
아직도 데이터 전처리 중이다.

가장 처음에 주어진 데이터셋(accepted)의 행와 열의 수다. 컬럼이 무려 151개나 된다.

가장 첫 번째로는 컬럼에서 결측치 비율이 50% 이상인 경우 해당 컬럼을 제거한다. 그러면 151개에서 107개로 줄었다.
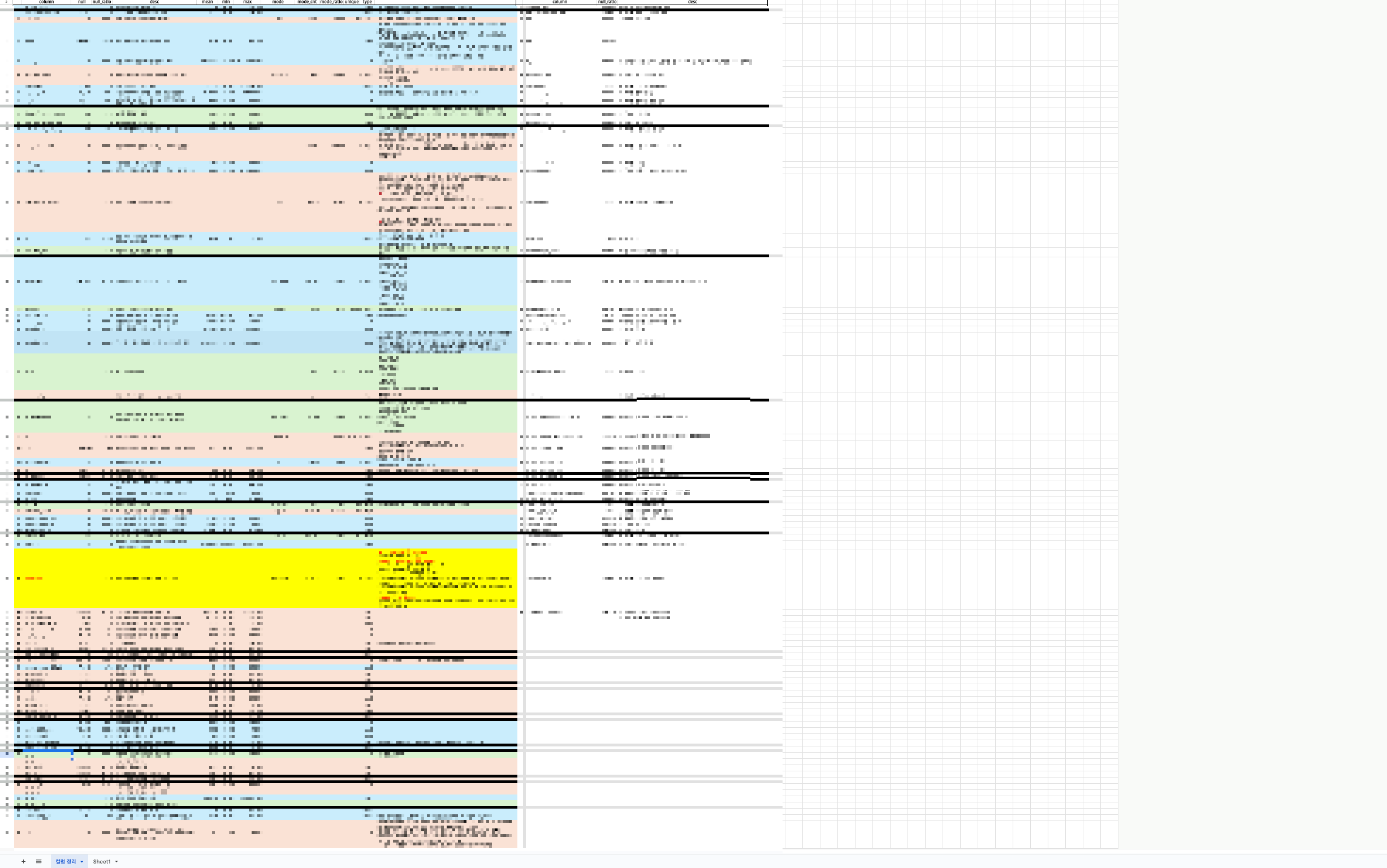
그리고 두 번째로 컬럼마다 어떤 데이터를 담고 있는지 의미를 어느 정도 각자 공부해와서 컬럼을 추렸다. 값이 이상하게 들어있는 컬럼들을 쳐냈다(데이터 하나로 쏠려 있거나 결측치가 많다거나 등). 또 분류 모델에 넣을 때 y로 둘 컬럼 loan_status값이 'Fully Paid', 'Charged Off', 'Default'인 건들만 두고 아닌 건들은 분석에서 제외시키기로 했다.

처음에 비해서 데이터가 많이 줄었다. 행은 2,260,701건에서 1,286,858(처음 주어졌을 때 대비 56.9%)건으로, 열은 151개에서 58개(38.4%)로 줄었다. 사실 loan_status를 3가지 값으로 국한시키면서 절반 가까이 데이터가 날아가는(?) 걸 보고서 '이게 맞나..?' 싶었지만 분류 모델을 학습시키기 위해선 대출 현재 상태가 상환 완료(=상환 성공), 상환 실패로 확정적이어야 학습시킬 수 있으니 맞겠지 싶었다.
데이터 EDA
컬럼별로 살펴보기
오늘은 오전에 만나서 얘길하다가 주말에 추린 58개의 컬럼 중에서 컬럼 3개를 더 제외한(∵결측치가 많음) 총 55개의 컬럼을 4명이서 13~14개로 나눠서 이상치를 처리하기에 앞서서 분포를 확인해보기로 했다.
# 내가 맡은 컬럼
eda_col = [
'last_pymnt_amnt', 'last_pymnt_d', 'loan_amnt', 'loan_status',
'num_accts_ever_120_pd', 'num_sats', 'num_tl_30dpd', 'num_tl_90g_dpd_24m',
'num_tl_op_past_12m', 'open_acc', 'out_prncp', 'out_prncp_inv',
'pct_tl_nvr_dlq', 'percent_bc_gt_75', 'loan_status_2'
]

이 컬럼들과 결측치가 있는 행을 날리면 이와 같은 행과 열의 eda_df가 만들어진다.
'[내배캠] 데이터분석 6기 > 프로젝트 기록' 카테고리의 다른 글
| [본캠프 28일차] 부록: [chap 2] 기초 프로젝트 준비⑤ (0) | 2025.03.27 |
|---|---|
| [본캠프 27일차] 부록: [chap 2] 기초 프로젝트 준비④ (0) | 2025.03.26 |
| [본캠프 26일차] 부록: [chap 2] 기초 프로젝트 준비③ (0) | 2025.03.25 |
| [본캠프 25일차] 부록: [chap 2] 기초 프로젝트 준비② (0) | 2025.03.24 |
| [본캠프 24일차] 부록: [chap 2] 기초 프로젝트 준비① (0) | 2025.03.21 |