오늘은 사전캠프 종료까지 3일(오늘 포함)을 앞두고 있는 시점에서 저번에 1월이 끝나면서 점검했듯이 다시 점검해봤다.


그래도 8일 동안 열심히 했다.
아티클 스터디와 개인 퀘스트는 계획대로 하면 사전캠프 종료와 함께 다할 수 있겠고, ADsP는 아무래도 사전캠프가 끝나고 혼자서 들어야 할 것 같다.
그리고 SQLD 강의를 꽤 많이 듣긴 했어도 금요일까지 남은 분량들을 마저 다 들으려면 오늘도 어제만큼 열심히 들어야겠다.
그러면 오늘도 화이팅~!!

오늘 한 일은,
- 열 번째 아티클 스터디 진행하기
- SQL 공부
- [SQLD 자격증 챌린지] 9 ~ 12주차 수강
- 개인 퀘스트(달리기반) - [SQL 실전!] Lv6. 가장 많이 팔린 품목은?
아티클 스터디 ⑩: 데이터 분석으로 유저의 마음을 읽는 서비스가 되려면
오늘 읽은 아티클 :
데이터 분석, 유저의 마음을 읽는 서비스가 되려면 - 리디주식회사 RIDI Corporation
데이터 분석, 요즘 중요한 직무 역량이죠. 데이터라는 낯선 도구에 어떻게 접근할지 고민하는 직장인이 많을 텐데요. 데이터와 직관을 동시에 활용하는 의사결정 원칙으로 고객 친화적인 서비
ridicorp.com

오늘은 리디가 서비스를 운영하는 데 있어 데이터를 활용할 때 중요하게 여기는 점을 다룬 글을 읽었다. 그 중에서도 리디의 원칙인 리디 코드 중 의사결정에 대한 원칙 중에 "데이터와 직관을 동시에 사용한다"는 부분이 인상적이다. 사실 데이터를 분석할 때 객관적이기 위해 분명히 노력할 테지만 그럼에도 개인의 주관이 반영되는 건 당연하다. 그렇기에 그 부분 역시 직관을 키움으로써 그 부분을 보완하는 걸 넘어 적극적으로 활용하고자 하는 태도를 느꼈다.
그래서 이런 직관을 잘 활용하기 위해 리디가 제시한 직관을 키우는 방법은 프로젝트의 환경을 둘러싼 전체적인 맥락을 이해하기 위해 산업 동향을 이해하고 또 고객의 소리를 학습하는 일이다. 관련 지식을 쌓고 또 관찰을 통해서 직관을 키울 수 있다는 의미다. 데이터를 어떤 회사든, 어떤 데이터 분석 능력을 갖춘 이들이든 다룰 수 있다면 이런 상황에서 차별적인 접근을 하기 위해선 나만의 관점, 나만의 직관과 결합할 때 가능한 일이라고 생각이 들었다. 그래서 직관을 키우라는 말이 내겐 데이터 분석에 치중하다가 그에 잡아먹히지 않게끔 균형을 잡을 수 있는 힘을 기르라는 말로 들렸다. 직관과 데이터 분석을 적절하게 잘 이용한 사례는 뭐가 있을지 궁금해졌다.
SQLD 공부: [SQLD 자격증 챌린지] 수강하기
JOIN
JOIN 개요
- JOIN : 두 개 이상의 테이블을 연결 또는 결합하여 데이터를 출력하는 것
- 행들은 기본키(PK)나 외래키(FK) 값의 관계 의해서 JOIN이 성립
- FROM 절에 여러 테이블을 나열하여 JOIN을 할 수 있음
- EQUI JOIN (등가 조인)
- 두 테이블 간에 칼럼의 값들이 서로 같은 경우 두 데이터를 하나의 데이터로 합치는 JOIN
- JOIN의 조건은 WHERE 절에 = 연산자를 사용하여 표현
- Non EQUI JOIN (비등가 조인)
- 두 개의 테이블 간에 칼럼들이 서로 정확하게 일치하는 것이 아닌 특정 범위 내에 있는 경우 JOIN을 하고자 할 때 사용
일반적인 상황은 아니고 이게 가능하려면 애초에 테이블 설계부터 잘해야 함 - = 연산자가 아닌 다른 (BETWEEN, >, >=, <, <= ) 연산자들을 사용
- LIKE 연산으로 다른 테이블의 값을 이용하여 JOIN을 나타낼 수 있음
- 두 개의 테이블 간에 칼럼들이 서로 정확하게 일치하는 것이 아닌 특정 범위 내에 있는 경우 JOIN을 하고자 할 때 사용
- 3개 이상의 테이블 JOIN
- 3개 이상의 테이블을 JOIN을 할 때는 FROM 절에 JOIN 하고자 하는 테이블을 차례대로 작성하면 됨
- JOIN은 항상 두 개의 테이블에서 일어남
표준 JOIN
일반 집합 연산자
- UNION 연산
- 합집합 중복 없음
- 공통 교집합의 중복을 없애기 위한 사전 작업으로 시스템의 부하를 주는 정렬 작업이 발생
- UNION ALL 공통 집합을 중복해서 그대로 보여줌
- INTERSECTION 연산
- 교집합
- DIFFRENCE 연산
- 차집합
- 오라클에선 MINUS로 사용
- PRODUCT 연산
- 곱집합
- CARTESIAN PRODUCT(데카르트의 곱) 현업에서 거의 안 씀
- 집합 연산자 주의사항
- 두 집합의 칼럼 수가 일치해야
- 두 집합의 칼럼 순서가 일치해야
- 두 집합의 각 칼럼의 데이터 타입이 일치해야
- 각 칼럼의 사이즈는 달라도 됨
순수 관계 연산자
- SELECT 연산
- SELECT 문에서는 WHERE 절로 표현 가능
- 특정 행에 대한 부분 집합 SELECT절과 키워드는 같으나 동작은 다름
- PROJECT 연산
- 특정 열에 대한 부분 집합
- JOIN 연산
- DIVIDE 연산
- 현재는 SQL문으로 구현되어 있지 않음
대표적인 JOIN의 6가지 방식
- INNER JOIN
- 조인 중에서 가장 많이 사용
- JOIN 조건에서 일치하는(동일한 값이 있는) 행만 반환
- 반드시 USING 조건절이나 ON 조건절을 사용해줘야 함
- INNER 키워드는 생략 가능 그냥 JOIN만 적어줘도 INNER JOIN으로 동작함
- NATURAL JOIN
- 동일한 이름을 갖는 모든 칼럼들에 대해 자동으로 EQUI JOIN을 수행 일반적으로 많이 쓰는 JOIN은 아님
- USING 조건절
- 같은 칼럼명일 때 JOIN하려는 칼럼을 선택
- USING 조건절은 괄호 없으면 에러가 발생
- ON 조건절
- 칼럼명이 다르더라도 JOIN 조건을 사용할 수 있음
- WHERE절과 충돌 없이 사용할 수 있음
- 세 개 이상의 테이블을 JOIN을 하려고 할 때는 ON 조건절 다음에 JOIN 을 중첩적으로 명시
- CROSS JOIN
- 두 테이블 간에 일어날 수 있는 모든 조합의 결과는 M*N 건의 데이터 조합이 발생
- CARTESIAN PRODUCT 또는 CROSS PRODUCT 와 같은 표현으로도 불림
- OUTER JOIN
- JOIN 조건에서 동일한 값이 없는 데이터도 반환할 때 사용
- 기준이 되는 테이블에 따라 LEFT OUTER JOIN / RIGHT OUTER JOIN 으로 나뉨
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN 합집합으로 처리한 결과와 동일
서브쿼리
서브쿼리의 개념
- 하나의 쿼리 안에 다른 작은 쿼리를 포함시키는 것
- 서브쿼리는 주요 쿼리의 일부로 사용돼 조건을 만족시키거나 값을 가져올 때 유용
- 서브쿼리는 주인공 쿼리를 도와주는 작은 도우미 쿼리
- 데이터베이스에서 더 복잡한 정보를 가져오거나 원하는 조건을 충족시키기 위해 사용되는 도구
- GROUP BY절에서 사용 불가
서브쿼리의 분류
- 동작 방식에 따른 분류 : ①연관 서브쿼리, ②비연관 서브쿼리
- 연관 서브쿼리
- 서브쿼리의 값을 결정할 때 메인쿼리에 의존하는 것
- EXISTS 서브쿼리 : 항상 연관 서브쿼리로 사용. 만족하는 1건만 찾으면 추가적인 검색을 진행하지 않음
- 비연관 서브쿼리
- 메인쿼리의 어떤 것도 참조하지 않고 단독으로 사용
- 연관 서브쿼리
- 반환 형태에 따른 서브쿼리 : ①단일행 서브쿼리, ②다중행 서브쿼리, ③다중칼럼 서브쿼리
- 단일행 서브쿼리
- 서브쿼리의 결과가 0건 혹은 1건인 SQL문
- 서브쿼리가 단일행 비교 연산자(=, <, <=, >, >=, <>)와 함께 사용할 때는 서브쿼리의 결과 건수가 반드시 1건 이하
- 다중행 서브쿼리
- 서브 쿼리의 결과가 2건 이상인 SELECT문이 서브쿼리로 존재하는 것
- 반드시 다중행 비교 연산자(IN, ALL, ANY, EXISTS 등)와 함께 사용해야 함
- IN (서브쿼리) : 서브쿼리 결과에 존재하는 임의의 값과 동일
- ALL (서브쿼리) : 서브쿼리 결과에 존재하는 모든 값을 만족
- ANY (서브쿼리) / SOME (서브쿼리) : 서브쿼리 결과에 존재하는 어느 하나의 값이라도 만족
- EXISTS (서브쿼리) : 서브쿼리 결과를 만족하는 값이 존재하는지 여부를 확인
- 다중칼럼 서브쿼리
- 서브쿼리의 결과로 여러 개의 칼럼이 반환
- 단일행 서브쿼리
위치별 서브쿼리
- SELECT 절에 위치한 서브쿼리를 스칼라 서브쿼리
- 하나의 행과 하나의 칼럼(1 Row - 1 Column)만을 반환
- FROM 절에 위치한 서브쿼리를 인라인뷰 서브쿼리
- 마치 실행 시에 동적으로 생성된 테이블인 것처럼 사용할 수 있음
뷰(VIEW)
- 뷰 : 데이터베이스에서 저장된 정보를 좀 더 편리하게 보여주기 위해 사용되는 가상의 테이블
- 실제 데이터는 뷰를 구성하는 테이블에 담겨 있지만 마치 테이블처럼 사용할 수 있음
- 뷰는 테이블뿐만 아니라 다른 뷰를 참조해 새로운 뷰를 만들어 사용할 수 있음
- 뷰 이름은 ‘V_’로 시작하는 게 좋음
- 뷰 사용의 장점
- 독립성 : 테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 됨
- 편리성 : 복잡한 질의를 뷰로 생성함으로써 관련 질의를 단순하게 작성할 수 있음
- 보안성 : 숨기고 싶은 정보가 존재한다면, 뷰를 생성할 때 해당 칼럼을 빼고 생성함으로써 사용자에게 정보를 감출 수 있음
그룹 함수
ROLLUP 함수
- 칼럼으로 그룹을 만든 후 각 칼럼의 중간 합계를 만들기 위해 사용하는 함수
- ROLLUP 함수의 결과는 N + 1개의 합계가 생성
- 여기서 +1 은 그룹화된 칼럼들의 전체 합계를 의미
- 인수의 순서가 바뀌게 되면 수행 결과도 바뀜
CUBE 함수
- 그룹화된 데이터의 모든 가능한 조합에 대해 합계를 계산
- 칼럼의 순서가 바뀌어도 정렬되는 순서는 바뀌지만 데이터의 결과는 동일
- ROLLUP 함수에 비해서 시스템의 연산 대상이 많은 것이 특징
GROUPING SETS
- ROLLUP()과 CUBE()와 비슷한 결과를 얻을 수 있지만 좀 더 명시적으로 원하는 그룹 수준을 정할 수 있음
윈도우 함수
(여기부턴 이제 일일이 적는 것보다 실습 한번 해보고, 그냥 필요하면 그때그때 구글링하는 게 낫겠다 싶어짐)

(이 다음으로도 무지하게 강의를 들었다고 한다..)
SQL 과제 : 개인 퀘스트(달리기반) - [SQL 실전!]
Lv6. 가장 많이 팔린 품목은?
다음과 같이 3개의 테이블이 있다.
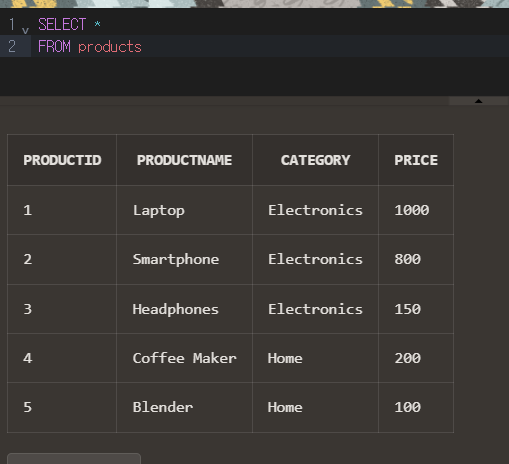
products 테이블
| ProductID | ProductName | Category | Price |
| 1 | Laptop | Electronics | 1000 |
| 2 | Smartphone | Electronics | 800 |
| 3 | Headphones | Electronics | 150 |
| 4 | Coffee Maker | Home | 200 |
| 5 | Blender | Home | 100 |
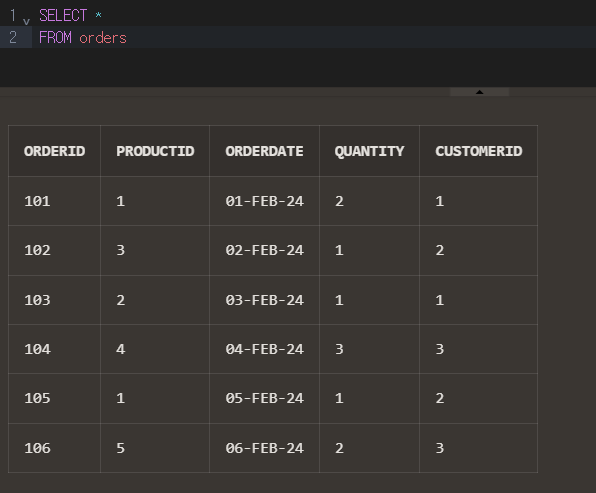
orders 테이블
| OrderID | ProductID | OrderDate | Quantity | CustomerID |
| 101 | 1 | 2024-02-01 | 2 | 1 |
| 102 | 3 | 2024-02-02 | 1 | 2 |
| 103 | 2 | 2024-02-03 | 1 | 1 |
| 104 | 4 | 2024-02-04 | 3 | 3 |
| 105 | 1 | 2024-02-05 | 1 | 2 |
| 106 | 5 | 2024-02-06 | 2 | 3 |
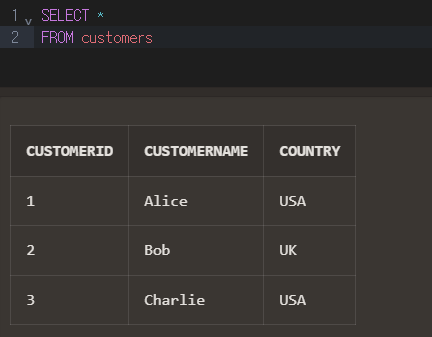
customers 테이블
| CustomerID | CustomerName | Country |
| 1 | Alice | USA |
| 2 | Bob | UK |
| 3 | Charlie | USA |
Q1. 각 고객이 구매한 모든 제품의 총 금액을 계산하고, 고객이름, 총 구매 금액, 주문 수를 출력하는 쿼리 작성하기
SELECT SUM(p.Price*o.Quantity) OVER (PARTITION BY o.CustomerID) TotalAmount,
o.CustomerID,
COUNT(*) OVER (PARTITION BY o.CustomerID) OrderCount
FROM products p JOIN orders o ON p.ProductID = o.ProductID우선 고객별로 구매한 모든 제품의 총 금액을 계산하기 위해 products 테이블과 orders 테이블을 JOIN한다.
그리고 SUM() OVER를 이용해서 고객별로 총 금액(제품 가격*제품 수량을 모두 합한 값)을 구하는 쿼리를 작성하고서 TotalAmount라고 별명을 붙였다.
그리고 후에 고객 이름을 가져오기 위해 customers 테이블과 JOIN 하기 위해서 CustomerID를 추가했고,
또 주문 수 역시 지금 한번에 계산해야 할 것 같아서 COUNT() OVER를 사용해 고객별 주문 수를 구하는 쿼리를 작성했다.
그리고 이 쿼리들을 서브쿼리로 묶고 customers 테이블과 JOIN 하며 쿼리를 마저 다음과 같이 작성했다.
SELECT c.CustomerName,
a.TotalAmount,
a.OrderCount
FROM customers c JOIN
(
SELECT SUM(p.Price*o.Quantity) OVER (PARTITION BY o.CustomerID) TotalAmount,
o.CustomerID,
COUNT(*) OVER (PARTITION BY o.CustomerID) OrderCount
FROM products p JOIN orders o ON p.ProductID = o.ProductID
) a ON c.CustomerID = a.CustomerID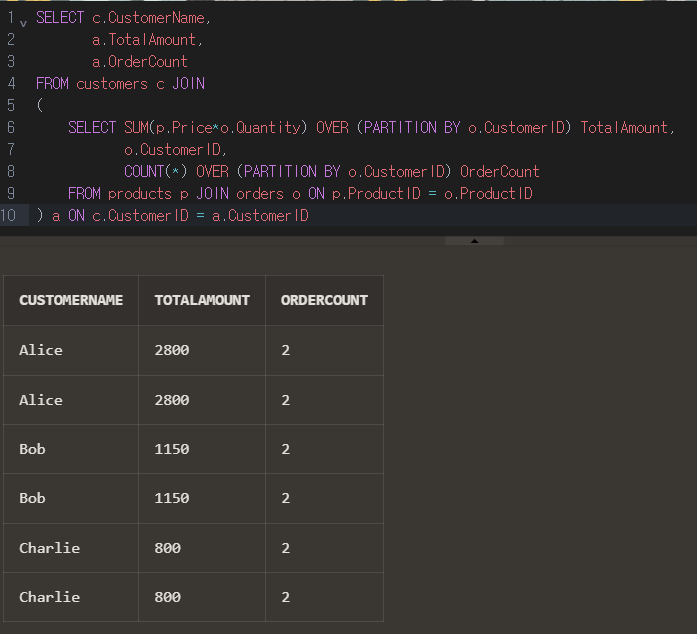
이렇게까지 작성하니 문제 없이 돌아가서 결과 테이블이 나오긴 하는데 데이터가 두 줄씩 나온다.
[참고] [Oracle] 데이터 중복 제거 방법 (DISTINCT, GROUP BY)
이리저리 헤매다가 발견한 이 블로그 글을 보고 '아!!!! DISTINCT!!!!!!' 속으로 외치면서 쿼리에 DISTINCT를 추가함으로써 쿼리 작성을 을 완료했다.
SELECT DISTINCT
c.CustomerName,
a.TotalAmount,
a.OrderCount
FROM customers c JOIN
(
SELECT SUM(p.Price*o.Quantity) OVER (PARTITION BY o.CustomerID) TotalAmount,
o.CustomerID,
COUNT(*) OVER (PARTITION BY o.CustomerID) OrderCount
FROM products p JOIN orders o ON p.ProductID = o.ProductID
) a ON c.CustomerID = a.CustomerID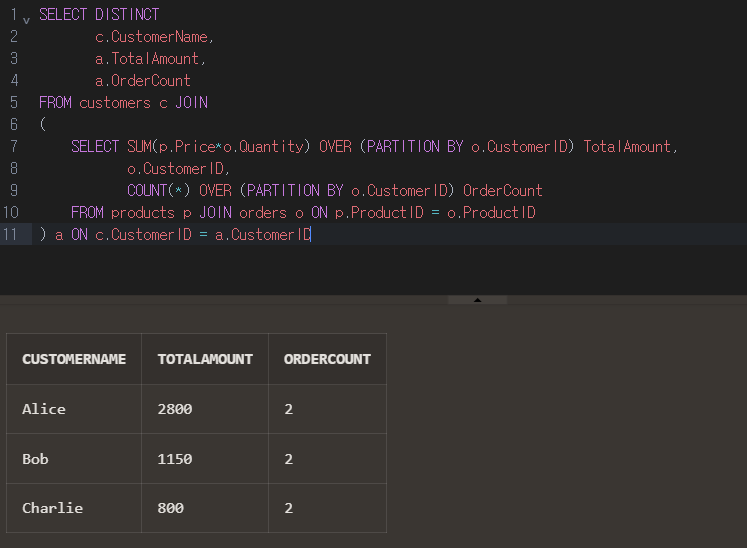
Q2. 제품 카테고리별로 가장 많이 팔린 제품의 이름과 총 판매량을 조회하는 쿼리 작성하기
SELECT DISTINCT
p.Category,
p.ProductName,
SUM(o.Quantity) OVER (PARTITION BY o.ProductID) TotalSold
FROM products p LEFT JOIN orders o ON p.ProductID = o.ProductID우선 products 테이블과 orders 테이블을 JOIN 해서 카테고리와 제품명, 그리고 제품별 총 판매량을 구하는 쿼리를 작성했다.
총 판매량은 SUM() OVER를 이용해서 제품 ID별로 수량의 합을 구하도록 하고 TotalSold라는 별명을 주었다.
원래는 여기서 바로 RANK() OVER도 사용하려고 했는데 TotalSold를 사용할 수 없어서 이 상태를 서브쿼리로 묶었다.
SELECT a.Category,
a.ProductName,
a.TotalSold,
RANK() OVER (PARTITION BY a.Category ORDER BY a.TotalSold DESC) Rank
FROM
(
SELECT DISTINCT
p.Category,
p.ProductName,
SUM(o.Quantity) OVER (PARTITION BY o.ProductID) TotalSold
FROM products p LEFT JOIN orders o ON p.ProductID = o.ProductID
) a그래서 서브쿼리로 묶고서 RANK() OVER를 이용해 카테고리별로 총 판매량에 따른 순위를 매겨줬다.
SELECT b.Category,
b.ProductName Top_Product,
b.TotalSold
FROM
(
SELECT a.Category,
a.ProductName,
a.TotalSold,
RANK() OVER (PARTITION BY a.Category ORDER BY a.TotalSold DESC) Rank
FROM
(
SELECT DISTINCT
p.Category,
p.ProductName,
SUM(o.Quantity) OVER (PARTITION BY o.ProductID) TotalSold
FROM products p LEFT JOIN orders o ON p.ProductID = o.ProductID
) a
) b
WHERE b.Rank = 1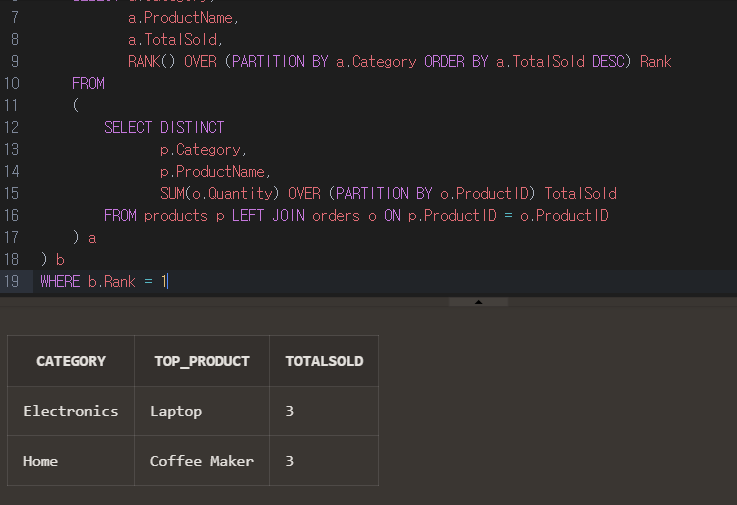
그리고 위의 부분을 또 서브쿼리로 묶고서 마지막 결과 테이블로 카테고리별 총 판매량 1위의 제품명과 총 판매량만 조회되게 쿼리를 작성했다.
그러면 결과 테이블은 요구한 대로 나오는데 사실 서브쿼리를 너무 많이 쓴 것 아닌가 싶긴 하다. 더 짧게 쓸 수 있는 방법이 없을까.
아무튼, 오늘도 과제를 했다..! (마참내)

이제 그만 자야겠어. 하하.
'[내배캠] 데이터분석 6기 > 사전캠프 기록' 카테고리의 다른 글
| [사전캠프 16일차] 아티클 스터디⑪, SQL 과제, SQLD 공부 (0) | 2025.02.14 |
|---|---|
| [사전캠프 15일차] 파이썬 과제, SQLD 공부 (0) | 2025.02.13 |
| [사전캠프 13일차] SQLD 공부, SQL 과제 (0) | 2025.02.11 |
| [사전캠프 12일차] 아티클 스터디⑨, 파이썬 공부, SQLD 공부 (0) | 2025.02.10 |
| [사전캠프 11일차] 아티클 스터디⑧, SQL 공부, SQLD 공부 (0) | 2025.02.07 |