오늘은 사전캠프 마지막 날

오늘 한 일은,
- 마지막 아티클 스터디 진행하기
- SQL 공부
- 개인 퀘스트(달리기반) - [SQL 실전!] Lv7. 예산이 가장 큰 프로젝트는?
- [SQLD 자격증 챌린지] 모의고사 풀기
- [SQLD 자격증 챌린지] 14주차 수강하기
아티클 스터디 ⑪: 데이터를 쉽게 찾고 잘 활용할 수 있는 기반을 만드는, 토스 Data Analytics Engineer
오늘 읽은 아티클 :
토스의 데이터를 쉽게 찾고 잘 활용할 수 있는 기반을 만드는, Data Analytics Engineer
데이터 활용을 깊게 고민하고 더 나은 데이터 환경을 만들기 위한 노력을 하는 토스 Data Analytics Engineer 분들의 이야기를 들어 보았어요.
toss.im
오늘은 토스의 DAE분들의 인터뷰를 읽으며 현업에서 어떤 식으로 업무를 바라보고 업무를 수행하는지를 알 수 있었다. 읽으면서 내일배움캠프를 통해 나는 어떤 경험을 쌓기 위해 노력하고 실행해야 할까에 대해 고민하게 됐다. 본캠프에선 팀 프로젝트를 진행하게 될 텐데 그 과정 속에서 나는 무엇을 염두에 둬야 할 때 마케터로서 고민해야 할 지점들은 무엇일까 생각했다. 아무래도 그를 알기 위해선 ①직접 마케터로 일하면서 체득하거나 ②현업 마케터들이 한 고민들을 보거나 하는 2가지 방법이 있다. 그래서 내배캠 기간 동안 ②번의 방법을 실천하기 위해서 어떤 창구가 있을지 찾아봐야겠다. 매주 관심 산업에 있는 마케터가 쓴 책이나 데이터 분석을 마케터 관점에서 담은 책을 일주일에 한 권씩 읽는 것으로 해야 할까?
SQL 과제 : 개인 퀘스트(달리기반) - [SQL 실전!]
Lv7. 예산이 가장 큰 프로젝트는?
Employees 테이블 :
| EmployeeID | Name | Department | Salary |
| 1 | Alice | HR | 5000 |
| 2 | Bob | IT | 7000 |
| 3 | Charlie | IT | 6000 |
| 4 | David | HR | 4500 |
| 5 | Eve | Sales | 5500 |
| 6 | Frank | IT | 7200 |
Projects 테이블 :
| ProjectID | ProjectName | Budget |
| 101 | Alpha | 10000 |
| 102 | Beta | 15000 |
| 103 | Gamma | 12000 |
| 104 | Delta | 8000 |
EmployeeProjects 테이블 :
| EmployeeID | ProjectID |
| 1 | 101 |
| 2 | 101 |
| 3 | 102 |
| 4 | 103 |
| 5 | 104 |
| 6 | 102 |
| 6 | 103 |
Q1. 각 직원이 속한 부서에서 가장 높은 월급을 받는 직원들만 포함한 결과를 조회하기
(결과 테이블에 직원의 이름, 부서, 월급이 포함되어야 함)
SELECT Name,
Department,
MAX(Salary)
FROM employees
GROUP BY Department; ---이렇게 적었는데 GROUP BY 표현이 아니라고 에러 뜸처음엔 이렇게 적었는데 에러가 떴다. 사실 아직도 이게 왜 안 된다는 건지 이해하지 못함..
SELECT Name,
Department,
MAX(Salary) OVER (PARTITION BY Department) MaxSalary
FROM employees
WHERE Salary = MaxSalary; ---이번엔 MaxSalary가 유효하지 않은 식별자라고 에러 뜸두 번째 시도는 이것이다. 식별자의 문제래서 다음과 같이 고쳤다.
SELECT a.Name,
a.Department,
a.Salary
FROM
(
SELECT Name,
Department,
Salary,
MAX(Salary) OVER (PARTITION BY Department) MaxSalary
FROM employees
) a
WHERE a.Salary = a.MaxSalary;
그랬더니 이렇게 원하는 대로 결과테이블이 출력됐다.
Q2. 직원이 참여한 프로젝트 중 예산이 10,000 이상인 프로젝트만 조회하기
(결과 테이블에는 직원 이름, 프로젝트 이름, 프로젝트 예산이 포함되어야 함)
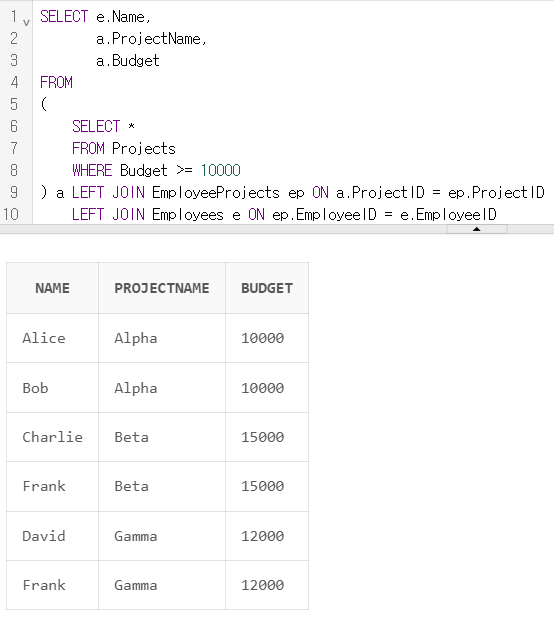
SELECT e.Name,
a.ProjectName,
a.Budget
FROM
(
SELECT *
FROM Projects
WHERE Budget >= 10000
) a LEFT JOIN EmployeeProjects ep ON a.ProjectID = ep.ProjectID
LEFT JOIN Employees e ON ep.EmployeeID = e.EmployeeID
ORDER BY a.ProjectName이번엔 에러 뜨는 일 없이 작성했다.
우선 문제에서 주어진 대로 예산이 10,000 이상인 프로젝트만 Projects 테이블에서 조회했다.
그리고 이 테이블을 서브쿼리 a로 묶어서 EmployeeProjects 테이블과 JOIN 하고, 또 거기에 Employees 테이블까지 JOIN 했다.
이 상태에서 결과 테이블에 요구한 컬럼들인 직원 이름, 프로젝트 이름, 프로젝트 예산을 SELECT 절에 적고서,
마지막으로 ORDER BY 절을 추가해서 프로젝트 순으로 결과 테이블에 정렬되도록 했다.
SQLD 공부: [SQLD 자격증 챌린지] 수강하기
우선 14주차 강의는 모의고사 문제풀이라서 수강하기 전에 모의고사를 풀었다.
첫 SQLD 모의고사!
SQLD는 50문제를 90분 안에 풀면 된다. 근데 풀다보니 시간이 문제가 아니라 내 머리가 문제..
찍는 문제가 많을 때부터 푸는 데 의의를 두기로 했다.
그리고 채점하기 전만 해도 '어차피 오답만 볼 거니까~' 생각했는데 그 오답이 점점 늘어나는 걸 보면서 모의고사를 참 많이 풀어야겠다고 되뇌었다.
이제 오답풀이 가보자고!

SQLD 제37회 기출 문제 오답노트
Q1. 다음에서 설명하는 것은 ER모델 중 어떤 항목에 대한 설명인가?

- "모든 릴레이션은 원자값을 가져야 한다"
- 릴레이션 = 테이블
- 테이블에 있는 데이터가 더 이상 쪼개질 수 없는 명확한 1개의 값만 가지고 있어야 함
- "어떤 릴레이션에서 속성 값이 가질 수 있는 값의 범위를 의미한다"
- 어떤 테이블에서 컬럼에 들어갈 수 있는 값의 범위를 지정해준다
- = 도메인(Domain)
Q3. 다음 보기 중 슈퍼/서브타입 데이터 모델의 변환 타입에 대한 설명으로 옳은 것은?

- 슈퍼/서브타입 데이터 모델의 변환 타입의 3가지
- ①One to One : 슈퍼타입, 서브타입 테이블들을 각각 개별 테이블로 구성 JOIN 발생
- ②Plus : 각 서브타입에 슈퍼타입을 합해 슈퍼+서브 테이블로 구성 JOIN 발생
- ③Single : 전체를 하나의 테이블로 통합 테이블이 하나
- ⑴One to One이란 개별로 발생되는 트랜잭션에 대해서는 개별 테이블로 구성하고 테이블 수가 많아진다. → ⭕
- ⑵❌ (∵Plus Type은 JOIN 발생함)
- ⑶❌(∵Plus Type은 JOIN이 발생하기에 JOIN 성능이 우수하지 않음, 그리고 관리가 어려워 항상 사용하지 않음)
- ⑷❌(∵One to One Type은 JOIN 성능 우수하지 않음, 테이블 수가 많으니 관리가 편하지도 않음)
Q7. 다음 주어진 ERD 관계에 대한 설명으로 옳지 않은 것은?
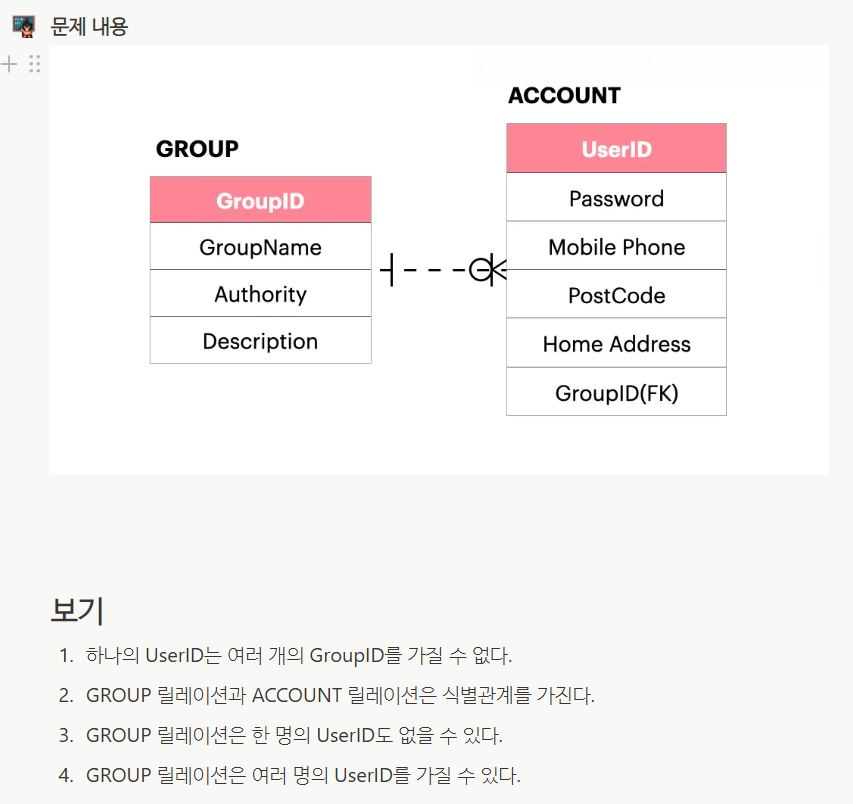
- ⑴⭕: ACCOUNT에서 GROUP을 바라볼 때, GROUP 쪽에 | 표시만 있다는 것은 1개를 가진다는 의미다
- ⑵❌(∵점선은 비식별관계를 의미함)
Q9. 다음은 데이터베이스 모델링 시에 성능을 고려한 모델링 활동이다. 성능을 고려한 데이터베이스 모델링 단계에서 가장 처음으로 수행해야 할 것과 가장 마지막으로 수행해야 할 것은?

- 데이터베이스 모델링 순서 :
- ①정규화 수행
- → ②용량을 산정
- → ③트랜잭션 유형을 분석
- → ④트랜잭션 유형에 따른 반정규화 수행
- → ⑤기본키와 외래키 조정 및 수퍼타입과 서브타입 조정
- → ⑥ 데이터 모델 검증 및 확인
Q11. 다음 보기 중 해시조인(Hash Join)에 대한 설명으로 옳지 않은 것은?

- Hash Join : 작은 테이블과 큰 테이블이 있을 때, 작은 테이블을 먼저 읽어서 똑같은 값을 큰 테이블 내에서 찾아내는 기법
- ⑴⭕(∵동등조인은 같은 값을 찾아내는 것임)
- ⑶❌(∵해시조인은 대용량 데이터를 찾는데 유용한 기법, 온라인 트랜잭션 처리는 실시간으로 처리하기 위해 빨라야 하므로 안 됨)
Q12. 다음 보기 중 Join기법에 대한 설명으로 가장 적절한 것은?

- ⑴⭕: "먼저 나오는 테이블의 선택도가 낮은 테이블…" = 선행테이블이 데이터의 레코드 개수가 적은 것을 택하는 것이 유리함
- Nested Loop Join : 선행 테이블의 처리 범위를 하나씩 접근하면서 추출된 값으로 후행 테이블을 조인하는 방식
- OLTP : 실시간으로 하는 것
- ⑵❌(∵Sort Merge Join은 동등뿐만 아니라 비교연산자로도 가능함)
- ⑶❌(∵Hash Join에서 행의 수가 큰 테이블을 선행 테이블로 사용하면 Hash Area사이즈가 커짐)
Q13. 다음 주어진 테이블에 대해서 아래와 같은 결과값이 나오도록 SQL문의 빈칸에 들어갈 수 있는 내용을 고르시오.
[T_TEST]
DEPTNO JOB SAL
--------------------
10 CLERK 1300
10 MANAGER 2150
20 CLERK 1900
20 ANALYST 6000
20 MANAGER 2000
[결과]
DEPTNO JOB SUM(SAL)
------------------------
10 CLERK 1300
10 MANAGER 2150
10 3450
20 CLERK 1900
20 ANALYST 6000
20 MANAGER 2000
20 9900
13350[SQL]
SELECT DEPTNO, JOB, SUM(SAL)
FROM T_TEST
GROUP BY ( );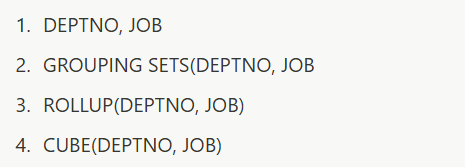
- 보기 중 GROUP BY절에 사용해서 총계를 볼 수 있는 함수는 ROLLUP과 CUBE만.
- ⑴❌(∵그냥 GROUP BY절만 사용하면 그룹별로 묶어서 값만 보여줄 뿐)
- ⑵❌(∵GROUPING SETS() 함수는 그룹별 소계만 보여줌. 누적합은 X)
- ⑶⭕: ROLLUP() 함수는 소계와 총계를 연산함
- ⑷❌(∵CUBE() 함수는 모든 케이스를 전부 보여줌)
Q14. 주어진 두 개의 테이블에서 대해서 아래의 SQL문을 수행한 이후에 TEST1 테이블의 건수는?
[TEST1]
COL1 COL2 COL3
------------------
A X 1
B Y 2
C Z 3
[TEST2]
COL1 COL2 COL3
------------------
A X 1
B Y 2
C Z 3
D 가 4
E 나 5
[SQL]
MERGE INTO TEST1
USING TEST2
ON (TEST1.COL1 = TEST2.COL1)
WHEN MATCHED THEN
UPDATE SET TEST1.COL3 = 4
WHERE TEST1.COL3 = 2
DELETE WHERE TEST1.COL3 <= 2
WHEN NOT MATCHED THEN
INSERT(TEST1.COL1, TEST1.COL2, TEST1.COL3)
VALUES(TEST2.COL1, TEST2.COL2, TEST2.COL3);
- SQL문 해석 :
- TEST1 테이블과 TEST2 테이블을 합쳐라
- TEST1 테이블의 COL1 컬럼의 값과 TEST2테이블의 COL1 컬럼의 값이,
- 일치하면
- TEST1테이블의 COL3의 값이 2일 때, TEST1테이블의 COL3의 값을 4로 바꿔라
- 그리고서 TEST1테이블의 COL3의 값이 2 이하일 때, 값을 지워라
- 일치하지 않으면
- TEST1의 COL1에 TEST2의 COL1 값을 넣고,
TEST1의 COL2에 TEST2의 COL2 값을 넣고,
TEST1의 COL3에 TEST2의 COL3 값을 넣어라
- TEST1의 COL1에 TEST2의 COL1 값을 넣고,
- 일치하면
- SQL문 실행에 따라 변하는 내용 :
- TEST1 테이블에 COL1=B인 행의 COL3 값이 4가 됨
- TEST1테이블에 TEST2에서 COL1=D, COL1=E인 행들의 데이터가 그대로 추가됨
- 그래서 TEST1 테이블의 건수는 5개!!
Q15. 다음은 ABC기업에 대한 데이터베이스 모델링이다. 다음의 설명 중에서 올바른 것은?
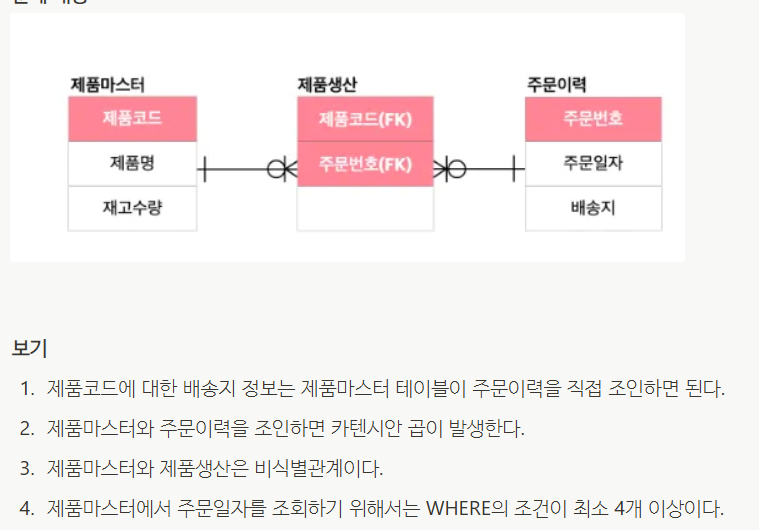
- ⑵⭕: 제품마스터와 주문이력은 둘의 기본키도 다르고 연결되어 있지도 않음. 이런 상황에서 둘을 한 번에 조인하려고 하면 카텐시안 곱이 발생함.
- ⑶❌(∵주어진 ERD에선 점선이 아닌 모두 실선으로 표현돼 있어 식별관계라는 걸 알 수 있음)
- ⑷❌(∵최소 2개임)
Q17. 다음 주어진 SQL문을 수행하였을 때의 결과가 아래와 같을 때 빈칸에 들어갈 것으로 알맞은 것은?
[SQL]
SELECT 10+20 * (( ? )(NULL, 0.1, 0.2))
FROM. DUAL;
[RESULT]
14
- 보기 ⑴, ⑵는 매개변수를 2개 받음
- ⑶NVL2(조건, 값1, 값2) : 조건을 확인했을 때 NULL값이 아니면 값1을, NULL값이면 값2를 출력
- ⑷COALESCE() : 들어오는 값들 중에 NULL값이 아닌 값 중에 첫 번째 값을 출력
Q18. 보기에서 SELECT 결과가 NULL이 아닌 경우는?

- ⑴⭕(∵COALESCE() 함수는 주어진 값들 중에서 NULL값 아닌 것 중에 첫 번째 값을 출력하니까 1이 나옴)
- ⑶❌(∵DECODE()함수는 첫 번째 값과 두 번째 값이 같으면 세 번째 값을, 아니면 네 번째 값을 출력하니까 A≠B이므로 NULL값이 나옴)
- ⑷❌(∵NULLIF() 함수는 첫 번째 값과 두 번째 값이 같으면 NULL값을 출력하니까 A=A이므로 NULL값이 나옴)
Q21. 다음 주어진 테이블에서 집계 함수를 수행하였을 때 결과값으로 다른 것을 고르시오.
[TEST21]
USERID USERCOUNT
-------------------
KIM 10
PARK 20
LIM NULL
SIN NULL1) SELECT COUNT(NVL (USERCOUNT, 0)) FROM TEST21;
2) SELECT SUM(NVL (USERCOUNT, 0)) / 4 FROM TEST21;
3) SELECT AVG(NVL (USERCOUNT, 0)) FROM TEST21;
4) SELECT AVG(NVL (USERCOUNT, 1)) - 0.5 FROM TEST21;- ⑴ 4 (∵USERCOUNT가 NULL값이면 0으로 대체하랬으니까 10, 20, 0, 0을 세면 4)
- ⑵ 7.5 (∵USERCOUNT에서 NULL값을 0으로 대체하면 10, 20, 0, 0이고 이를 모두 더해서 4로 나누면 7.5)
- ⑶ 7.5 (∵⑵과 같은 연산임)
- ⑷ 7.5 (∵USERCOUNT에서 NULL값을 1로 대체하면 10, 20, 1, 1이고 평균을 내서 0.5를 빼면 8-0.5는 7.5)
Q22. 다음 파티션에 대한 설명으로 틀린 것을 고르시오.
1) RANK() OVER (PARTITION BY JOB ORDER BY 급여 DESC) JOB_RANK
#직업별 급여가 높은 순서대로 순위가 부여되고 동일한 순위는 동일한 값이 부여 된다.
2) SUM(급여) OVER (PARTITION BY MGR ORDER BY 급여 RANGE UNBOUNDED PRECEDING)
#RANGE는 논리적 주소에 의한 행 집합을 의미하고 MGR별 현재 행부터 파티션내 첫번째 행까지 급여의 합계를 계산한다.
3) AVG(급여) OVER (PARTITION BY MGR ORDER BY 날짜 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
#각 MGR 별로 앞의 한건, 현재 행, 뒤의 한건 사이에서 급여의 평균을 계산한다.
4) COUNT(*) OVER (ORDER BY 급여 RANGE BETWEEN 10 PRECEDING AND 300 FOLLOWING)
#급여를 기준으로 현재 행에서의 급여의 -10 ~ +300사이의 급여를 가지는 행의 수를 COUNT- ⑵MGR 기준으로 파티션을 주고서 급여 기준으로 정렬할 때,
- PRECEDING UNBOUNDED : 현재 행 기준에서 (파티션 내) 첫 번째 행부터 쭈욱~
- ⑶MGR 기준으로 파티션을 주고서 날짜 기준으로 정렬할 때,
- BETWEEN 1 PRECEDING AND 1 FOLLOWING : 현재 행 기준에서 하나 앞선 행부터 한 행 뒤에 있는 것까지
- 근데 ⑶번 선지에서 "ORDER BY 날짜"에 대한 설명은 없어서 ⑶번이 틀린 선지
- ⑷급여 기준으로 정렬할 때,
- 10 PRECEDING AND 300 FOLLOWING : 현재 행의 급여에서 -10인 값부터 +300인 값까지
Q23. 다음 주어진 테이블에서 아래의 SQL을 수행한 결과로 알맞은 것은?
[TEST23]
COL1 COL2 COL3 COL4
-------------------------
10 10 10 20
20 20 NULL 30
30 NULL NULL 10
NULL 30 10 40
[SQL]
SELECT SUM(COL1+COL2+COL3+COL4) FROM TEST23;
SELECT SUM(COL1) + SUM(COL2) + SUM(COL3) + SUM(COL4) FROM TEST23;
- SUM(COL1+COL2+COL3+COL4)을 연산할 때 NULL값이 포함돼 있으면 연산하지 않음.
- 그래서 첫 번째 행의 10+10+10+20 = 50임
Q28. 다음 보기 중 아래의 SQL에 대한 설명으로 가장 올바른 것은?
SELECT 분류코드,
AVG(상품가격) AS 상품가격,
COUNT(*) OVER (ORDER BY AVG(상품가격)
RANGE BETWEEN 10000 PRECEDING AND 10000 FOLLOWING) AS CNT
FROM 상품
GROUP BY 분류코드;
- ⑴❌(∵윈도우 함수를 GROUP BY절과 함께 쓸 수 있음)
- ⑶⭕
- ⑷❌(∵'상품 전체의' 평균상품가격이 아니라 GROUP BY 분류코드에 의해 "분류코드별"이 되는 것이 맞음)
Q29. 아래의 테이블들에 대해서 SQL문을 수행하였을 때의 결과값은?
[TEST29_1]
COL
----
1
2
3
4
[TEST29_2]
COL
----
2
NULL
[SQL]
SELECT COUNT(*)
FROM TEST29_1 A
WHERE A.COL NOT IN (SELECT COL FROM TEST29_2);
- WHERE절의 NOT IN :
- NOT IN (2, NULL) = 2가 들어가도, NULL값이 들어가도 안 됨
- 1 <> 2 : TRUE
- 1 <>NULL : FALSE (∵같은지 다른지를 따지는 연산에서 NULL값이 들어가면 무조건 FALSE가 뜸)
- NOT IN (2, NULL) = 2가 들어가도, NULL값이 들어가도 안 됨
- ⑴⭕(∵WHERE절 조건에서 "NOT IN (2, NULL)"에 의해 모두 FALSE가 뜨면서 조건을 성립하는 데이터가 하나도 없음)
(아직 끝난 게 아니다.. 안타깝게도...)

아직 틀린 문제들이 한가득 남아있지만, 시간도 늦었고 어차피 15주차 강의도 들어야 하니까 주말 동안 마저 공부하기로 한다.
확실히 문제를 많이 풀어봐야 더 잘 기억에도 남고 이해도 확실히 된다.
'[내배캠] 데이터분석 6기 > 사전캠프 기록' 카테고리의 다른 글
| [사전캠프 15일차] 파이썬 과제, SQLD 공부 (0) | 2025.02.13 |
|---|---|
| [사전캠프 14일차] 아티클 스터디⑩, SQLD 공부, SQL 과제 (0) | 2025.02.12 |
| [사전캠프 13일차] SQLD 공부, SQL 과제 (0) | 2025.02.11 |
| [사전캠프 12일차] 아티클 스터디⑨, 파이썬 공부, SQLD 공부 (3) | 2025.02.10 |
| [사전캠프 11일차] 아티클 스터디⑧, SQL 공부, SQLD 공부 (0) | 2025.02.07 |