
오늘 한 일은,
- SQL 공부
- [코드카타] 3문제 풀기 (110~112번)
- 파이썬 공부
- [코드카타] 알고리즘 1문제 풀기 (67번)
- 통계학 공부
- [통계 라이브 세션] 1회차 수강하기
- [기초 통계학] 3주차 수강하기
- 첫 번째 아티클 스터디 진행하기 (누적은 21번째(11+4+5+1))
SQL 공부: [코드카타] SQL 문제 풀기 (110~112번)
110. (1164) Product Price at a Given Date
Write a solution to find the prices of all products on 2019-08-16. Assume the price of all products before any change is 10.
Return the result table in any order.
-- 제출한 쿼리 (정답 처리됨)
SELECT DISTINCT pi.product_id,
IFNULL(np.new_price, 10) price
FROM (
SELECT product_id
FROM Products
) pi
LEFT JOIN (
SELECT product_id,
new_price
FROM Products
WHERE (change_date <= '2019-08-16') AND
((product_id, change_date) IN (
SELECT product_id,
MAX(change_date) OVER(PARTITION BY product_id)
FROM Products
WHERE change_date <= '2019-08-16'))
) np
ON pi.product_id = np.product_id쿼리를 작성한 순서는,
- ① 2019년 8월 16일 기준으로 해당 제품 ID별로 가격을 변경한 가장 최근 일자를 조회해서 product_id, new_price 컬럼을 조회
- ② Products 테이블에서 product_id 컬럼만 조회
- ③ ②를 pi라는 서브쿼리로 묶고, ①을 np라는 서브쿼리로 묶어서 pi에 np를 product_id 컬럼 기준으로 LEFT JOIN함
- ④ ③의 상태에서 pi.product_id를 중복값 없이 조회하고, np.new_price를 price라는 이름으로 조회
- 이때 price 컬럼이 NULL일 경우 10으로 값을 대체함
이런 순서로 작성했다.
111. (1204) Last Person to Fit in the Bus
There is a queue of people waiting to board a bus. However, the bus has a weight limit of 1000 kilograms, so there may be some people who cannot board.
Write a solution to find the person_name of the last person that can fit on the bus without exceeding the weight limit. The test cases are generated such that the first person does not exceed the weight limit.
Note that only one person can board the bus at any given turn.
-- 제출한 쿼리 (정답 처리됨)
WITH cq AS ( -- 우선 turn 순서대로 몸무게를 누계한 컬럼이 포함된 테이블을 WITH 구문으로 만듦
SELECT *,
SUM(weight) OVER(ORDER BY turn) cumulative_total
FROM Queue
)
SELECT person_name
FROM cq
WHERE (cumulative_total <= 1000) AND -- 조건1. 몸무게 누계가 1000 이하일 것
((turn) = ( -- 조건2. 그 중에서 순서가 가장 마지막일 것
SELECT MAX(turn)
FROM cq
WHERE cumulative_total <= 1000
))처음부터 WITH 구문을 사용해서 작성했던 것은 아니고 작성하다보니 계속 반복되는 부분을 아예 빼놓는 게 쿼리 가독성이 좋을 것 같아서 cumulative_total 컬럼을 추가한 가상의 테이블 cq를 만들어놓고 쿼리를 작성했다.
112. (1907) Count Salary Categories
Write a solution to calculate the number of bank accounts for each salary category. The salary categories are:
- "Low Salary": All the salaries strictly less than $20000
- "Average Salary": All the salaries in the inclusive range [$20000, $50000]
- "High Salary": All the salaries strictly greater than $50000
The result table must contain all three categories. If there are no accounts in a category, return 0.
Return the result table in any order.
-- 처음 작성한 쿼리 (오답 처리됨)
SELECT s.category,
COUNT(category) accounts_count
FROM (
SELECT *,
CASE WHEN income < 20000 THEN 'Low Salary'
WHEN income BETWEEN 20000 AND 50000 THEN 'Average Salary'
WHEN income > 50000 THEN 'High Salary' END category
FROM Accounts
) s
GROUP BY s.category
처음 작성한 쿼리는 위와 같이 해당 카테고리에 집계할 값이 없으면 아예 결과 테이블에서 조회되지 않아서 틀렸다.
CREATE TABLE과 INSERT INTO로 테이블을 만들어서 그 테이블과 JOIN해볼까 싶었지만 테이블 만드는 데서 에러가 발생했다. 그래서 더 찾아보니 WITH 구문에 UNION을 사용해서 내게 필요한 카테고리들이 들어간 테이블을 만들 수 있었다.
[참고] [MYSQL] 📚 WITH (임시 테이블 생성)
-- 두 번째 시도한 쿼리 (정답 처리됨)
WITH c AS ( -- 카테고리 항목들이 들어간 가상의 테이블 c를 생성
SELECT 'Low Salary' category
UNION
SELECT 'Average Salary' category
UNION
SELECT 'High Salary' category
)
SELECT c.category,
IFNULL(cc.accounts_count, 0) accounts_count
FROM c c -- 위에서 만든 가상의 테이블 c에 처음 시도한 쿼리의 결과 테이블(=cc)을 LEFT JOIN으로 연결
LEFT JOIN (
SELECT s.category,
COUNT(category) accounts_count
FROM (
SELECT *,
CASE WHEN income < 20000 THEN 'Low Salary'
WHEN income BETWEEN 20000 AND 50000 THEN 'Average Salary'
WHEN income > 50000 THEN 'High Salary' END category
FROM Accounts
) s
GROUP BY s.category
) cc
ON c.category = cc.category수정한 쿼리는,
- ① WITH 구문으로 카테고리의 모든 값이 들어간 가상의 테이블 c를 만듦
- ② c에 처음 시도한 쿼리의 결과 테이블(cc)을 category 컬럼을 기준으로 LEFT JOIN함
- ③ c의 category 컬럼과 cc의 accounts_count 컬럼을 조회
- NULL값일 경우 숫자 0으로 대체
오늘은 어쩌다보니 WITH 구문을 사용해 쿼리를 작성하는 문제들을 풀게 됐다. WITH 구문에 더 익숙해져야겠다.
통계학 공부①: [통계 라이브세션] 1회차 수강하기

오늘은 통계 라이브세션의 첫 번째 시간이었다. 미리 온라인 강의로 2주차까지 수강한 상태에서 들어서 복습 같은 느낌으로 들으니 수월하게 수업을 들었다. 배운 주요 개념들을 간단히 정리하고, 이해가 잘 안 됐거나 궁금한 점들은 추가적으로 공부했다.
편차, 분산, 표준 편차
평균, 중앙값, 최빈값 vs 편차, 분산, 표준 편차
- 평균, 중앙값, 최빈값 : 데이터의 Where 어디에 존재하는가
- 편차, 분산, 표준편차 : 데이터의 How 어떻게 존재하는가
편차(deviation)
- 편차 = (전체 중 하나의 값) - (전체의 평균)
- 평균으로부터 얼마나 떨어져 있는지
분산(variance)
- 분산 = (편차)²들의 평균
- 편차를 그냥 더하면 0이 나오는 것을 방지하기 위해 분산 개념이 생김
표준 편차(standard deviation)
- 표준편차 = √(분산)
- 원래 단위로 돌려 직관적으로 이해할 수 있는 수로 나타내기 위함
정규 분포, 신뢰 구간
정규 분포 (normal distribution)

- 평균을 중심으로 좌우 대칭의 형태
- 곡선은 각 확률값을 나타냄
- 평균과 분산에 따라 정규 분포의 형태는 달라짐
- 표준 정규 분포(z-분포) : 평균이 0, 분산이 1인 정규 분포 위의 그림에서 붉은색 그래프
- 표준화 : 서로 다른 평균, 표준 편차를 지닌 정규 분포를 비교할 수 있게 표준 정규 분포의 평균(0)과 분산(1)으로 통일하는 작업
- 표준화된 개별 데이터(z-score) = (개별 데이터) - (해당 데이터 전체의 평균) / (표준 편차)
- 데이터 분석 시, 데이터의 범위가 많이 차이 날 때에 표준화 작업이 필요
신뢰 구간
- 신뢰 구간 : 특정 범위 내에 값이 존재할 것으로 예측하는 영역
- 신뢰 수준 : 몇 퍼센트의 확률로 신뢰구간에 실제 모수를 포함하게 되는 확률
- 주로 95%, 99%를 사용함
- 신뢰 수준이 높아지면 그만큼 신뢰 구간이 넓어지기에 정확한 예측이 어려움
통계학 공부②: [기초 통계학] 3주차 수강하기
유의성 검정 방법
A/B 검정
- 두 버전 중 어느 것이 더 효과적인지 평가하기 위해 사용 두 그룹 간의 차이가 우연이 아니라 통계적으로 유의미한가
- 사용자들을 두 그룹으로 나누고 → 각 그룹에 다른 버전을 제공한 후 → 반응을 비교
- 마케팅, 웹사이트 디자인 등에서 많이 사용됨
- 전환율, 클릭률, 구매수, 방문 기간, 방문한 페이지 수, 특정 페이지 방문 여부, 매출 등의 지표를 비교
import numpy as np
import scipy.stats as stats
# 가정된 전환율 데이터
group_a = np.random.binomial(1, 0.30, 100) # 30% 전환율
group_b = np.random.binomial(1, 0.45, 100) # 45% 전환율
# t-test를 이용한 비교
t_stat, p_val = stats.ttest_ind(group_a, group_b)
print(f"T-Statistic: {t_stat}, P-value: {p_val}")- .ttest_ind() : 독립 표본 t-검정(Independent Samples t-test)을 수행해 두 개의 독립된 집단 간 평균의 차이가 유미의한지를 평가
- 두 집단의 데이터 배열을 인수로 받아서 t-통계량과 p-value를 반환함
- 일반적으로 p-value가 0.05보다 작을 때 나타난 결과가 유의미하다고 판단함
가설 검정
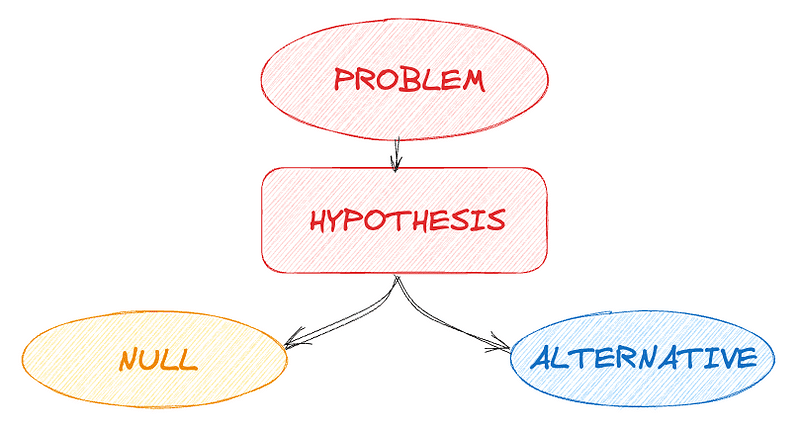
- 표본 데이터를 통해 모집단의 가설을 검증
- 데이터가 특정 가설을 지지하는지 평가
- 귀무가설(H0)과 대립가설(H1)을 설정
- 귀무가설을 기각할지를 결정
- 데이터를 분석할 때에,
- 확증적 자료 분석 : 가설을 미리 설정하고서 가설을 검증해나감
- 탐색적 자료 분석 : 가설을 설정하지 않은 상태에서 데이터를 탐색하면서 가설 후보를 찾아냄
- 가설 검정의 절차
- 귀무가설과 대립가설을 설정하기
- 유의수준을 결정하기 일반적으로 사용하는 유의 수준: p-value 0.05 미만
- 검정통계량 계산하기 p-value: 귀무가설이 참일 경우 관찰된 통계치가 나올 확률
- p-value와 유의수준을 비교하기
- 결론 도출하기 귀무가설을 기각할지 말지
# 기존 약물(A)와 새로운 약물(B) 효과 데이터 생성
A = np.random.normal(50, 10, 100)
B = np.random.normal(55, 10, 100)
# 평균 효과 계산
mean_A = np.mean(A)
mean_B = np.mean(B)
# t-검정 수행
t_stat, p_value = stats.ttest_ind(A, B)
print(f"A 평균 효과: {mean_A}")
print(f"B 평균 효과: {mean_B}")
print(f"t-검정 통계량: {t_stat}")
print(f"p-값: {p_value}")
# t-검정의 p-값 확인 (위 예시에서 계산된 p-값 사용)
print(f"p-값: {p_value}")
if p_value < 0.05:
print("귀무가설을 기각합니다. 통계적으로 유의미한 차이가 있습니다.")
else:
print("귀무가설을 기각하지 않습니다. 통계적으로 유의미한 차이가 없습니다.")
t검정
- 두 집단 간의 평균 차이가 통계적으로 유의미한지 확인
- t검정의 2가지
- 독립 표본 t검정 : 두 독립된 그룹의 평균을 비교 (ex. 두 반의 시험 성적 비교하기)
- 대응 표본 t검정 : 동일한 그룹의 사전/사후 평균을 비교 (ex. 다이어트 전후 체중 비교하기)
# 학생 점수 데이터
scores_method1 = np.random.normal(70, 10, 30)
scores_method2 = np.random.normal(75, 10, 30)
# 독립표본 t검정
t_stat, p_val = stats.ttest_ind(scores_method1, scores_method2)
print(f"T-Statistic: {t_stat}, P-value: {p_val}")
다중 검정
- 여러 가설을 동시에 검정 (ex. 여러 약물의 효과를 동시에 검정)
- 주의할 점은 각 검정마다 유의수준을 조정하지 않으면 1종 오류가 발생할 확률이 증가함
- 보정법을 사용해 문제 상황이 일어나지 않도록 해야 함 유의수준을 더 엄격하게 적용하는 방식으로 보정함
- 보정 방법: 본페로니 보정, 튜키 보정, 던넷 보정, 윌리엄스 보정 등
- 가장 대표적인 것이 본페로니 보정
import numpy as np
import scipy.stats as stats
# 세 그룹의 데이터 생성
np.random.seed(42)
group_A = np.random.normal(10, 2, 30)
group_B = np.random.normal(12, 2, 30)
group_C = np.random.normal(11, 2, 30)
# 세 그룹 간 평균 차이에 대한 t검정 수행
p_values = []
p_values.append(stats.ttest_ind(group_A, group_B).pvalue)
p_values.append(stats.ttest_ind(group_A, group_C).pvalue)
p_values.append(stats.ttest_ind(group_B, group_C).pvalue)
# 본페로니 보정 적용
alpha = 0.05
adjusted_alpha = alpha / len(p_values)
# 결과 출력
print(f"본페로니 보정된 유의 수준: {adjusted_alpha:.4f}")
for i, p in enumerate(p_values):
if p < adjusted_alpha:
print(f"검정 {i+1}: 유의미한 차이 발견 (p = {p:.4f})")
else:
print(f"검정 {i+1}: 유의미한 차이 없음 (p = {p:.4f})")
카이제곱 검정
- 범주형 데이터를 분석할 때 사용하는 방식
- 범주형 데이터의 표본 분포가 모집단 분포와 일치하는지를 검정 = 적합도 검정
- 관찰된 분포와 기대된 분포가 일치하는가 (ex. 주사위의 각 면이 동일한 확률로 나오는가)
- p-value가 높음 → 데이터가 귀무가설에 잘 맞음 (귀무가설 채택)
- p-value가 낮음 → 데이터가 귀무가설에 맞지 않음 (귀무가설 기각)
- 두 범주형 변수 간의 독립성을 검정 = 독립성 검정
- 두 범주형 변수가 독립적으로 분포하는가 (ex. 성별과 직업 만족도 간의 독립성 검정)
- p-value가 높음 → 독립성이 있음 (두 변수는 서로 관련이 없음)
- p-value가 낮음 → 독립성이 없음 (두 변수는 서로 관련이 있음)
- 범주형 데이터의 표본 분포가 모집단 분포와 일치하는지를 검정 = 적합도 검정
# 적합도 검정
observed = [20, 30, 25, 25]
expected = [25, 25, 25, 25]
chi2_stat, p_value = stats.chisquare(observed, f_exp=expected)
print(f"적합도 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")
# 독립성 검정1
observed = np.array([[10, 10, 20], [20, 20, 40]])
chi2_stat, p_value, dof, expected = stats.chi2_contingency(observed)
print(f"독립성 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")
# 독립성 검정2 (성별과 흡연 여부)
observed = np.array([[30, 10], [20, 40]])
chi2_stat, p_value, dof, expected = stats.chi2_contingency(observed)
print(f"독립성 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")- .chisquare() : 관찰된 빈도 분포가 기대된 빈도 분포와 일치하는지를 평가 적합도 검정
- chi2 : 카이제곱의 통계량
- p-value : 관찰된 데이터가 귀무가설 하에서 발생할 확률
- .chi2_contingency() : 두 개 이상의 범주형 변수 간 독립성을 검정 독립성 검정
- chi2 : 카이제곱 통계량
- p-value : 관찰된 데이터가 귀무가설 하에서 발생할 확률
- dof : 자유도 (행의 수 - 1) × (열의 수 - 1)
- expected : 기대 빈도
제1종 오류와 제2종 오류

제1종 오류
- 귀무가설이 참인데 기각하는 오류 (ex. 신약이 효과가 없는데도 효과가 있다고 결론 지음)
- 위양성(僞陽性, false positive)이라고도 함
- ɑ : 제1종 오류가 일어날 수 있는 확률 (=유의수준만큼)
- 유의수준을 조정하는 만큼 제1종 오류 발생을 제어할 수 있음
제2종 오류
- 귀무가설이 거짓인데 기각하지 않는 오류 (ex. 신약이 효과가 있는데 효과가 없다고 결론 지음)
- 위음성(僞陰性, false negative)이라고도 함
- β : 제2종 오류가 일어날 수 있는 확률
- ɑ와 달리, β는 직접 통제할 수 없음
- 시도할 만한 방법은,
- 표본 크기가 커질수록 β가 작아짐
- ɑ와 β는 상충관계에 있으므로 ɑ를 너무 낮게 설정하지 않도록 함
파이썬 공부: [코드카타] 알고리즘 문제 풀기 (67번)
67. 둘만의 암호
두 문자열 s와 skip, 그리고 자연수 index가 주어질 때, 다음 규칙에 따라 문자열을 만들려 합니다. 암호의 규칙은 다음과 같습니다
- 문자열s의 각 알파벳을index만큼 뒤의 알파벳으로 바꿔줍니다
- index만큼의 뒤의 알파벳이z를 넘어갈 경우 다시a로 돌아갑니다
- skip에 있는 알파벳은 제외하고 건너뜁니다
예를 들어s= "aukks",skip= "wbqd",index= 5일 때, a에서 5만큼 뒤에 있는 알파벳은 f지만 [b, c, d, e, f]에서 'b'와 'd'는skip에 포함되므로 세지 않습니다. 따라서 'b', 'd'를 제외하고 'a'에서 5만큼 뒤에 있는 알파벳은 [c, e, f, g, h] 순서에 의해 'h'가 됩니다. 나머지 "ukks" 또한 위 규칙대로 바꾸면 "appy"가 되며 결과는 "happy"가 됩니다
두 문자열s와skip, 그리고 자연수index가 매개변수로 주어질 때 위 규칙대로s를 변환한 결과를 return하도록 solution 함수를 완성해주세요
# 첫 번째 시도 (오답 처리)
def solution(s, skip, index):
answer = ''
for i in s:
n = ord(i)+index
if chr(n) in skip:
n = n+1
answer += chr(n)
return answer
사실 문제 보고 정신이 아득해져서 우선 생각나는 대로 작성한 코드다.
s의 첫 글자 'a'의 경우 index로 입력한 5만큼 뒤로 밀린 'f'가 그대로 출력됐다. 우선 skip의 문자열에 들어있는 알파벳을 제거하고서 index만큼 미루는 것이 작성하기 쉬운 방식일 듯했다.
# 두 번째 시도 (정답 처리)
def solution(s, skip, index):
answer = ''
letters = [chr(i) for i in range(ord('a'), ord('a')+26)] # 소문자 알파벳만 모은 리스트
for i in list(skip): #skip의 문자들을 letters에서 제거
letters.remove(i)
for j in s: # 위에서 처리한 letters 리스트로 s의 문자 하나하나 index만큼 미루기
answer += letters[(letters.index(j)+index) % (len(letters))]
return answer
아티클 스터디 ①: 거래 후기 실험을 통해 따뜻한 거래 경험 만들기
오늘 읽은 아티클:
거래 후기 실험을 통해 따뜻한 거래 경험 만들기
거래 후기 실험을 통해 당근마켓이 어떻게 따뜻한 서비스를 만들고 성장시켜 나가는지 소개해 드릴게요!
medium.com

오늘 읽은 아티클은 당근마켓이 자사의 중고거래 서비스에서 사용자들에게 더 나은 경험을 설계하기 위해 어떻게 실험을 설계하고 진행해 적용하게 되는지 그 과정을 알 수 있는 글이었다.
읽고서 뛰어난 아이디어가 단순히 번뜩 떠오르는 것만은 아니라 자사의 제품/서비스의 데이터 분석을 통한 충분한 이해를 기반으로 할 때 파생되는 일이라는 걸 느꼈다. 사실 아이디어라 함은 직관의 영역에서 도출되는 시도인데, 이를 데이터를 통해 실험하여 적절하게 맞춰나가는 당근마켓 중고거래팀의 과정이 인상적이었다. 프로젝트를 진행함에 있어서 마감 기한은 언제나 촉박하다. 촉박한 시간에 쫓겨 급하게 결정을 해치우기보다 그 과정 속에서 실험이나 분석의 과정을 충분히 갖고서 우리가 취할 액션을 도출해야 함을 느끼며 직관과 논리의 균형에 대해 생각해보게 됐다.
그리고 같은 팀원분이 공유해주신 인사이트 중에 '사실 당근마켓에서 실험에서 확인하고자 한 핵심 지표(구매자 중 거래 완료 게시글에 후기를 작성한 비율)은 자신이어도 쉽게 구해볼 수 있는 지표인데, 이런 수치를 단순히 보는 데서 그치는 것이 아니라 사용자의 서비스 이용 경험을 이해하고 그 속에서 사용자의 행동을 이끌어내기 위한 아이디어까지 있어야 함을 느꼈다'는 데서 공감했다. 사실 내 입장에서도 해당 지표를 계산하기는 그렇게 어려울 것 같진 않다. 중요한 것은 그것을 핵심 지표로 선정한 이유다. 우리가 해결하고자 하는 문제나 목표가 무엇인지를 정확히 정의하는 것이 선행되어야 하고, 그 정의에 선행되어야 하는 것은 자사 제품/서비스에 대한 충분한 이해다. 이러한 고민들이 결국 문제 설정이나 결과적으로 우리가 취하기로 한 액션에서 자사의 제품/서비스가 지향하는 가치가 자연스레 묻어나게 되는 것 같다. 역시 도메인 지식의 중요성을 이러나 저러나 피할 수가 없다.
'[내배캠] 데이터분석 6기 > 본캠프 기록' 카테고리의 다른 글
| [본캠프 34일차] 통계학 공부, QCC ③, 파이썬 공부 (0) | 2025.04.04 |
|---|---|
| [본캠프 33일차] SQL 공부, 파이썬 공부, 통계학 공부, 아티클 스터디② (0) | 2025.04.03 |
| [본캠프 31일차] SQL 공부, 파이썬 공부, 통계학 공부 (0) | 2025.04.01 |
| [본캠프 30일차] chap 3의 시작, SQL 공부, 파이썬 공부 (0) | 2025.03.31 |
| [본캠프 29일차] 기초 프로젝트 발표 (0) | 2025.03.28 |