마참내 금요일
3일 쉰다

사실 금요일이라고 집중력은 그렇게 좋아지지 않았지만(진짜 왜지) 그래도 기분은 좋았으니까 오케이.
오늘은 2주차 팀 과제 발표회도 있고, 2월의 마지막 날이기도 하고, ⭐앞으로 3일 쉴 수 있고 ⭐ 그래서 뭔가 날도 차분하니 마무리 느낌이 물씬 나는 날이었다.

근데 ADsP 강의 듣는데 또 설치해야 하는 상황이 생겼다.
잠깐.. 여기서 또 뭘 설치하라니요... 노트북 ㄹㅇ 죽을지도 몰라.
이미 이번 주에 기초 분석 과제를 하면서 노트북이 문제가 많아졌다.
지난 주에는 Out of memory 메시지만 만났는데 이번 주는 정말 다양한 메시지가 뜨면서 크롬 창이 하얗게 맛이 가버리고 zep도 마이크가 안 되고 인터넷 창들도 강제 종료를 하루에도 몇 번씩 겪는다.

…그래도 내게 선택지가 없지. 일단 시키는 대로 깔긴 깔았다.
얼른 노트북 대여 신청한 거 왔으면 좋겠다. 3월에는 새 노트북과 함께 시작할 줄 알았는데 언제 올까...?
오늘 한 일은,
- [ADsP 자격증 챌린지] 4주차 완강하기(4-2~4-4)
- 팀 과제(2주차: 기초 분석) 발표회 참석하기
ADsP 공부: [ADsP 자격증 챌린지] 4주차 수강하기 (4-2~4-4)
( 👇 [ADsP 자격증 챌린지] 4주차 강의의 앞선 부분 정리한 글 👇 )
[본캠프 9일차] 아티클 스터디④, 파이썬 코드카타, SQL 코드카타, ADsP 공부
제발 오늘은 일찍 자자…오늘 한 일은,네 번째 아티클 스터디 진행하기 (누적은 15번)팀 과제 PPT 발표 자료 피드백 수렴 및 최종본 확정하기파이썬 공부[코드카타] 파이썬 2문제 풀기(39~40번)SQL 공
maandoo.tistory.com
분석 거버넌스 체계 수립
분석 거버넌스 체계 개요
- 분석 거버넌스(governance)
- 의사결정을 위한 데이터의 분석과 활용을 위한 체계적인 관리, 일정한 규칙과 규범
- 어떤 목적으로 어떤 데이터를 어떻게 분석에 활용할 것인가가 중요
- 분석 거버넌스 체계 구성요소
- 조직(Organization)
- 과제 기획 및 운영 프로세스(Process)
- 분석 관련 시스템 (System)
- 데이터(Data)
- 분석 관련 교육 및 마인드 육성 체계(Human Resource)
데이터 분석 성숙도 모델 및 수준 진단
- 분석 수준 진단은 분석 준비도와 분석 성숙도를 통해 진단
- 분석 준비도(Readiness)
- 기업의 데이터 분석 도입의 수준을 파악하기 위한 진단 방법
- 진단 영역별로 세부 항목에 대한 수준을 파악
; ①분석 업무 파악, ②인력 및 조직, ③분석 기법, ④분석 데이터, ⑤분석 문화, ⑥IT 인프라 - 전체 요건 중 일정 수준 이상 충족하면 분석 업무를 도입하고, 충족하지 못하면 먼저 분석 환경을 조성
- 진단 영역별로 세부 항목에 대한 수준을 파악
- 기업의 데이터 분석 도입의 수준을 파악하기 위한 진단 방법

- 분석 성숙도(Maturity)
- 비즈니스 부문, 조직 및 역량 부문, IT 부문의 3개 부문을 대상으로 성숙도 수준을 나누어 봄

- 분석 수준 진단 결과
- 분석 준비도와 분석 성숙도를 진단한 결과를 토대로 기업의 현재 분석 수준을 객관적으로 파악할 수 있음
; 확산형, 정착형, 준비형, 도입형
- 분석 준비도와 분석 성숙도를 진단한 결과를 토대로 기업의 현재 분석 수준을 객관적으로 파악할 수 있음

분석 거버넌스 체계 수립
- 데이터 거버넌스
: 전사 차원의 모든 데이터에 대해 정책 및 지침, 표준화, 운영 조직 및 책임 등의 표준화된 관리 체계를 수립하고 운영을 위한 프레임워크(Framework) 및 저장소(Repository)를 구축하는 것 - 중요 관리 대상 : 마스터 데이터(Master Data), 메타 데이터(Meta Data), 데이터 사전(Data Dictionary)
- 구성 요소 : 원칙, 조직, 프로세스
- 데이터 거버넌스 체계
- 데이터 표준화
- 업무 구성
: 데이터 표준 용어 설정, 명명 규칙(Name Rule) 수립, 메타데이터(Metadata) 구축, 데이터 사전(Data Dictionary) 구축 등 - 데이터 표준 용어는 표준 단어 사전, 표준 도메인 사전, 표준 코드 등으로 구성되며 사전 간 상호 검증이 가능하게 점검 프로세스를 포함
- 명명 규칙은 필요시 언어별(한글, 영어 등)로 작성되어 매핑 상태를 유지
- 업무 구성
- 데이터 관리 체계
- 데이터 정합성 및 활용의 효율성을 위하여 표준 데이터를 포함한 메타 데이터와 데이터 사전의 관리 원칙을 수립
- 수립된 원칙에 근거하여 항목별 상세한 프로세스를 만들고 관리와 운영을 위한 담당자 및 조직별 역할과 책임을 상세하게 준비
- 빅데이터의 경우 데이터 양의 급증으로 데이터의 생명 주기 관리방안(Data Life Cycle Management)을 수립하지 않으면 데이터 가용성 및 관리비용 증대 문제에 직면할 수도 있음
- 데이터 저장소 관리(Repository)
- 메타데이터 및 표준 데이터를 관리하기 위한 전사 차원의 저장소를 구성
- 저장소는 데이터 관리 체계 지원을 위한 워크플로우 및 관리용 응용소프트웨어(Application)을 지원하고 관리 대상 시스템과의 인터페이스를 통한 통제가 이루어져야 함
- 데이터 구조 변경에 따른 사전 영향 평가도 수행돼야 효율적인 활용이 가능함
- 표준화 활동
- 데이터 거버넌스 체계를 구축한 후 표준 준수 여부를 주기적으로 점검하고 모티터링을 실시함
- 거버넌스의 조직 내 안정적 정착을 위한 계속적인 변화관리 및 주기적인 교육을 진행함
- 지속적인 데이터 표준화 개선 활동을 통하여 실용성을 높여야 함
- 데이터 표준화
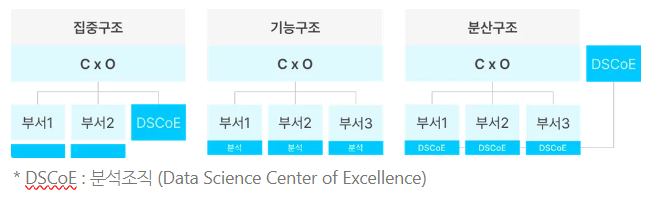
- 데이터 분석 조직 유형
- ① 집중형 조직 구조
- 조직 내에 별도의 독립적인 분석 전담조직을 구성하고, 회사의 모든 분석 업무를 전담 조직에서 담당
- ② 기능 중심의 조직 구조
- 일반적으로 분석을 수행하는 형태이며, 별도로 분석 조직을 구성하지 않고 각 해당 업무 부서에서 직접 분석하는 형태
- ③ 분산된 조직 구조
- 분석 조직의 인력들을 현업부서에 배치해 분석 업무를 수행하는 형태
- ① 집중형 조직 구조
분석 과제 관리 프로세스 수립 및 교육/변화 관리
- 분석 과제 관리 프로세스
- 과제 발굴 단계
: 개별 조직이나 개인이 도출한 분석 아이디어를 발굴하고 이를 과제화하여 분석 과제 풀(Pool)로 관리하면서 분석 프로젝트를 선정하는 작업을 수행 - 과제 수행 단계
: 분석을 수행할 팀을 구성하고 분석 과제 실행 시 지속적인 모니터링과 과제 결과를 공유하고 개선하는 절차를 수행
- 과제 발굴 단계

(2과목 파트 끝!)
R 다루기
R 데이터의 구조
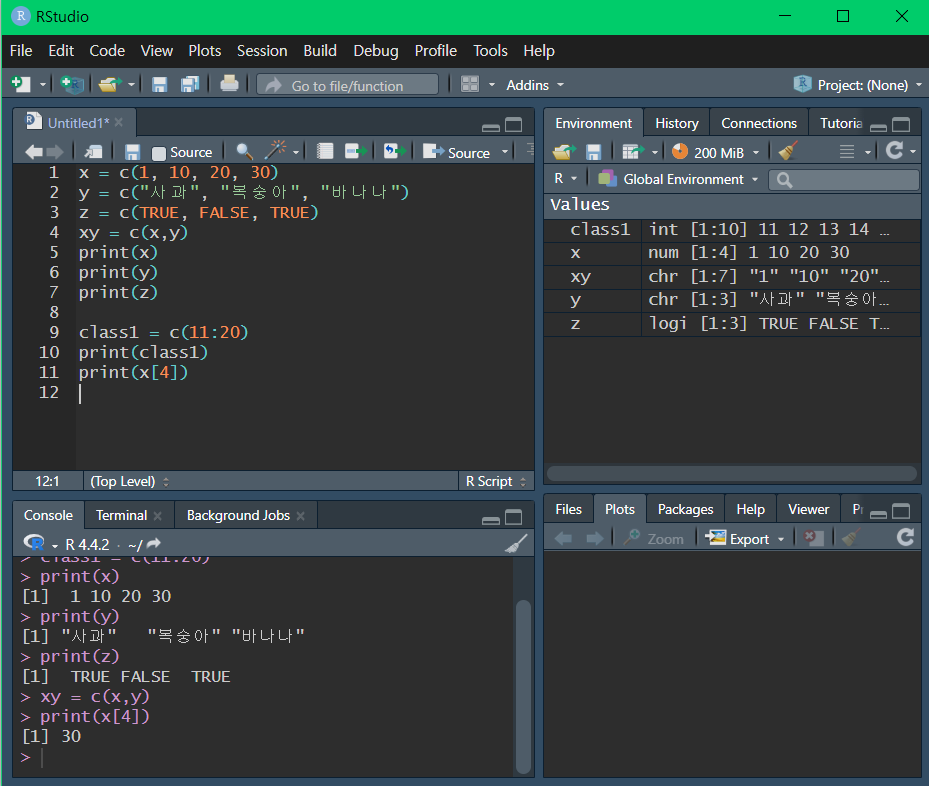
- 벡터
- 타입이 같은 여러 데이터를 하나의 행으로 저장하는 1차원 데이터 구조
- 문자형 벡터가 포함되면 합쳐지는 벡터는 문자형 벡터가 됨
- 일일이 입력하지 않고 콜론(:)을 사용해 시작값과 끝값을 지정해 벡터를 생성할 수 있음
- 벡터는 위치로 인덱스됨 (a[2] : a벡터의 두 번째 원소)
- 할당 연산자로 등호(=) 대신 화살표(<-)를 사용할 수 있음
- 타입
- 문자 타입
- 숫자형 타입
- 논리형 타입: True(1), False(0)
- 타입이 같은 여러 데이터를 하나의 행으로 저장하는 1차원 데이터 구조
SQL 공부: [예제로 익히는 SQL] 4·5회차
4·5회차 과제
이번 과제는 3문제는 코드카타로 매일 푸는 프로그래머스의 SQL 문제, 3문제는 튜터님이 내신 문제로 총 6문제다.
그런데 프로그래머스 문제들의 경우는 이미 매일 코드카타를 하며 이미 푼 문제들이어서 새로이 푼 문제들을 위주로 쿼리를 작성해나간 간 과정을 적어보았다.
1. 오랜 기간 보호한 동물(1)
| 아직 입양을 못 간 동물 중, 가장 오래 보호소에 있었던 동물 3마리의 이름과 보호 시작일을 조회하는 SQL문을 작성해주세요. 이때 결과는 보호 시작일 순으로 조회해야 합니다. |
SELECT ai.name,
ai.datetime
FROM animal_ins ai LEFT JOIN animal_outs ao ON ai.animal_id = ao.animal_id
WHERE ao.animal_type IS NULL
ORDER BY ai.datetime LIMIT 3
2. 조건에 맞는 사용자와 총 거래금액 조회하기
| USED_GOODS_BOARD와 USED_GOODS_USER 테이블에서 완료된 중고 거래의 총금액이 70만 원 이상인 사람의 회원 ID, 닉네임, 총거래금액을 조회하는 SQL문을 작성해주세요. 결과는 총거래금액을 기준으로 오름차순 정렬해주세요. |
SELECT ugu.user_id,
ugu.nickname,
sum(ugb.price) total_sales
FROM used_goods_board ugb LEFT JOIN used_goods_user ugu ON ugb.writer_id = ugu.user_id
WHERE ugb.status = 'DONE'
GROUP BY 1
HAVING sum(ugb.price) >= 700000
ORDER BY 3
3. 보호소에서 중성화한 동물
| 보호소에서 중성화 수술을 거친 동물 정보를 알아보려 합니다. 보호소에 들어올 당시에는 중성화되지 않았지만, 보호소를 나갈 당시에는 중성화된 동물의 아이디와 생물 종, 이름을 조회하는 아이디 순으로 조회하는 SQL 문을 작성해주세요. |
SELECT ao.animal_id,
ao.animal_type,
ao.name
FROM animal_outs ao LEFT JOIN animal_ins ai ON ao.animal_id=ai.animal_id
WHERE (ai.sex_upon_intake LIKE 'Intact%')
AND (ao.sex_upon_outcome NOT LIKE 'Intact%')
4. JOIN 활용
| 조건1) 알맞은 join 방식을 사용하여 users 테이블을 기준으로, payment 테이블을 조인해주세요. 조건2) case when 구문을 사용하여 결제를 한 유저와 결제를 하지 않은 게임계정을 구분해주시고, 컬럼이름을 gb로 지정해주세요. 조건3) gb를 기준으로 게임계정수를 추출해주세요. 컬럼 이름은 usercnt로 지정해주시고, 결과값은 아래와 같아야 합니다. 힌트: 기준이 되는 테이블의 데이터는 그대로 두어야겠죠? |
SELECT CASE WHEN p.pay_amount IS NOT NULL THEN '결제를 한 유저'
ELSE '결제하지 않은 유저' END gb,
count(*) usercnt
FROM basic.users u LEFT JOIN basic.payment p ON u.game_account_id = p.game_account_id
GROUP BY 1
조건 1을 충족하기 위해 LEFT JOIN으로 두 테이블을 합쳤다.
조건 2에서 요구하는 대로 gb 컬럼을 CASE WEHN 구문을 사용해서 작성했다.
이때 조건으로 결제를 하지 않았다면 payment 테이블의 pay_amount, pay_type, approved_at 컬럼의 내용이 NULL값일 테니 이 점을 활용했다.
그리고 gb 컬럼의 각 값에 부합하는 게임 계정 수를 세기 위해 COUNT(*)를 사용하고 GROUP BY절에 gb 컬럼을 적어 이 기준으로 각각 집계하도록 의도했다.
그런데 제출하기 전에 COUNT(*)가 맞는지 의문이 생겼다.
그래서 이 부분을 'DISTINCT COUNT(*)', 'COUNT(u.game_accont_id)', 'DISTINCT COUNT(u.game_account_id)' 등으로 수정해서 전부 조회해봤는데,
- COUNT(u.game_account_id) : COUNT(*)와 같은 결과 테이블이 조회됨
- DISTINCT COUNT(*) : SQL syntax 에러
- DISTINCT COUNT(u.game_account_id) : SQL syntax 에러
위와 같은 결과에 따라 굳이 최종 SQL문을 수정하지 않기로 했다.
5. JOIN 응용1
| 조건1) users 테이블에서 서버번호가 2 이상인 데이터와 payment 테이블에서 결제방식이 CARD 모두를 만족하는 경우를 알맞은 방식으로 join 해 주세요. payment 테이블의 매출 금액이 중복되는 것을 방지하기 위해 모든 값을 고유하게 추출해야 합니다. 조건2) 조인한 결과를 바탕으로 users 테이블의 game_account_id 를 기준으로 game_actor_id수를 중복값없이 세고 컬럼 이름을 actor_cnt로 지정해주세요. 또한 pay_amount 값을 더해주시고, 컬럼 이름을 sumamount로 지정해주세요. 조건3) having 을 사용하지 않고, 인라인 뷰 subquery 사용으로 actor_cnt수가 2 이상인 경우만 추출해주세요. 그리고 sumamount를 기준으로 내림차순 정렬해주세요. |
SELECT *
FROM(
SELECT *
FROM basic.users
WHERE serverno >= 2
) u
INNER JOIN
(
SELECT *
FROM basic.payment
WHERE pay_type = 'CARD'
) p
ON u.game_account_id = p.game_account_id조건 1을 충족하기 위해 users 테이블도 WHERE절로 조건을 걸고, payment 테이블로 WHERE절로 조건을 걸어서
이 상태를 서브쿼리로 묶어서 매출 금액이 중복되는 것을 방지해달라기에 INNER JOIN을 사용했다.
SELECT u.game_account_id,
COUNT(u.game_actor_id) actor_cnt,
SUM(p.pay_amount) sumamoount
FROM(
SELECT *
FROM basic.users
WHERE serverno >= 2
) u
INNER JOIN
(
SELECT *
FROM basic.payment
WHERE pay_type = 'CARD'
) p
ON u.game_account_id = p.game_account_id
GROUP BY 1조건 2를 충족하기 위해 SELECT절에 조회될 컬럼을 작성했고,
COUNT() 함수와 SUM() 함수가 u.game_account_id별로 연산하도록 GROUP BY절을 작성했다.
SELECT *
FROM(
SELECT u.game_account_id,
COUNT(u.game_actor_id) actor_cnt,
SUM(p.pay_amount) sumamount
FROM(
SELECT *
FROM basic.users
WHERE serverno >= 2
) u
INNER JOIN
(
SELECT *
FROM basic.payment
WHERE pay_type = 'CARD'
) p
ON u.game_account_id = p.game_account_id
GROUP BY 1
) gai
WHERE gai.actor_cnt >= 2
ORDER BY gai.sumamount DESC마지막으로 조건 3까지 쿼리에 반영하기 위해 전부 묶어서 FROM절에 넣어 인라인 뷰로 처리했다.
WHERE절 추가해 actor_cnt 2 이상인 데이터만 조회되도록 하고, ORDER BY로 정렬 조건까지 기입함으로써 완료했다.
6. JOIN 응용2
| 조건1) user 테이블에서 game_account_id, first_login_date, serverno 를 추출한 결과와 조건2) payment 테이블에서 game_account_id 별 가장 마지막 결제일자를 찾고 그 컬럼이름을 date2로 지정해주세요. 그 다음 inner join 을 진행해주세요. 다만, 첫 접속일자보다 마지막 결제일자가 큰 경우만 추출해주세요. 조건3) 조인 결과를 바탕으로 마지막 결제일자-첫 접속일자 를 구해주세요. 그리고 컬럼이름을 diffdate로 설정해주세요. 두 날짜의 형식은 같아야 합니다. 조건4) 인라인 뷰 subquery 를 이용하여 서버별 평균 diffdate를 구해주시고, 컬럼이름을avgdiffdate로 설정해주세요. 해당컬럼은 정수 형태로 출력되어야 합니다. 조건5) 조건절에 diffdate 값이 10일 이상인 경우를 필터링해주세요. 그리고 서버번호를 기준으로 내림차순 정렬해주세요. 힌트) 소수점을 반올림해주는 round 함수를 활용해주세요! |
SELECT *
FROM(
SELECT game_account_id,
first_login_date,
serverno
FROM basic.users
) u
INNER JOIN
(
SELECT game_account_id,
MAX(approved_at) date2
FROM basic.payment
GROUP BY 1
) p
ON u.game_account_id = p.game_account_id
WHERE p.date2 > u.first_login_date조건 1에서 요구하는 대로 users 테이블에서 일부 컬럼만 추출하고, 조건 2를 위해 payment 테이블 역시 요구한 형태로 조회하여 둘을 INNER JOIN을 했다. 그리고 WHERE절에 p.date2가 u.first_login_date보다 클 때만 조회되도록 했다.
SELECT DATEDIFF(p.date2, u.first_login_date) datediff
FROM(
SELECT game_account_id,
DATE_FORMAT(first_login_date, '%Y-%m-%d') first_login_date,
serverno
FROM basic.users
) u
INNER JOIN
(
SELECT game_account_id,
DATE_FORMAT(MAX(approved_at), '%Y-%m-%d') date2
FROM basic.payment
GROUP BY 1
) p
ON u.game_account_id = p.game_account_id
WHERE p.date2 > u.first_login_date조건 3을 위해 DATEDIFF() 함수를 사용해서 p.date2에서 u.first_login_date를 빼줬다.
그리고 두 날짜 데이터의 형식이 같아야 한다길래 DATE_FORMAT() 함수를 사용해 동일한 형태로 맞춰주었다.
SELECT sdd.serverno,
ROUND(AVG(sdd.diffdate)) avgdiffdate
FROM(
SELECT u.serverno,
DATEDIFF(p.date2, u.first_login_date) diffdate
FROM(
SELECT game_account_id,
DATE_FORMAT(first_login_date, '%Y-%m-%d') first_login_date,
serverno
FROM basic.users
) u
INNER JOIN
(
SELECT game_account_id,
DATE_FORMAT(MAX(approved_at), '%Y-%m-%d') date2
FROM basic.payment
GROUP BY 1
) p
ON u.game_account_id = p.game_account_id
WHERE p.date2 > u.first_login_date
) sdd
GROUP BY 1조건 4를 충족하기 위해 서버별 평균 일수를 계산하도록 했다.
SELECT sdd.serverno,
ROUND(AVG(sdd.diffdate)) avgdiffdate
FROM(
SELECT u.serverno,
DATEDIFF(p.date2, u.first_login_date) diffdate
FROM(
SELECT game_account_id,
DATE_FORMAT(first_login_date, '%Y-%m-%d') first_login_date,
serverno
FROM basic.users
) u
INNER JOIN
(
SELECT game_account_id,
DATE_FORMAT(MAX(approved_at), '%Y-%m-%d') date2
FROM basic.payment
GROUP BY 1
) p
ON u.game_account_id = p.game_account_id
WHERE p.date2 > u.first_login_date
) sdd
WHERE sdd.diffdate >= 10
GROUP BY 1
ORDER BY 1 DESC

마지막으로 조건 5까지 충족하기 위해 WHERE절과 ORDER BY절을 추가하면 이렇게 완성된다.
코드카타 복습하기
이번 주 동안 푼 문제들을 다시 풀어보면서 막히는 문제들을 체크했다.
SQL : 21~40번

없 ! 다 !
오늘 있었던 팀 발표회 피드백 반영해서 회고와 코드카타 파이썬 문제들(27~40번)도 복습하려면 내일도 좀 공부해야겠다.
'[내배캠] 데이터분석 6기 > 본캠프 기록' 카테고리의 다른 글
| [본캠프 12일차] ADsP 공부, 데이터 리터러시 공부, 파이썬 코드타카, SQL 코드카타 (0) | 2025.03.05 |
|---|---|
| [본캠프 11일차] ADsP 공부, SQL 공부, SQL 코드카타, 파이썬 코드카타, 아티클 스터디 ① (0) | 2025.03.04 |
| [본캠프 9일차] 아티클 스터디④, 파이썬 코드카타, SQL 코드카타, ADsP 공부 (0) | 2025.02.27 |
| [본캠프 7일차] 아티클 스터디③, 파이썬 코드카타, SQL 공부, ADsP 공부 (2) | 2025.02.25 |
| [본캠프 6일차] 팀플 주제 선정, 파이썬 코드카타, SQL 코드카타, SQL 공부, ADsP 공부 (0) | 2025.02.24 |