간의 관계
- ex) 유저와 프로필 간의 관계
= 유저도 하나의 프로필만 가질 수 있고, 프로필 역시 한 명의 유저에게만 대응
- 1:M(1:N) 관계 표시
- 관계에 참여하는 각 엔터티는 관계를 맺는 다른 엔터티에 하나 혹은 그 이상의 관계를 맺음
- 단, 이 방향은 한쪽 방향에만 해당되며 반대 방향은 오직 하나의 관계만 가짐
- ex) 댓글과 게시글
= 하나의 게시글에 한 개 혹은 여러 개의 댓글이 달릴 수 있으나, 그 댓글은 하나의 게시글에만 소속됨
- M:M(M:N) 관계 표시
- 1:M 관계가 양방향에서 모두 발생하는 경우
- ex) 좋아요 기능
= 하나의 게시글에 여러 유저들이 좋아요를 누를 수 있고, 한 명의 유저 역시 여러 게시글에 좋아요를 누를 수 있음
- 1:1 관계 표시
- 관계선택사양 = 해당 엔터티가 이 관계에 필수 사항인지 선택 사항인지를 표현

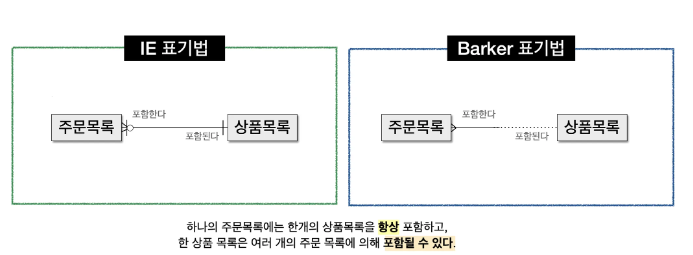
관계 정의 및 관계를 읽는 법
- 두 엔터티 간 관계 정의 시 체크리스트
- 두 엔터티 사이에는 관심 있는 연관 규칙이 존재하는지 여부
- 두 개의 엔터티 사이에 정보의 조합이 발생하는지 여부
- 업무 기술서, 장표에 관계 연결에 대한 규칙이 있는지 여부
- 업무 기술서, 장표에 관계 연결을 가능하게 하는 동사(Verb)가 있는지 여부
- 관계 읽기

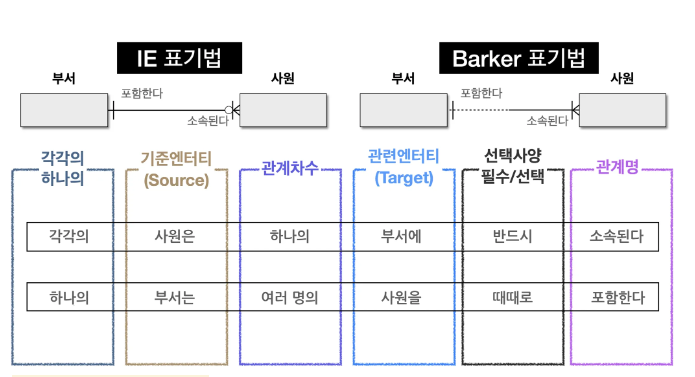
4️⃣식별자 (Identfier)
식별자의 개념
- 식별자 = 각각의 데이터를 구분해주는 속성
- 주식별자=PK 속성의 특징
- 유일성 : 주식별자에 의해 엔터티 내에서 모든 인스턴스들을 유일하게 구분
- 최소성 : 주식별자를 구성하는 속성의 수는 유일성을 만족하는 최소의 수가 되어야 함
- 불변성 : 한 번 특정 엔터티에 지정되면 그 식별자의 값은 변하지 않아야 함
- 존재성 : 주식별자가 지정되면 반드시 데이터 값이 존재해야 함
식별자의 분류

- 대표성 여부
- 주식별자 : 엔터티 내에서 각 인스턴스를 구분할 수 있는 구분자
- 보조 식별자 : 주식별자가 아니면 보조 식별자
- 스스로 생성 여부
- 내부 식별자 : 엔터티 내부에서 정의되는 식별자
- 외부 식별자 : 다른 엔터티로부터 받아오는 식별자
- 속성의 수
- 단일 식별자 : 하나의 속성으로 구성 대부분이 단일 식별자
- 복합 식별자 : 둘 이상의 속성으로 구성
- 대체 여부
- 본질 식별자 : 업무에 의해 만들어지는 식별자
- 인조 식별자 : 갖고 있는 데이터를 이용해 인위적으로 만든 식별자
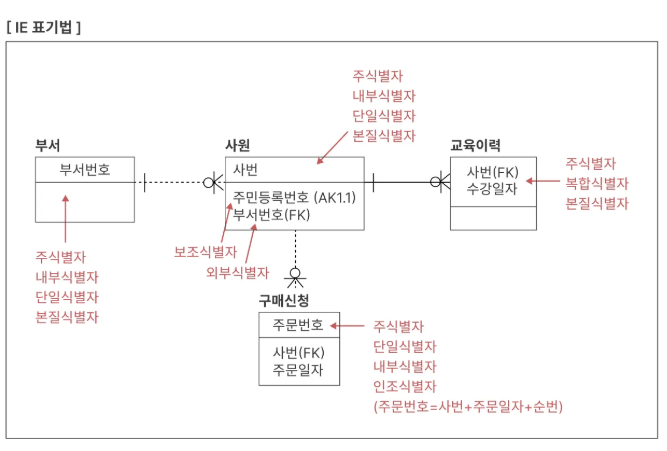
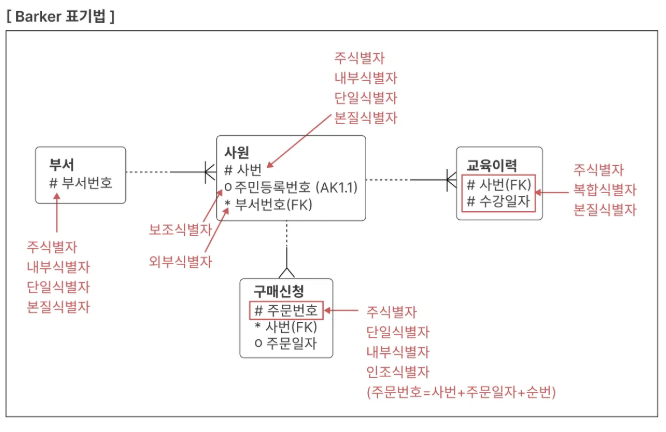
주식별자 도출 기준
- 해당 업무에서 자주 이용되는 속성으로 설정
- 명칭, 내역 등과 같이 특정한 이름으로 기술되는 것은 가능하면 주식별자로 사용하지 않음
보통은 일련 번호 혹은 특정한 코드를 생성하여 해결함 - 복합으로 주식별자를 구성하는 경우 너무 많은 속성이 포함되지 않도록 해야 함
새로운 인조 식별자를 생성하여 데이터 모델을 구성하는 것이 좋음
문장의 편리함과 성능을 위해서 과도한 복합키의 사용은 지양해야 함
식별자 관계와 비식별자 관계
- 식별자 관계와 비식별자 관계를 결정하는 요인
- 관계와 속성을 정의하고 주식별자를 결정하면 논리적인 관계에 의해 자연스럽게 외부식별자가 도출
- → 엔터티에 주식별자가 지정되고 엔터티 간 관계를 연결하면 부모 쪽의 주식별자를 자식 엔터티의 속성으로 보내게 됨
- ‼👀 이때 자식 엔터티에서 부모 엔터티로부터 받은 외부 식별자를 주식별자로 쓸 것인지 혹은 부모와 연결된 속성(Foreign Key)으로만 이용할 것인지 결정해야 함
- 식별자 관계 : 부모로부터 받은 식별자를 자식 엔터티의 주식별자로 이용 비어있는 값이 있으면 안 됨
- 비식별자 관계 : 부모 엔터티로부터 속성을 받았지만 자식 엔터티의 주식별자로 사용하지 않고 일반 속성으로만 사용
- 식별자 관계와 비식별자 관계 비교
- 식별자 관계
- 목적 : 강한 연결관계
- 자식 주식별자 영향 : 주식별자 구성에 포함
- 표기법 : 실선(IE) / 버티컬바 有(Barker)
- 연결 고려사항 ← 이 내용이 선지로 자주 등장!!
- 반드시 부모 엔터티에 종속
- 자식 주식별자 구성에 부모 엔터티의 주식별자 속성이 필요한 경우에 사용
- 상속 받은 주식별자 속성을 타 엔터티에 이전 필요
- 비식별자 관계
- 목적 : 약한 연결관계
- 자식 주식별자 영향 : 일반 속성에 포함
- 표기법 : 점선(IE) / 버티컬바 無(Barker)
- 연결 고려사항 ← 이 내용이 선지로 자주 등장!!
- 약한 종속 관계
- 자식 주식별자 구성을 독립적으로 구성할 경우에 사용
- 자식 주식별자 구성에 부모 주식별자 부분 필요
- 상속 받은 주식별자 속성을 다른 엔터티에 차단 필요
- 부모 쪽의 관계 참여가 선택 관계
- 식별자 관계

흐아... 대체 이론 얼마나 더 해야 하는 거예요?
같은 시간 동안 공부해도 시간 재서 문제 풀고, 채점해서 오답 맞추고 하는 게 더 재밌을 거 같다. 문제 풀고 싶어.. 이론 멈춰어...
그래도 오늘 컨디션 안 좋았어도 듣고자 하는 만큼은 강의 다 들어서 다행이다. 오늘은 일찍 자야지.
'[내배캠] 데이터분석 6기 > 사전캠프 기록' 카테고리의 다른 글
| [사전캠프 12일차] 아티클 스터디⑨, 파이썬 공부, SQLD 공부 (3) | 2025.02.10 |
|---|---|
| [사전캠프 11일차] 아티클 스터디⑧, SQL 공부, SQLD 공부 (0) | 2025.02.07 |
| [사전캠프 9일차] 아티클 스터디⑦, 파이썬 공부, SQLD 공부 (1) | 2025.02.05 |
| [사전캠프 8일차] 아티클 스터디⑥, SQLD 공부 (0) | 2025.02.04 |
| [사전캠프 7일차] 아티클 스터디⑤, SQL 공부 (0) | 2025.02.03 |