제발 오늘은 일찍 자자…

오늘 한 일은,
- 네 번째 아티클 스터디 진행하기 (누적은 15번)
- 팀 과제 PPT 발표 자료 피드백 수렴 및 최종본 확정하기
- 파이썬 공부
- [코드카타] 파이썬 2문제 풀기(39~40번)
- SQL 공부
- [코드카타] SQL 10문제 풀기(41~50번)
- [라이브 세션] SQL 5회차 수강하기
- [ADsP 자격증 챌린지] 4주차 수강하기
아티클 스터디 ④:
오늘 읽은 아티클 :
기획자가 알아야 할 데이터 분석 도구와 활용법 | 요즘IT
기획자로서 성공적인 프로젝트 진행을 위해 데이터 분석은 필수적인 요소입니다. 그렇다면 효과적인 데이터 분석을 위해 필요한 도구는 무엇일까요? 이번 글에서는 수많은 데이터 분석 도구 중
yozm.wishket.com

오늘은 데이터 분석 도구들을 소개하는 아티클을 읽었다. GA나 태블로처럼 들어본 프로그램도 있고, 앰플리튜드나 리대시처럼 새로이 알게 된 툴도 있다. 그런데 알고 있던 툴이든 새로 알게 된 것이든 아직 다룰 줄은 모른다는 것. 데이터 분석을 공부할수록 이런 언어도 있고, 이런 프로그램도 있고, 계속 알게 되는 건 많은데 내가 실질적으로 다룰 줄 아는 수준과 범위를 아직은 걸음마 수준이니 산더미처럼 쌓인 할 일 앞에서 작아지고, 조바심도 느껴지는 때가 많다. 그렇지만 아티클의 말미에서 얘기하듯이, 어디까지나 이 모든 것들은 더 나은 의사결정을 내리기 위한 커다란 목적하에 시도할 수 있는 수많은 방법 중 하나라는 사실을 잊지 말아야겠다는 생각을 하며 마음을 다잡았다. 물론 그렇다고 해서 지금 SQL을 배우고, 파이썬을 배우고, 분석 방법론을 배우는 것을 게을리하겠다는 말은 아니지만, 그래도 한국어를 할 줄 아는 것과 한국어를 잘하는 것이 다르듯, 데이터 분석을 잘하려면 내가 가장 신경쓰고 놓치지 말아야 하는 부분은 무엇일지 고민하며 계속 공부해나가야겠다.
파이썬 공부: 코드카타 풀기(39~40번)
038. 직사각형 별 찍기
이 문제에는 표준 입력으로 두 개의 정수 n과 m이 주어집니다.
별(*) 문자를 이용해 가로의 길이가 n, 세로의 길이가 m인 직사각형 형태를 출력해보세요.
(사실 이 문제는 어제 푼 문제인데 어제 팀 과제 PPT 작업하느라 어제의 TIL을 작성하지 못해 오늘치에 함께 기록한다)
줄바꿈을 파이썬에서 어떻게 표현하는지 몰라서 찾아봤다.
[참고] 파이썬 기초, 문자열(인덱싱, 슬라이싱, 문자포맷, 줄바꿈 등)
a, b = map(int, input().strip().split(' '))
answer = ('*'*a +'\n')*b
print(answer)- \n : 줄바꿈
줄바꿈을 입력하는 법을 찾아서 위와 같이 코드를 작성했다.
040. 3진법 뒤집기
자연수 n이 매개변수로 주어집니다. n을 3진법 상에서 앞뒤로 뒤집은 후, 이를 다시 10진법으로 표현한 수를 return 하도록 solution 함수를 완성해주세요.
문제를 풀기 전에 10진법의 숫자를 2진법이나 3진법으로 바꿔주는 함수가 있는지 찾아봤다.
[참고] 파이썬 진수변환(2진법, 3진법, 5진법, 10진법)[n진법]
def solution(n):
answer = ''
while n > 0:
re = n%3
n = n//3
answer += str(re)
return int(answer, 3)- int(string, n) : n진수를 10진수로 변환
- bin() / oct() / hex() : 10진수를 2진수/8진수/16진수로 변환
- 앞에 달고 나오는 알파벳을 지우려면 슬라이싱 [2:]을 사용해 제거
찾은 내용을 참고해 위와 같이 코드를 작성했다.
SQL 공부①: 코드카타 풀기(41~50번)
044. 가격대별 상품 개수 구하기
테이블에서 만원 단위의 가격대 별로 상품 개수를 출력하는 SQL 문을 작성해주세요. 이때 컬럼명은 각각 컬럼명은 PRICE_GROUP, PRODUCTS로 지정해주시고 가격대 정보는 각 구간의 최소금액(10,000원 이상 ~ 20,000 미만인 구간인 경우 10,000)으로 표시해주세요. 결과는 가격대를 기준으로 오름차순 정렬해주세요.
우선 가격대를 구분하기에 앞서서 최대 금액이 얼마인지 조회했다.
SELECT MAX(price)
FROM product
금액에서 최고가가 85,000이니까 80000 미만까진 조건을 범위를 설정하여 입력하고 그 이후를 ELSE로 주면 되겠다.
SELECT CASE WHEN 0 <= price < 10000 THEN 0
WHEN 10000 <= price < 20000 THEN 10000
WHEN 20000 <= price < 30000 THEN 20000
WHEN 30000 <= price < 40000 THEN 30000
WHEN 40000 <= price < 50000 THEN 40000
WHEN 50000 <= price < 60000 THEN 50000
WHEN 60000 <= price < 70000 THEN 60000
WHEN 70000 <= price < 80000 THEN 70000
ELSE 80000 END price_group,
COUNT(*) products
FROM product
GROUP BY 1
처음엔 이렇게 쿼리를 작성해 실행했더니 아래와 같은 결과 테이블이 조회됐다.
원래 여태까지 범위 조건을 줄 때 주로 BETWEEN a AND b를 사용했는데 이렇게 작성하면 a 이상 b 이하로 범위가 설정되기에
이번엔 비교 연산자를 사용해 조건을 입력했는데 방법이 잘못돼 이렇게 가격대가 0(0~10000)인 것만 뜬 것일까 싶었다.
SELECT CASE WHEN (price >= 0) AND (price < 10000) THEN 0
WHEN (price >= 10000) AND (price < 20000) THEN 10000
WHEN (price >= 20000) AND (price < 30000) THEN 20000
WHEN (price >= 30000) AND (price < 40000) THEN 30000
WHEN (price >= 40000) AND (price < 50000) THEN 40000
WHEN (price >= 50000) AND (price < 60000) THEN 50000
WHEN (price >= 60000) AND (price < 70000) THEN 60000
WHEN (price >= 70000) AND (price < 80000) THEN 70000
ELSE 80000 END price_group,
COUNT(*) products
FROM product
GROUP BY 1
ORDER BY 1
위와 같이 가격대 지정을 위한 조건을 수정해주니 원하는 결과 테이블이 조회됐다.
048. 즐겨찾기가 가장 많은 식당 정보
REST_INFO 테이블에서 음식종류별로 즐겨찾기수가 가장 많은 식당의 음식 종류, ID, 식당 이름, 즐겨찾기수를 조회하는 SQL문을 작성해주세요. 이때 결과는 음식 종류를 기준으로 내림차순 정렬해주세요.
SELECT food_type,
rest_id,
rest_name,
favorites
FROM rest_info
GROUP BY 1 --1.food-type별로 묶었을 때,
HAVING MAX(favorites) --2.favorites 수가 가장 많은 식당을 조회하기 위해
ORDER BY 1 DESC처음에 이렇게 쿼리를 작성했다.
코드를 실행했더니 의도한 대로 한식, 중식, 일식 등 종류별로 식당이 조회되는 것 같길래 제출했더니 틀렸다는 메시지가 떴다.

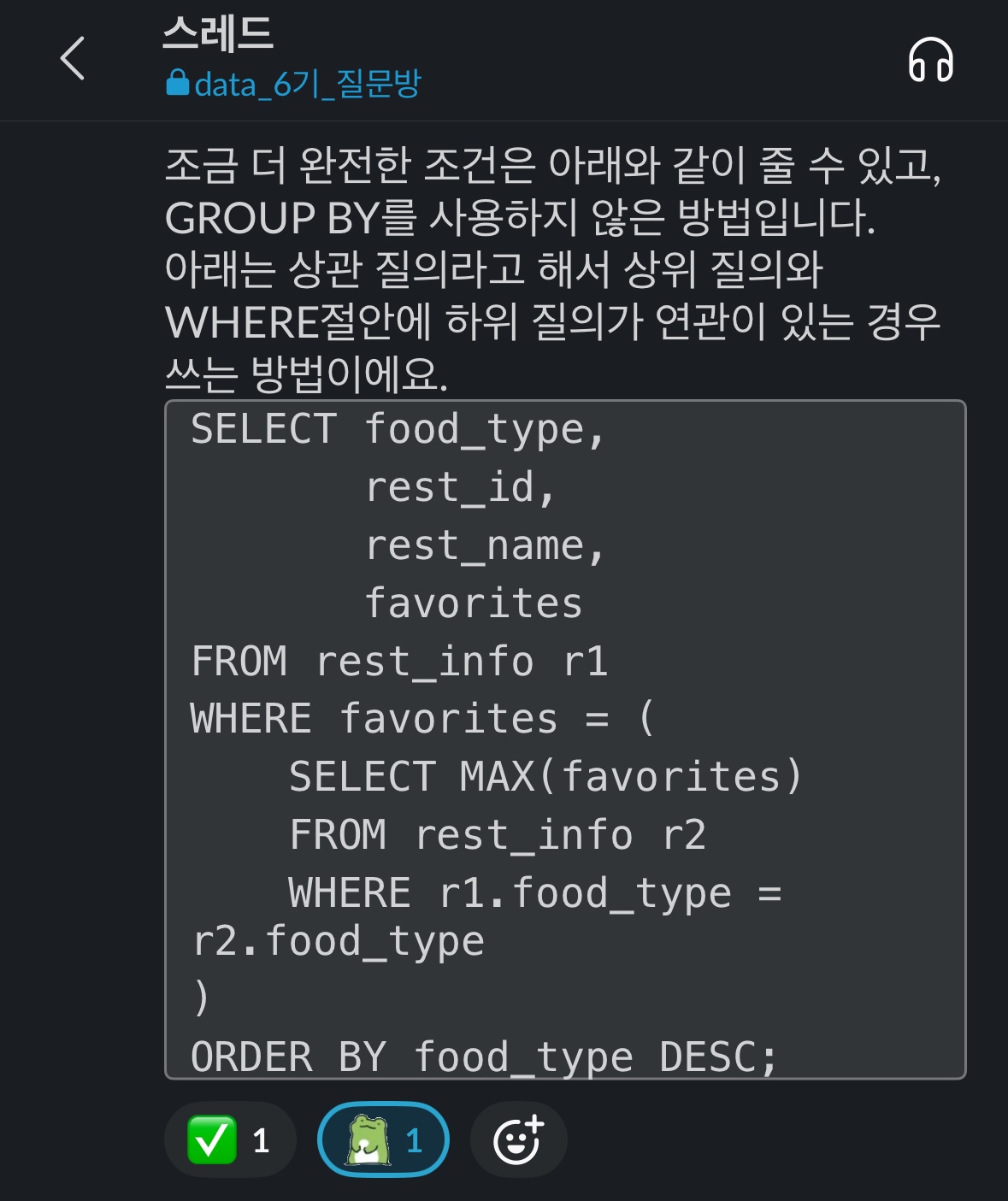
이 문제에 관한 질문을 다른 사람들도 했을 것 같아서 우선 질문방에 해당 문제를 검색해봤다.
한 3건 정도 있었는데 그 중 나와 같은 SQL문을 작성해서 같은 의문이 가진 분이 질문한 글이 있었다.
튜터님의 답변에 따르면,
- ⑴GROUP BY절을 사용해 그룹을 지정할 때에 SELECT절에 그룹화되지 않은 컬럼을 포함하면 안 된다는 점
- ⑵HAVING절에 MAX(favorites)에 비교 연산자가 없으므로 불완전한 조건문이라는 점
위의 2가지가 내가 작성한 SQL문이 가진 문제점이었다.
⑴과 같은 상황에서라면 GROUP BY절을 사용하지 말고 서브쿼리를 써서 해당 문제를 풀어야 한다는 게 48번 질문에 대한 답변의 공통된 요지였다.
SELECT food_type,
rest_id,
rest_name,
favorites
FROM rest_info r1
WHERE (food_type, favorites) IN
(SELECT food_type,
MAX(favorites)
FROM rest_info r2
GROUP BY 1
) -- WHERE절에서 우선 서브쿼리로 음식타입별 즐겨찾기가 제일 높은 값들을 찾아놓고서, 이 조건과 일치하는 음식타입과 즐겨찾기가 모두 일치할 때만 조회하기
ORDER BY 1 DESCFROM절에 서브쿼리는 그래도 몇 번 써봤는데 WHERE절에 써보기는 처음이라 어색하지만
WHERE절에 서브쿼리를 사용해서 쿼리도 자주 작성해봐야겠다.
050. 5월 식품들의 총매출 조회하기
FOOD_PRODUCT 와 FOOD_ORDER 테이블에서 생산일자가 2022년 5월인 식품들의 식품 ID, 식품 이름, 총매출을 조회하는 SQL문을 작성해주세요. 이때 결과는 총매출을 기준으로 내림차순 정렬해주시고 총매출이 같다면 식품 ID를 기준으로 오름차순 정렬해주세요.
SELECT fp.product_id,
fp.product_name,
fp.price*fo.amount total_sales
FROM food_product fp LEFT JOIN food_order fo ON fp.product_id = fo.product_id
WHERE fo.produce_date LIKE '2022-05%'
GROUP BY 1, 2
ORDER BY 3 DESC, 1
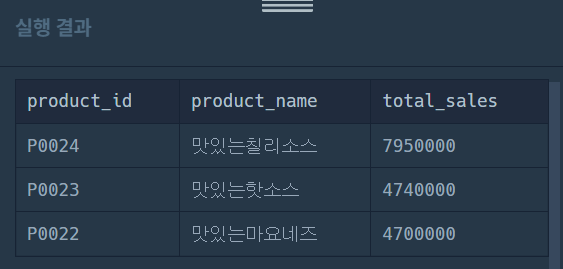
처음엔 이렇게 작성했다.
코드를 실행했을 때 잘 조회하는 것 같아서 제출했는데 틀렸다는 메시지가 떴다.
SELECT fp.product_id,
fp.product_name,
SUM(fp.price*fo.amount) total_sales
FROM food_product fp LEFT JOIN food_order fo ON fp.product_id = fo.product_id
WHERE fo.produce_date LIKE '2022-05%'
GROUP BY 1, 2
ORDER BY 3 DESC, 1총 매출을 구해야 해서 total_sales에 SUM()까지 입력해줬어야 하는 거였다.
ADsP 공부: [ADsP 자격증 챌린지] 4주차 수강하기
마스터플랜 수립 프레임워크
마스터플랜 수립 개요
- 분석 마스터 플랜을 수립하는 가장 첫 번째 단계는 우선순위를 정하는 일, 그 다음으로는 분석 과제의 적용 범위 및 방식을 설정함
- 마스터플랜 수립 프레임워크: 분석 과제의 우선순위와 적용 범위 및 방식을 종합적으로 고려하여 최종적으로 분석 구현의 로드맵을 수립하는 일련의 과정 및 형식

- 분석 마스터 플랜은 일반적인 ISP(정보 전략 계획)방법론을 활용하되 데이터 분석 기획의 특성을 고려하여 수행하고 기업에서 필요한 데이터 분석 과제를 빠짐없이 도출한 후 과제의 우선순위를 결정하고 단기 및 중/장기로 나누어 계획을 수립
수행 과제 도출 및 우선순위 평가
- 일반적인 IT 프로젝트 우선순위 평가

- 빅데이터의 특징을 고려한 분석 ROI 요소
- 크게 보면 ①투자 비용 요소와 ②비즈니스 효과 요소가 있음
- ①투자 비용 측면의 요소: 크키(volume), 다양성(variety), 속도(velocity)의 3V
- volume : 데이터의 규모 및 양을 의미, 대용량 데이터를 저장/처리하고 관리하기 위해서는 새로운 투자가 필요
- variety : 다양한 종류의 형태를 가진 데이터를 입수하는 데에 있어 투자가 필요
- velocity : 데이터 생성 속도 및 처리 속도를 빠르게 가공/분석하는 기술이 요구됨
- ②비즈니스 효과 측면의 요소 : 분석 결과를 활용하거나 실질적인 실행을 통해 얻게 되는 비즈니스 가치(value)
- value : 기업 데이터 분석을 통해 추구하거나 달성하고자 하는 목표 가치를 의미함
- ①투자 비용 측면의 요소: 크키(volume), 다양성(variety), 속도(velocity)의 3V
- 크게 보면 ①투자 비용 요소와 ②비즈니스 효과 요소가 있음
- ROI를 활용한 우선순위 평가 기준
- 시급성
- 시급성의 판단 기준은 전략적 중요도가 핵심
; 현재의 관점에서 전략적 가치를 둘 것인지, 미래의 중장기적 관점에 전략적인 가치를 둘 것인지 - Value, 비지니스 효과 측면과 연결
- 시급성의 판단 기준은 전략적 중요도가 핵심
- 난이도
- 현시점에서 과제를 추진하는 것이 적용 비용 측면과 범위 측면에서 바로 적용하기 쉬운 것인지 또는 어려운 것인지에 대한 판단 기준
- 3V와 연결
- 시급성
- 포트폴리오 사분면 분석을 활용한 우선순위 평가 기준
- 사분면 영역에서 가장 우선적인 분석 과제 적용이 필요한 영역은 3사분면
- 우선순위 기준을,
- 시급성에 둔다면 ‘III → IV → II’ 영역 순서
- 난이도에 둔다면 ‘III → I → II’ 영역 순서
- 이는 절대적인 것은 아님
; 시급성이 높고 난이도도 높은 ‘I’ 사분면의 경우 난이도를 낮추어 가장 먼저 우선순위를 정할 수도 있음 - III (단기) → II (중장기)


어제 팀 과제 발표자료를 만든다고 신경 쓰느라 늦게까지 자지 못해서 오늘 컨디션이 안 좋았다. 그래서 ADsP 강의를 마저 다 들어 해치우고 싶은 마음도 강하지만 우선 일찍 자서 컨디션을 회복해야 12시간 공부하는 일정을 소화할 수 있을 거란 생각에 목표에 비해 조금밖에 못 들었어도 수면 시간을 챙기는 것을 우선으로 두기로 했다.
그리고 사실 인강을 힘들어하는 사람으로서(차라리 문제집을 잡고서 손으로 줄 그어가며 끄적이면서 듣고, 주로 문제를 풀고 채첨하고 오답들을 점검하길 반복하는 방식으로 공부하는 사람) 안 그래도 쉽지 않은데 집중력이 거의 고갈되는 가장 마지막 일정이 온라인 강의 수강 일정이라 더 많은 시간이 소요되는 것 같기도 해서 내일은 코드카타 문제 풀이를 뒤로 미루고 강의 수강하는 시간대를 좀 앞당겨보려 한다. 별다른 차이가 없을지도 모르지만, 앞으로 온라인 강의 들을 일이 더 있을 것 같은데(아직 온라인 강의 받은 것도 다 듣지 못했는데 어제 들을 강의가 더 추가됐다..) 더 나은 방식을 찾아보려 시도해보며 공부해야겠다.

'[내배캠] 데이터분석 6기 > 본캠프 기록' 카테고리의 다른 글
| [본캠프 11일차] ADsP 공부, SQL 공부, SQL 코드카타, 파이썬 코드카타, 아티클 스터디 ① (0) | 2025.03.04 |
|---|---|
| [본캠프 10일차] ADsP 공부, SQL 공부, 코드카타 복습(SQL만) (0) | 2025.02.28 |
| [본캠프 7일차] 아티클 스터디③, 파이썬 코드카타, SQL 공부, ADsP 공부 (2) | 2025.02.25 |
| [본캠프 6일차] 팀플 주제 선정, 파이썬 코드카타, SQL 코드카타, SQL 공부, ADsP 공부 (0) | 2025.02.24 |
| [본캠프 5일차] SQL 공부, 코드카타 복습(SQL, 파이썬), ADsP 공부 (0) | 2025.02.21 |