
오늘 한 일은,
- 팀 과제 역할 분담하기
- 세 번째 아티클 스터디 (누적은 14번)
- 파이썬 공부
- [코드카타] 파이썬 3문제 풀기(35~37번)
- SQL 공부
- [코드카타] SQL 10문제 풀기(31~40번)
- 팀 과제를 위해 개인적으로 EDA 해보기
- [ADsP 자격증 챌린지] 3주차 수강 완료하기(3-3~3-5)
아티클 스터디 ③: SQL 가독성을 높이는 다섯 가지 사소한 습관
오늘 읽은 아티클 :
SQL 가독성을 높이는 다섯 가지 사소한 습관 | 요즘IT
지독하게 읽기 힘든 SQL 문을 해석해 본 적 있으신가요? 마치 암호를 읽는 것처럼 어렵습니다. 파이선처럼 들여쓰기와 띄어쓰기를 문법적으로 강제하는 언어를 사용해 봤다면 SQL의 자유로움에
yozm.wishket.com
지난 스터디처럼 오늘 스터디를 진행한 아티클도 사전캠프 때 이미 읽은 아티클이다,
(👇이전 아티클 스터디 기록 보러가기👇)
[사전캠프 7일차] 아티클 스터디⑤, SQL 공부
'벌써'라는 말이2월처럼 잘 어울리는 달은아마 없을 것이다.- 오세영, 「2월」 中 -벌써 2월이다. 1월 20일부터 사전캠프에 합류했으니, 중간에 설 연휴가 길긴 했어도, 얼추 절반 정도는 된 셈이다
maandoo.tistory.com

지난 스터디 때도 이 글은 어려운 내용 없이 SQL 작성할 때 보기 좋게 적을 때 염두에 둘 사항들을 알려주는 글이어서 지금 라이브세션으로 SQL 강의를 듣고 있는 때에 다시 새겨보면 좋은 글이었다.
지금 라이브세션으로 SQL 강의를 듣고 있는 때에 다시 새겨보면 좋은 글이었다.
오늘 조원들의 인사이트를 읽다가 새로이 알게 된 부분이 있었다. 프로그래밍 언어마다 네이밍 컨벤션이 다 다른데 지금 배우고 있는 SQL과 파이썬은 snake_case라고 하는 소문자와 언더바로 작성하는 방식이고 더 찾아보니 그 외에도 camelCase, PascalCase, kebab-case처럼 여러 규칙들이 있다는 걸 배웠다.
파이썬 공부: 코드카타 풀기(35~37번)
035. 부족한 금액 계산하기
새로 생긴 놀이기구는 인기가 매우 많아 줄이 끊이질 않습니다. 이 놀이기구의 원래 이용료는 price원 인데, 놀이기구를 N 번 째 이용한다면 원래 이용료의 N배를 받기로 하였습니다. 즉, 처음 이용료가 100이었다면 2번째에는 200, 3번째에는 300으로 요금이 인상됩니다.
놀이기구를 count번 타게 되면 현재 자신이 가지고 있는 금액에서 얼마가 모자라는지를 return 하도록 solution 함수를 완성하세요.
단, 금액이 부족하지 않으면 0을 return 하세요.
def solution(price, money, count):
for i in range(1,count+1):
money -= price*i
if money == 0:
answer = 0
if money < 0:
answer = -money
return answer처음에는 이렇게 작성했다.
샘플케이스를 통과했길래 제출했는데 왜인지 틀렸다고 했다.

주어진 문제와 내가 작성한 코드를 다시 읽어보니 money가 0이 될 때 0을 반환할 게 아니라
금액이 부족하지 않으면, 즉 money가 0 이상일 때로 조건을 수정해주면 될 것 같았다.
def solution(price, money, count):
for i in range(1,count+1):
money -= price*i
if money >= 0: #수정한 if문의 조건
answer = 0
if money < 0:
answer = -money
return answer이렇게 작성해주니 통과했다. 주어진 조건을 잘 읽자^^
036. 문자열 다루기 기본
문자열 s의 길이가 4 혹은 6이고, 숫자로만 구성돼있는지 확인해주는 함수, solution을 완성하세요. 예를 들어 s가 "a234"이면 False를 리턴하고 "1234"라면 True를 리턴하면 됩니다.
문자열을 알아내려면 len() 함수를 쓰면 된다는 것은 알지만 데이터 타입을 판별하기 위해 사용할 방법을 몰라 이 부분을 구글링하여 코드를 작성했다.
def solution(s):
answer = True
if len(s)== 4 or len(s)== 6:
if s.isdigit() == True:
answer = True
else:
answer = False
return answer[참고] 파이썬으로 문자열 체크하기 | 문자열 체크 함수 | isalpha(), isalnum(), isnumeric(), isdigit(), isdecimal()
- .isalpha() : 해당 값이 영어 또는 한글로만 이루어져 있는지 확인하고 True, False를 반환
- .isalnum() : 해당 값이 영어, 한글, 숫자로만 이루어져 있는지 확인하고 True, False를 반환
- 영어로만 혹은 한글로만 혹은 숫자로만 이루어져 있어도 True를 반환함
(꼭 여러 데이터 타입이 섞여있을 때만 True를 반환하지 않음)
- 영어로만 혹은 한글로만 혹은 숫자로만 이루어져 있어도 True를 반환함
- .isdigit() : 해당 값이 숫자로만 이루어져 있는지 확인하고 True, False를 반환
- 거듭제곱 꼴의 숫자를 인식함
- .isnumeric() : 해당 값이 숫자로만 이루어져 있는지 확인하고 True, False를 반환
- 거듭제곱 꼴의 숫자를 인식함
- .isdecimal() : 해당 값이 숫자로만 이루어져 있는지 확인하고 True, False를 반환
- 거듭제곱 꼴의 숫자를 인식하지 못함 (4²같은 숫자가 들어오면 문자로 인식해 False를 반환)
찾은 내용을 참고해서 .isdigit() 메소드를 사용해서 코드를 작성했다.
그런데 오류가 떠서 코드를 다시 살펴보다가 '혹시 이 부분인가' 싶어서 코드를 수정했다.
def solution(s):
answer = True
if len(s)== 4 or len(s)== 6:
if s.isdigit() == True:
answer = True
else:
answer = False
else:
answer = False #추가한 코드(바깥쪽 if문에도 else를 추가)
return answer위와 같이 수정해주니 원하는 대로 코드가 돌아갔다.
037. 행렬의 덧셈
행렬의 덧셈은 행과 열의 크기가 같은 두 행렬의 같은 행, 같은 열의 값을 서로 더한 결과가 됩니다. 2개의 행렬 arr1과 arr2를 입력받아, 행렬 덧셈의 결과를 반환하는 함수, solution을 완성해주세요.
def solution(arr1, arr2):
answer = [[]]
for i in range(len(arr1)):
answer.append(arr1[i]+arr2[i])
print(answer)
return answer
우선 위와 같이 작성해놓고 어떻게 돌아가나 확인해봤다.
두 가지 샘플 테스트 모두 각 행렬에 담겨 있는 값이 2개니까 연산을 2번했는데
테스트 1 기준으로 내가 의도한 건 행렬의 같은 순번에 있는 값끼리 더하라는 의미였는데 ([1+3, 2+4] = [4, 6])
첫 번째 출력된 형태를 보니 그냥 같이 담기기만 했다. (arr1의 [1, 2]와 arr2의 [3, 4]가 [1, 2, 3, 4])가 됨)
def solution(arr1, arr2):
answer = []
for i in range(len(arr1)):
for ii in range(len(arr1[i])):
answer.append(arr1[i][ii]+arr2[i][ii]) #행렬 속 행렬을 덧셈하려고 for문을 중첩함
return answer
첫 번째 시도는 행렬 속 행렬을 덧셈하려고 for문을 중첩시켰다. 근데 행렬 속 행렬끼리 묶여서 담기지 않았다.
def solution(arr1, arr2):
answer = []
for i in range(len(arr1)):
ans = []
for ii in range(len(arr1[i])):
ans.append(arr1[i][ii]+arr2[i][ii])
answer.append(ans)
return answer최종적으로 작성한 코드는 위와 같다.
행렬 속 행렬을 담아주기 위해 ans를 정의해서 행렬 속 행렬의 덧셈이 되면 그걸 ans에 담아서 answer에 추가하도록 했다.

대체 파이썬이랑은 언제 친해질 수 있는 거지..
아무튼, 오늘 파이썬 문제는 끝!
SQL 공부 ①: 코드카타 풀기(31~40번)
031. 오랜 기간 보호한 동물(1)
아직 입양을 못 간 동물 중, 가장 오래 보호소에 있었던 동물 3마리의 이름과 보호 시작일을 조회하는 SQL문을 작성해주세요. 이때 결과는 보호 시작일 순으로 조회해야 합니다.
이제 31번부터는 주어지는 테이블이 2개다.
여태까지 학습하면서 실습할 때 주로 교집합과 합집합을 위한 쿼리를 몇 번 쿼리를 짜봤는데 이번 경우는 animal_ins 테이블에서 animal_outs에 있는 부분을 빼는 차집합을 해줘야 한다.
[참고] 차집합 : SELECT - NOT IN 과 LEFT OUTER JOIN
그래서 위의 글을 참고해서,
animal_ins 테이블에 animal_outs 테이블을 animal_id 컬럼을 기준으로 LEFT JOIN을 하고서
그 상태에서 WHERE절로 animal_outs 테이블의 animal_type 컬럼이 NULL값인 것만 조회했다. (참고로 animal_outs 테이블은 name만 빼고는 전부 Nullable 조건이 FALSE로 설정됨)
SELECT ai.name,
ai.datetime
FROM animal_ins ai LEFT JOIN animal_outs ao ON ai.animal_id = ao.animal_id
WHERE ao.animal_type IS NULL --입양된 동물들을 제외하기 위해
ORDER BY ai.datetime LIMIT 3
문제에서 주어진 조건들에 따라서 최종적으로 위와 같이 쿼리를 작성했다.
035. 오랜 기간 보호한 동물(2)
입양을 간 동물 중, 보호 기간이 가장 길었던 동물 두 마리의 아이디와 이름을 조회하는 SQL문을 작성해주세요. 이때 결과는 보호 기간이 긴 순으로 조회해야 합니다.
날짜 데이터를 이용해 기간을 구해서 그 값을 활용하면 될 것 같아서 이 부분에 해당하는 함수가 없는지 찾아봤다.
- DATEDIFF(종료일, 시작일) : 두 기간 사이의 일수 계산
SELECT a.animal_id,
a.name
FROM
(SELECT ao.animal_id,
ao.name,
DATEDIFF(ao.datetime, ai.datetime) period
FROM animal_outs ao LEFT JOIN animal_ins ai ON ao.animal_id = ai.animal_id
ORDER BY 3 DESC LIMIT 2) a검색을 통해 알게 된 DATEDIFF() 함수를 사용해 쿼리를 작성했다.
period라는 값을 구해놓고 그를 활용해 내림차순으로 정렬시켜서 상위 2건만 조회시켰다.
그리고 문제에서 요구한 것처럼 아이디와 이름만 조회하기 위해 서브쿼리를 사용했다.
ADsP 공부: [ADsP 자격증 챌린지] 3주차 수강하기
(👇 [ADsP 자격증 챌린지] 3주차 강의의 앞선 부분 정리한 글 👇)
[본캠프 6일차] 팀플 주제 선정, 파이썬 코드카타, SQL 코드카타, SQL 공부, ADsP 공부
다시 찾아온 월요일.주말이 벌써 지나가버렸다는 소식이 믿기지 않지만 오늘도 오늘의 할 일을 성실히 하며 보내야 또 내일을 잘 보낼 수 있으니까 뭐라도 해봐야지! 주말이 벌써 지나가버렸다
maandoo.tistory.com
분석 방법론
전통적인 분석 방법론 ①: KDD 분석 방법론
- KDD(Knowledge Discovery in Database)
: 데이터로부터 통계적 패턴이나 지식을 찾기 위해 활용할 수 있도록 체계적으로 정리한 데이터 마이닝 프로세스 - KDD 분석 방법론 프로세스
- [1단계] 데이터셋 선택
- 데이터셋 선택에 앞서 분석 대상의 비즈니스 도메인에 대한 이해와 프로젝트 목표 설정 필수
- 데이터베이스에서 분석에 필요한 데이터를 선택하는 단계 (타깃 데이터 생성)
- [2단계] 데이터 전처리
- 추출된 분석 대상용 데이터 셋에 포함되어 있는 잡음(Noise), 이상치(Outlier), 결측치(Missing value)를 파악하여 제거하거나 의미 있는 데이터로 재가공 - 결측치: 입력되지 않아 비어있는 데이터
- 추가로 요구되는 데이터 셋이 있다면 데이터 선택 프로세스 재실행
- [3단계] 데이터 변환
- 데이터 전처리 과정을 통해 정제된 데이터에 분석 목적에 맞게 변수를 생성, 선택하고 데이터의 차원을 축소
- 데이터마이닝 프로세스 진행을 위해 데이터셋 변경
- [4단계] 데이터 마이닝
- 학습용 데이터를 이용하여 분석 목적에 맞는 데이터 마이닝 기법을 선택하고, 적절한 알고리즘을 적용하여 데이터마이닝 작업을 실행하는 단계
- 필요에 따라 데이터 전처리와 프로세스 추가 실행
- [5단계] 해석과 평가
- 데이터마이닝 결과에 대한 해석과 평가, 그리고 분석 목적과의 일치성 확인
- [1단계] 데이터셋 선택

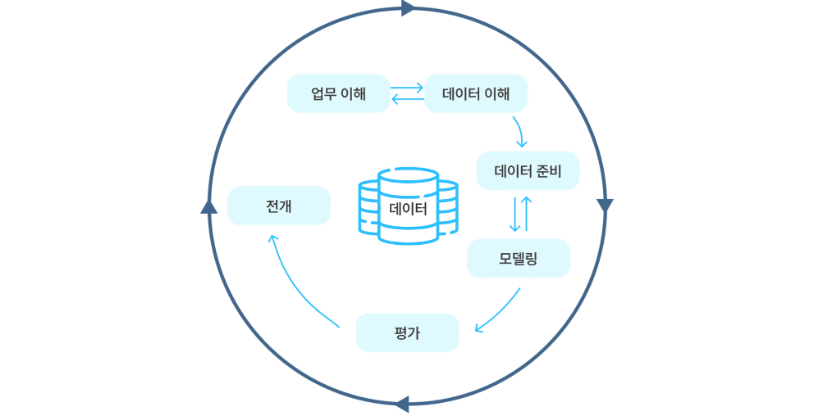
전통적인 분석 방법론 ②: CRISP-DM 분석 방법론
- CRISP-DM(Cross Industry Standard Process for Data Mining)
: KDD 분석 방법론과 비슷하나 조금 더 세분화되어 있다는 것이 차이점
; 각 단계는 단방향으로 구성되어 있지 않고 단계 간 피드백을 통하여 단계별 완성도를 높이게 되어 있음 - CRISP-DM 분석 방법론 프로세스 - 이해하기 위한 단계가 추가됨, 특정 단계 간 피드백이 발생
- [1단계] 업무 이해
- 업무 목적 파악, 상황 파악, 데이터 마이닝 목표 설정, 프로젝트 계획 수립
- [2단계] 데이터 이해
- 초기 데이터 수집, 데이터 기술 분석, 데이터 탐색, 데이터 품질 확인
- [3단계] 데이터 준비
- 분석용 데이터 셋 선택, 데이터 정제, 분석용 데이터 셋 편성, 데이터 통합, 데이터 포맷팅
- [4단계] 모델링
- 모델링 기법 선택, 모델 테스트 계획 설계, 모델 작성, 모델 평가
- [5단계] 평가
- 모델링 결과가 프로젝트 목적에 부합하는지 평가하는 단계
- 데이터마이닝 결과를 최종적으로 수용할 것인지 판단
- 분석 결과 평가, 모델링 과정 평가, 모델 적용성 평가
- [6단계] 전개
- 완성된 모델을 실 업무에 적용하기 위한 계획을 수립하는 단계
- 전개 계획 수립, 모니터링과 유지보수 계획 수립, 프로젝트 종료 보고서 작성, 프로젝트 리뷰
- [1단계] 업무 이해
빅데이터 분석 방법론
- 빅데이터 분석 방법론의 개요
- 계층적 프로세스 모델로서 단계, 태스크, 스텝 3계층 레벨과 5단계로 구성
- 5개의 단계들을 프로세스 그룹이라고 함

- ⭐ 빅데이터 분석 방법론 5단계 플로우⭐
- 세부사항들을 전부 외운다기보단 큰 틀에 맞춰서 흐름을 따라가며 키워드 위주로 공부 (어떤 단계로 구성되고, 그 단계에는 어떤 태스크가, 또 그 태스크엔 이런 스텝들이…)
- 1️⃣분석 기획
: 비즈니스 도메인과 문제점을 인식하고 분석 계획 및 프로젝트 수행계획을 수립하는 단계- [태스크①] 비즈니스 이해 및 범위 설정
- <스텝ⅰ> 비즈니스 이해
- <스텝ⅱ> 프로젝트 범위 설정 (프로젝트 범위 정의서(SOW))
- [태스크②] 프로젝트 정의 및 계획 수립
- <스텝ⅰ> 데이터 분석 프로젝트 정의
- <스텝ⅱ> 프로젝트 수행 계획 수립 (WBS)
- [태스크③] 프로젝트 위험계획 수립
- <스텝ⅰ> 데이터 분석 위험 식별: 위험의 우선순위 설정
- <스텝ⅱ> 위험 대응 계획 수립: 예상된 위험을 회피, 전이, 완화, 수용으로 구분해 위험 관리 계획서 작성
- [태스크①] 비즈니스 이해 및 범위 설정
- 2️⃣데이터 준비
: 데이터 수집 및 정합성 체크- [태스크①] 필요 데이터 정의
- <스텝ⅰ> 데이터 정의 : 분석에 필요한 데이터를 정의함 (데이터 정의서)
- <스텝ⅱ> 데이터 획득방안 수립
- [태스크②] 데이터 스토어 설계
- <스텝ⅰ> 정형 데이터 스토어 설계: 일반적으로 관계형 데이터베이스인 RDBMS를 사용
- <스텝ⅱ> 비정형 데이터 스토어 설계: NOSQL 등을 이용해 비정형·반정형 데이터를 저장
- [태스크③] 데이터 수집 및 정합성 점검
- <스텝ⅰ> 데이터 수집 및 저장
- <스텝ⅱ> 데이터 정합성 점검
- [태스크①] 필요 데이터 정의
- 3️⃣데이터 분석
: 모델링 및 모델 평가- [태스크①] 분석용 데이터 준비
- <스텝ⅰ> 비즈니스 룰 확인
- <스텝ⅱ> 분석용 데이터 셋 준비: 데이터 스토어로부터 분석에 필요한 정형·비정형 데이터를 추출
- [태스크②] 텍스트 분석 - 텍스트 = 비정형 데이터
- <스텝ⅰ> 텍스트 데이터 확인 및 추출: 데이터 스토어에서 필요한 텍스트 데이터를 추출
- [태스크③] 탐색적 분석 - 우리가 가진 분석용 데이터 셋이 지금 어떻게 생겼는가를 파악하는 단계
- <스텝ⅰ> 탐색적 데이터 분석(EDA) : 기초 통계량(평균, 분산, 표준편차 등)을 산출, 데이터 자체의 특성을 파악
- <스텝ⅱ> 데이터 시각화
- [태스크④] 모델링⭐ - 다른 태스크보다 조금 더 중요
- <스텝ⅰ> 데이터 분할: 모델의 과적합과 일반화를 위해 분석용 데이터 셋을 모델 개발을 위한 훈련용 데이터와 모델의 검증력을 테스트하기 위한 테스트용 데이터로 분할함 (훈련용 데이터, 테스트용 데이터)
- <스텝ⅱ> 데이터 모델링
- <스텝ⅲ> 모델 적용 및 운영 방안 (알고리즘 설명서 작성)
- [태스크⑤] 모델 평가 및 검증
- <스텝ⅰ> 모델 평가
- <스텝ⅱ> 모델 검증
- [태스크①] 분석용 데이터 준비
- 4️⃣시스템 구현 - 반드시 하는 것은 아님! 필요하면 수행함
: 설계 및 구현. 시스템 개발은 위한 사전 검증으로 프로토타입 시스템을 구현함
- [태스크①] 설계 및 구현
- <스텝ⅰ> 시스템 분석 및 설계: 가동중인 시스템을 분석하고 알고리즘 설명서에 근거하여 응용시스템 구축 설계 프로세스를 진행
- <스텝ⅱ> 시스템 구현: 설계된 모델을 구현
- [태스크②] 시스템 테스트 및 운영
- [태스크①] 설계 및 구현
- 5️⃣평가 및 전개
: 프로젝트의 성과를 평가 및 보고- [태스크①] 모델 발전 계획 수립
- [태스크②] 프로젝트 평가 및 보고 (최종 보고서 작성)
- 1️⃣분석 기획
분석 과제 발굴
분석 과제 발굴의 개요
- 분석 과제를 도출하기 위한 방식은 크게 하향식 접근 방법과 상향식 접근 방법이 있음
- 하향식 접근 방법
- 문제가 주어진 상태에서 답을 구하는 방식
- 전통적으로 수행돼 온 분석 과제 발굴 방식
- 상향식 접근 방법
- 갈수록 문제 자체의 변화가 심해 정확하게 문제를 사전에 정의하는 것이 어려워지고 있음
- 분석 대상을 정확히 모르는 상태에서 접근하는 방식
- 하향식 접근 방법
- 실제 의사결정 할 때 하향식과 상향식을 혼용함
하향식 접근 방법
- 문제 탐색 → 문제 정의 → 해결 방안 탐색 → 타당성 평가
- 문제 탐색
- 전체적인 관점의 기준 모델을 활용하여 빠짐없이 문제를 도출하고 식별하는 것이 중요
- 과제 발굴 단계에서는 문제를 해결함으로써 발생하는 가치에 중점을 두는 것이 중요
- 1) 비즈니스 모델 기반 문제 탐색
: 비즈니스모델 캔버스의 9가지 블록을 단순화하여 업무(Operation), 제품(Product), 고객(Customer) 단위로 문제를 발굴하고 이를 관리하는 규제와 감사(Audit & Regulation)영역과 지원 인프라 (IT & Human Rasource) 두 가지 영역에 대한 기회를 추가로 도출하는 작업을 수행 - 2) 분석 기회 발굴의 범위를 확장 (각 관점을 고려하며 문제를 발굴)
- 거시적 관점 : 사회, 기술, 경제, 환경, 정치
- 경쟁자 확대 관점 : 위협이 될 수 있는 상황에 대한 분석 기회 발굴의 폭을 넓혀서 탐색
- 시장의 니즈 탐색 관점
- 역량의 재해석 관점
- 문제 정의
- 비즈니스 문제를 데이터의 문제로 변환하여 정의함
- 해결 방안 탐색
- 해결 방안 탐색 프로세스 (밑에 도표 참고
- 타당성 검토
- 문제 탐색

상향식 접근 방법
- 다양한 원천 데이터로부터 통찰과 지식을 얻는 접근 방법
- 먼저 분석을 시작하고 그 결과로부터 가치가 있는 문제를 도출하는 방법
- 디자인 사고는 수렴과 발산을 반복하며 창의적인 아이디어를 도출하는 방식
- 디자인 사고에서 첫 단계로 감정이입을 특히 강조함
- 일반적으로 상향식 접근방식의 데이터 분석은 비지도학습에 의해 수행
- 비지도 학습: 정답을 알려주지 않고 학습하는 것
- 시행착오를 통한 문제 해결 (프로토타이핑 접근법)
- 사용자가 요구사항이나 데이터를 정확히 규정하기 어렵고 데이터 소스도 명확히 파악하기 어려운 상황에서 일단 분석을 시도해 보고 그 결과를 확인해 가면서 반복적으로 개선해 나가는 방법
분석 프로젝트 관리
- 분석 과제의 5가지 속성을 고려한 관리
- 데이터의 양
- 데이터의 복잡도
- 분석의 속도
- 분석 복잡도
- 정확도 & 정밀도
- 정확도: 모델과 실제 값 간 차이가 적은 정도
- 정밀도: 반복적으로 모델을 사용했을 때 모델 값들의 편차 수준
- 분석의 활용적인 측면에서는 정확도가 중요, 분석의 안정성 측면에선 정밀도가 중요
- 분석 과제 관리 방안
- 관리 영역 중 '시간':
- Time Boxing 기법으로 일정관리를 진행하는 것이 필요(철저한 통제 X)
- Time Boxing: 현재 할당된 작업이 주어진 시간 동안 완수되지 못하였더라도 다음 작업으로 넘어가는 방법
- Time Boxing 기법으로 일정관리를 진행하는 것이 필요(철저한 통제 X)
- 관리 영역 중 '시간':

지금 시각은 1시 6분. 이제 그만 자고 싶다..
그치만 잘 수 없고 할 일을 하러 떠나야 하는 현실이 믿기지 않는다.
'[내배캠] 데이터분석 6기 > 본캠프 기록' 카테고리의 다른 글
| [본캠프 10일차] ADsP 공부, SQL 공부, 코드카타 복습(SQL만) (0) | 2025.02.28 |
|---|---|
| [본캠프 9일차] 아티클 스터디④, 파이썬 코드카타, SQL 코드카타, ADsP 공부 (0) | 2025.02.27 |
| [본캠프 6일차] 팀플 주제 선정, 파이썬 코드카타, SQL 코드카타, SQL 공부, ADsP 공부 (0) | 2025.02.24 |
| [본캠프 5일차] SQL 공부, 코드카타 복습(SQL, 파이썬), ADsP 공부 (0) | 2025.02.21 |
| [본캠프 4일차] 파이썬 코드카타, 아티클 스터디②, ADsP 공부 (0) | 2025.02.20 |