
오늘 한 일은,
- SQL 공부
- QCC 3회차 응시하기
- QCC 3회차 제출한 쿼리 회고하기
- 통계학 공부
- [기초 통계학] 5~6주차 수강하기
- 파이썬 공부
- 수준별 학습반: [python standard] 3회차(이론), 4회차(실습) 수강하기
통계학 공부: [기초 통계학] 5~6주차 수강하기
상관관계
상관관계란?
[참고] 상관관계 그리고 인과관계
- 두 변수 간의 연관성을 나타냄 : 한 변수가 변화할 때 다른 변수가 어떻게 변화하는지를 보여줌
- 상관관계의 정도는 상관계수(correlation coefficient)로 표현함
- 상관계수의 범위 : -1 ~ +1
- 양의 상관관계 : 두 변수가 같은 방향으로 변할 때 나타남. 상관계수가 +1에 가까울수록 강해짐
- 음의 상관관계 : 두 변수가 반대 반향으로 변할 때 나타남. 상관계수가 -1에 가까울수록 강해짐
- 무상관관계 : 두 변수 간 아무런 연관성이 없을 때 나타남. 상관계수가 0에 가까울수록 강해짐
- 상관계수의 범위 : -1 ~ +1
상관계수①: 피어슨 상관계수 (Pearson Correlation Coefficient)
- 두 연속형 변수 간 선형 관계를 측정하는 지표
- 대표적인 모수 상관계수
- 사용 가능한 조건
- 두 변수 간 선형적인 관계가 예상될 때
- 두 변수 모두 연속형 변수일 때 하나라도 범주형 범주면 안 됨
- 데이터가 정규분포로 존재할 때

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import pearsonr
# 예시 데이터 생성
np.random.seed(0)
study_hours = np.random.rand(100) * 10
exam_scores = 3 * study_hours + np.random.randn(100) * 5
# 데이터프레임 생성
df = pd.DataFrame({'Study Hours': study_hours, 'Exam Scores': exam_scores})
# 피어슨 상관계수 계산
pearson_corr, _ = pearsonr(df['Study Hours'], df['Exam Scores'])
print(f"피어슨 상관계수: {pearson_corr}")
# 상관관계 히트맵 시각화
sns.heatmap(df.corr(), annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('pearson coefficient heatmap')
plt.show()
상관계수②, ③: 스피어만 상관계수, 켄달의 타우 상관계수
- 비모수 상관계수
- 모수 상관계수와 비모수 상관계수의 차이 :
모수적 방법 = 모수를 특정 분포로 가정하고서 접근하는 방식
비모수적 방법 = 모집단을 특정 분포로 가정하지 않고 접근하는 방식 - = 정규 분포 조건을 충족하지 못할 시에는 비모수 상관계수를 사용!
- 대표적으로 스피어만 상관계수와 켄달의 상관계수
- 스피어만 상관계수(Spearman's Rank Correlation Coefficient)
- 두 변수의 순위 간 상관관계를 측정 (두 변수의 순위간 일관성을 측정)
- 결과값의 범위 : -1 ~ +1
- 켄달의 타우 상관계수보다 데이터 내 편차와 에러에 민감함
- 켄달의 타우 상관계수 (Kendall's Tau Correlation Coefficient)
- 순위 간의 일치 쌍과 불일치 쌍의 비율을 바탕으로 상관관계를 측정
(ex. 사람의 키와 체중에 대한 상관관계를 계산:
키도 크고 체중도 무거우면 일치 쌍, 키는 큰데 체중이 가벼우면 불일치 쌍
이 개수 비율로 상관계수를 결정함)
- 순위 간의 일치 쌍과 불일치 쌍의 비율을 바탕으로 상관관계를 측정
- 스피어만 상관계수(Spearman's Rank Correlation Coefficient)
- 모수 상관계수와 비모수 상관계수의 차이 :
from scipy.stats import spearmanr, kendalltau
# 예시 데이터 생성
np.random.seed(0)
customer_satisfaction = np.random.rand(100)
repurchase_intent = 3 * customer_satisfaction + np.random.randn(100) * 0.5
# 데이터프레임 생성
df = pd.DataFrame({'Customer Satisfaction': customer_satisfaction, 'Repurchase Intent': repurchase_intent})
# 스피어만 상관계수 계산
spearman_corr, _ = spearmanr(df['Customer Satisfaction'], df['Repurchase Intent'])
print(f"스피어만 상관계수: {spearman_corr}")
# 켄달의 타우 상관계수 계산
kendall_corr, _ = kendalltau(df['Customer Satisfaction'], df['Repurchase Intent'])
print(f"켄달의 타우 상관계수: {kendall_corr}")
# 상관관계 히트맵 시각화
sns.heatmap(df.corr(method='spearman'), annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('spearman coefficient heatmap')
plt.show()
상관계수④: 상호정보 상관계수
- 두 변수 간 정보 의존성을 바탕으로 비선형 관계를 탐지
- 범주형 데이터에 대해서 적용도 가능함
- 비선형적이고 복잡한 관계를 탐지하고자 할 때 사용함
import numpy as np
from sklearn.metrics import mutual_info_score
# 범주형 예제 데이터
X = np.array(['cat', 'dog', 'cat', 'cat', 'dog', 'dog', 'cat', 'dog', 'dog', 'cat'])
Y = np.array(['high', 'low', 'high', 'high', 'low', 'low', 'high', 'low', 'low', 'high'])
# 상호 정보량 계산
mi = mutual_info_score(X, Y)
print(f"Mutual Information (categorical): {mi}")
가설 검정 시 주의할 점
재현 가능성
- 동일한 연구나 실험을 반복했을 때 일관된 결과가 나오는지 여부
- 연구의 신뢰성을 높이는 중요한 요소로, 결과가 재현되지 않는다면 해당 가설의 신뢰도가 떨어짐
- 가설검정 원리상의 문제나 가설검정의 잘못된 사용이 낮은 재현성으로 이어진다는 문제 발생
*가설검정 원리상의 문제: 가설을 너무 이상하게 설정했는데 p값이 유의수준보다 작게 나오는 경우
*가설검정의 잘못된 사용: 원하는 p값이 나올 때까지 실험을 반복하는 경우 - 관련 최근 제기되는 문제
- p값에 대한 논쟁
- 의견1 : “p값을 사용하지 않는 것이 좋다”
- 의견2 : “유의수준을 0.05에서 변경하는 것이 좋다”
- 재현성 위기의 문제
- 최근 논문을 다시 재현해서 실험을 해보는데 똑같은 결과가 나오지 않는 사례가 많이 나옴
[참고] [김우재의 보통과학자] 과학의 재현성 위기와 보통과학자의 송곳 - 원인
- 완전 동일하게 똑같이 실험을 수행하기 쉽지 않기 때문에
- 가설 검정도 100%의 검정력을 가진 것이 아니기 때문에
- 가설 검정을 할 때 잘못된 방법으로 수행했기 때문에
- p값이 0.05가 되도록 조작함 =p해킹
통계적으로 아무 의미가 없음에도 의미가 있다고 해버리는 1종 오류를 저지를 수 있음 - 20번 중에 1번은 귀무가설이 옳음에도 불구하고 기각될 수 있음
이는 확률적으로 어쩔 수 없이 발생하는 오류이기도 함- 유의수준을 낮춰보는 등 유의수준을 통제해볼 수 있음
- 그러나 유의수준을 낮춤에 따라 베타값이 커지기에 유의수준을 낮춘다고 능사는 아님
- 일각에선 '유의수준을 0.005로 설정하면서 데이터 수를 70% 더 늘려서 베타 값도 통제하는 방향'을 제안
즉 이는 유의수준도 낮추고, 데이터 수를 늘려 베타값 역시 낮추는 방향으로 가자는 것임
(가장 좋은 것은 데이터 수를 최대한 많이 확보하는 것. 그렇게 하면 애초에 20번 중에 1번 나타나는오류를 마주칠 확률 자체가 줄기 때문에) - 잘못된 가설을 세우더라도 우연히 0.05보다 낮아서 가설이 맞는것처럼 보일 수도 있기에 가능한 한 애초에 좋은 가설을 설정하는 것도 중요함
- p값이 0.05가 되도록 조작함 =p해킹
- 최근 논문을 다시 재현해서 실험을 해보는데 똑같은 결과가 나오지 않는 사례가 많이 나옴
- p값에 대한 논쟁
p-해킹
- 데이터 분석을 반복하여 p-값을 인위적으로 낮추는 행위
- 원인
- 유의미한 p-값을 얻을 때까지 반복 분석하는 것을 조심
- 다양한 상황 중에서 p값이 유리하게 나오는 상황만 선별적으로 보고하는 것을 조심 차라리 시도한 다양한 상황을 모두 보고하든가
- 모든 결과를 다 보고하거나 그를 바탕으로 더 엄격한 실험을 설계하여 추가적으로 수행함
- 가능한 가설을 미리 세우고 검증하는 가설검증형 방식으로 분석을 해야 함
- 만약 탐색적으로 분석한 경우 가능한 모든 변수를 보고하고 본페로니 보정과 같은 방법을 사용해야 함
선택적 보고
- 유의미한 결과만을 보고하고, 유의미하지 않은 결과는 보고하지 않는 행위
- 결과를 보면서 가설을 다시 새로 설정했는데 마치 처음부터 설정한 가설이라고 얘기할 때에도 해당함
자료 수집의 중단 시점을 결정할 때
- 데이터 수집을 시작하기 전에 언제 수집을 중단할지 명확하게 결정하지 않으면, 원하는 결과가 나올 때까지 데이터를 계속 수집할 수 있음
원하는 결과가 나올 때까지 자료 수집을 하지 않도록 주의하기!- 이상적으로는 사전에 정해진 계획에 따라야 함
- 결과를 이미 정해놓고 그에 맞추기 위해 자료수집을 하고자 할 때
(ex. 50명의 데이터를 수집하기로 했으나, 원하는 결과가 나오지 않자 100명까지 추가로 수집)
탐색용 데이터와 검증용 데이터의 분리
- 데이터 탐색을 통해 가설을 설정하고, 이를 검증하기 위해 별도의 독립된 데이터셋을 사용하는 것
- 데이터 과적합을 방지하고 결과의 신뢰성을 높임
SQL 공부: 3회차 QCC 회고

오늘은 다소 처참한 결과.. 3번 빼고 다 제출했는데 음 하나만 맞췄다. 일단 한 문제씩 봐야 알 것 같다. 뭘 맞췄지도 감이 안 온다.
(3번 문제는 쿼리 돌리는 데 계속 시간이 오래 걸리거나 아니면 오류 메시지가 뜨길래 풀기를 포기했다고 한다...)
1. 임직원 로그인 빈도 분석
2023년 3분기(7~9월) 동안 임직원들이 사내 시스템에 얼마나 자주 로그인했는지 분석하기
- 2023년 7월 1일부터 9월 30일까지 성공한 로그인 기준으로 직원별 로그인 횟수 집계
- 성공한 로그인이 없을 시 제외
- 로그인 횟수별로 직원 수를 집계해 조회하기
- unique_logins 컬럼 기준 오름차순으로 정렬시키기
-- 제출한 쿼리 (오답 처리됨)
SELECT s.login_cnt unique_logins,
COUNT(employee_id) employee_count
FROM (
SELECT employee_id,
COUNT(employee_id) login_cnt
FROM logins
WHERE (login_time BETWEEN '2023-07-01' AND '2023-09-30') AND
(login_result = 'SUCCESS')
GROUP BY employee_id
) s
GROUP BY s.login_cnt
ORDER BY s.login_cnt
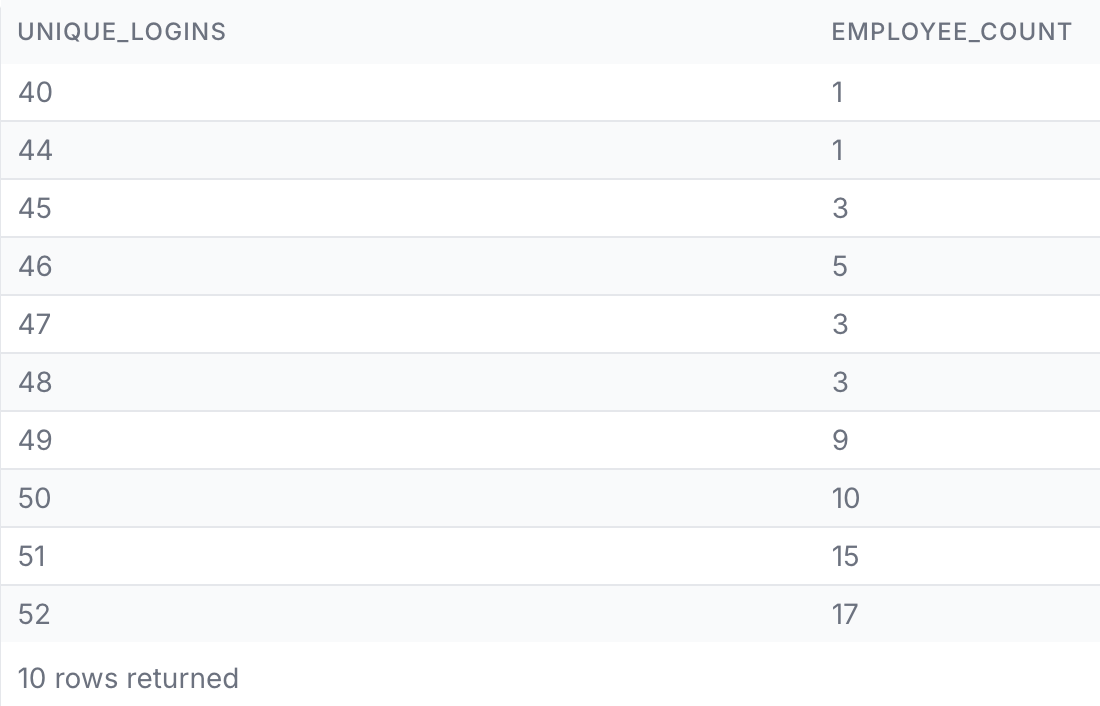
정답 쿼리의 결과 테이블과 비교해보니 행수를 제외하고는 unique_logins 컬럼에 집계된 로그인 횟수도, 그리고 해당 횟수에 집계된 직원 수도 군데군데 다르다.


우선 결과 테이블에 조회된 총 직원 수를 각각 구해봤을 때 둘의 차이가 없는 것을 보면 기간 조건(2023년 3분기)과 로그인 결과 조건(성공일 경우만)은 문제가 없는 듯하다.
그런데 정답쿼리는 직원별 로그인 횟수를 집계했을 때 가장 적게 로그인한 횟수가 40회로 잡혀 있는데 내 경우에는 38회로 잡혀있다.

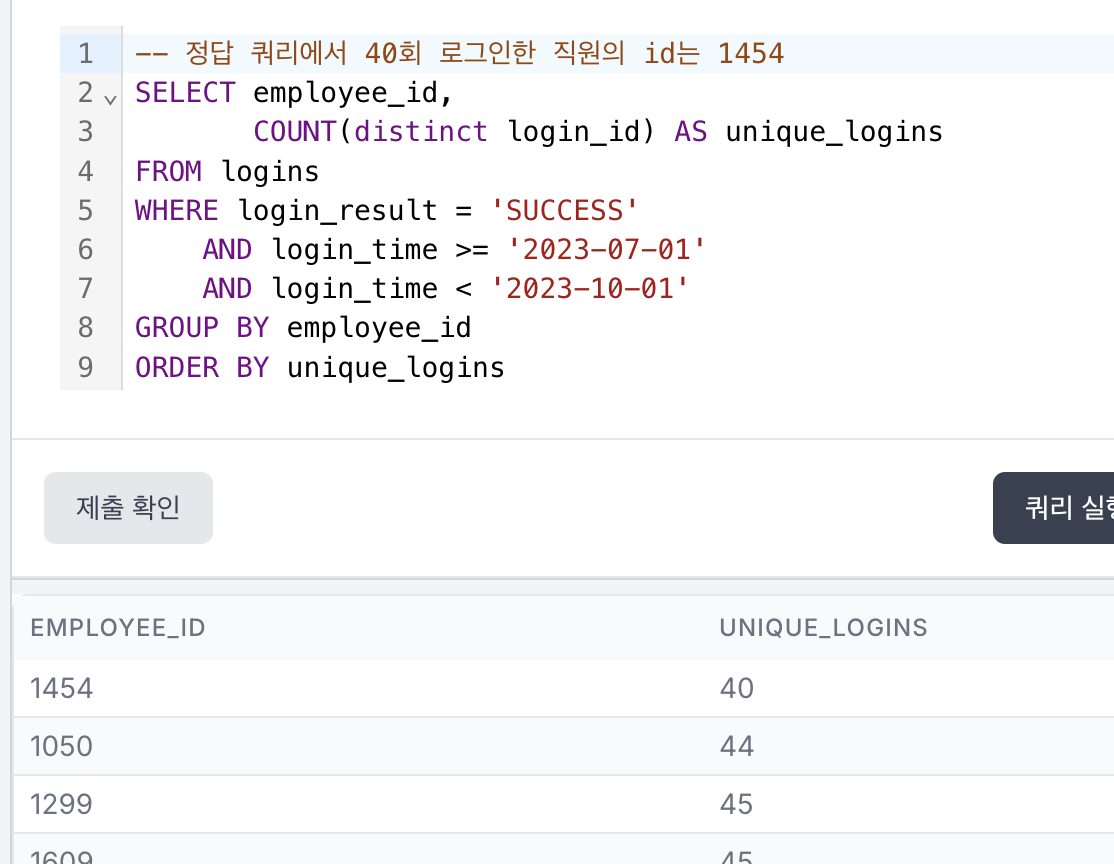
두 쿼리 모두 가장 적게 로그인한 직원의 id는 1454로 동일했다. 그래서 employee_id가 1454인 로그인 데이터만 확인할 수 있게,
- 기존의 WHERE절에다 'employee_id = 1454'라는 조건을 추가하고
- SELECT절에서 COUNT(*)를 하면
뭐가 맞는지 알 수 있지 않을까 싶었다.

...?

당연히 정답 쿼리의 결과가 나올 줄 알았는데 이게 뭐지? 왜 38건으로 집계된 거지??
내가 맞았다고? 그치만 아니잖아, 저게 정답 쿼리잖아. 뭐지?? 내가 뭘 잘못했나? 그치만 저게 2023년 3분기 동안 id 1454가 로그인에 성공한 데이터를 조회한 게 맞지 않아...? 뭐지. 아 데이터도 10행밖에 조회가 안 돼서 일일이 다 볼 수도 없고 답답하구만.
이율 몰라 찜찜하지만, 그러면 이번엔 10행 이내로 조회해 볼 수 있을 것으로 한번 보기로 했다.
내가 제출한 쿼리와 정답 쿼리의 결과 테이블을 비교해보면, 정답 쿼리에선 45회 로그인한 직원이 3명으로 집계됐고, 내가 제출한 쿼리에선 6명으로 집계됐다. 그래서 이 횟수에 해당하는 직원 id를 조회해보기로 했다.


...???
뭘까. 이번에도 정답 쿼리에서처럼 45회 로그인한 사람들이 3명이 아니라, 내가 작성한 쿼리대로 6명이 뜨..네? 뭐지? 내가 풀어서 계속 내 방식대로 돌아가는 건가??
그래서 저기 조회된 직원 id를 정답 쿼리에서 WITH 구문으로 만들어 놓은 success_logins 테이블에서 조회해봤다.
-- 쿼리가 너무 길어져서 캡쳐 이미지에 다 안 들어와서 가져왔다
-- 정답 쿼리 속 success_logins 테이블
WITH success_logins AS (
SELECT employee_id,
COUNT(distinct login_id) AS unique_logins
FROM logins
WHERE login_result = 'SUCCESS'
AND login_time >= '2023-07-01'
AND login_time < '2023-10-01'
GROUP BY employee_id
)
SELECT *
FROM success_logins
WHERE employee_id IN ( -- 아까 로그인 횟수가 45회인 직원 id를 그대로 가져와서 그 id와 일치하는 데이터들을 success_logins 테이블에서 조회함
SELECT s.employee_id
FROM (
SELECT DISTINCT employee_id,
COUNT(login_id) OVER (PARTITION BY employee_id) login_cnt
FROM logins
WHERE (login_time BETWEEN '2023-07-01' AND '2023-09-30') AND
(login_result = 'SUCCESS')
) s
WHERE s.login_cnt = 45)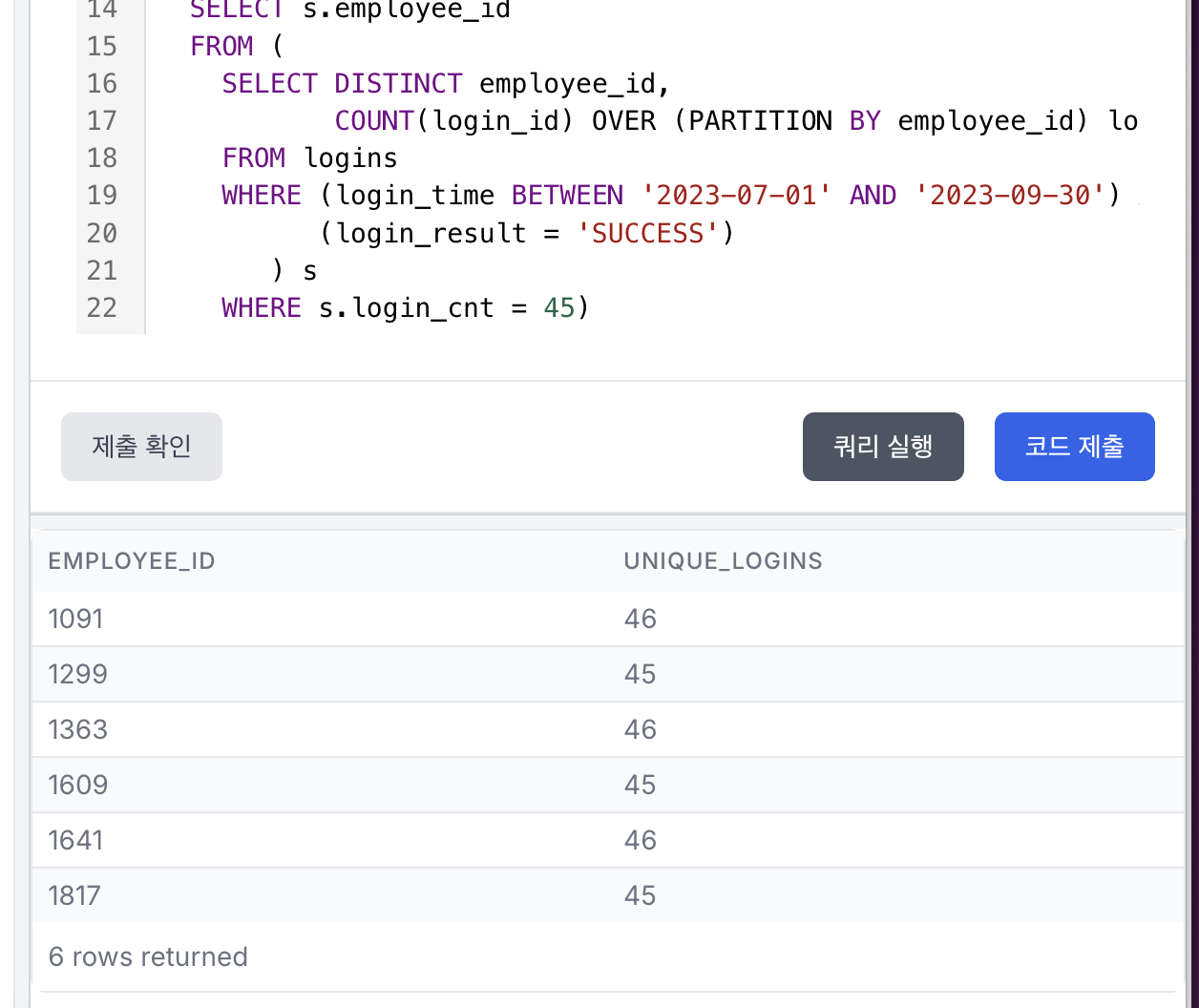
암튼 저렇게 코드블럭 속에 적어놓은 것처럼 쿼리를 돌리면 success_logins에서,
- 로그인 횟수가 45회 : 1299, 1609, 1817
- 로그인 횟수가 46회 : 1091, 1363, 1641
아, 그런데 여기까진 구했는데 결과 테이블을 전체를 조회할 수 없으니까 뭘 더 해서 뭐가 문제인지 어떻게 찾아내야 하는지 모르겠다. 으으.
내 쿼리에선 뭐가 잘못된 걸까... 괴롭다.

2. 세 번째로 높은 급여를 받는 직원
세 번째로 높은 급여를 받는 직원을 파악하여 고연봉자에 대한 인사 정책을 수립하는 데 사용하고자 합니다.
- 전체 직원 중 세 번째로 높은 급여 금액을 찾기
- 해당 금액을 받는 모든 직원을 조회
- 결과는 employee_id 기준으로 오름차순 정렬시키기
-- 제출한 쿼리 (정답 처리됨)
SELECT employee_id,
name,
salary
FROM employee_salary
WHERE salary = (
SELECT MIN(s.salary)
FROM (
SELECT DISTINCT salary
FROM employee_salary
ORDER BY salary DESC LIMIT 3
) s
)
ORDER BY employee_id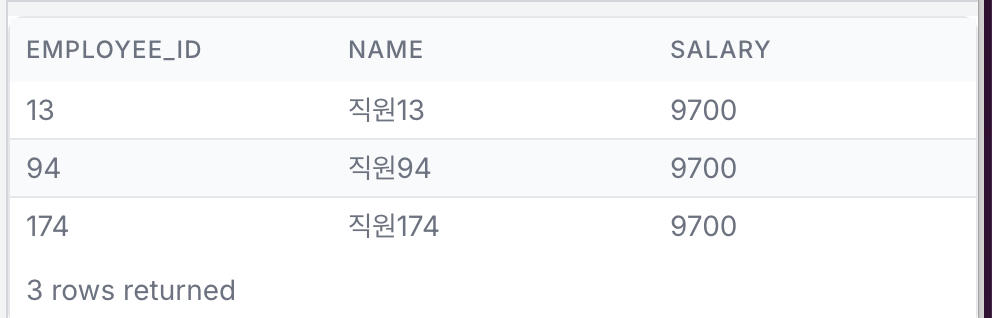
정답은 맞혔지만 좀 업그레이드 시켜야 할 쿼리다.
애초에 문제를 읽으면서 알았다. '이건 윈도우 함수를 써야 하는 구나.' 그래서 가장 먼저 생각난 RANK() OVER로 돌리는데, 아, 이게 내가 안 되는 문법으로 입력해선지 그냥 시스템상의 문제였는지 분간이 안 되면서 순간적으로 '윈도우 함수를 내가 모르나? RANK() OVER는 헷갈리는 것 같기도..' 하면서 최근에 풀었던 문제에서 사용했던 LAG() OVER를 사용해 보기로 했다.
LAG() OVER 함수로 컬럼을 하나 만들어서 salary 컬럼 기준으로 내림차순 정렬을 하고서 2행 전의 salary 값을 가져오는 컬럼을 만들어 보려고 하는데, 일단 우선적으로 원하는 대로 컬럼이 안 만들어졌고 안 되는 와중에 '이걸 왜 만들고 있지?' 생각이 들면서 그냥 윈도우 함수를 쓰지 않고서 쿼리를 작성하기로 했다. (지금 생각해보면 윈도우 함수를 내가 쓸 줄 아는지, 아닌지를 판단하고 싶었던 것 같아서 최근 써본 것을 기준으로 원하는 대로 결과 테이블을 조회할 수 있는지 보고 싶었던 것 같다...)
그래서 선택한 것이 나름 머리를 짧은 시간 동안 굴려본 결과 저렇게 WHERE절을 작성하게 된 것이다.
- ① salary 컬럼을 중복 없이 조회하는 데 이때 salary 기준으로 내림차순 정렬해서 3개까지만 조회하고
- ② ①에서 이제 salary의 최솟값을 조회해서
- ③ ②의 salary와 일치하는 salary를 가진 데이터들을 결과 테이블에서 조회하게끔
하는 방식으로 작성하게 됐다.
-- 튜터님의 정답 쿼리(내가 제출한 것과 같은 결과가 조회됨. 근데 윈도우 함수를 사용해 작성한 쿼리)
WITH salary_ranked AS (
SELECT employee_id, name, salary,
DENSE_RANK() OVER (ORDER BY salary DESC) AS rnk
FROM qcc.employee_salary
)
SELECT employee_id, name, salary
FROM salary_ranked
WHERE rnk = 3
ORDER BY employee_id(그런데 정답 쿼리를 보다 보니까 인라인 뷰보다 WITH 구문으로 테이블을 만들어서 사용하시는데 그냥 개인 취향인 것인지 아니면 특별히 WITH 구문을 사용하는 것이 인라인 뷰보다 더 나은 점(성능? 가독성?)이 있기 때문에 이 방식을 고수하시는지가 궁금해지는)
3. 부서 간 메시지 비율 계산
ㅇ
ㅇ일단 풀다가 답답해서 4번으로 먼저 넘어가서 풀었고(근데 그 4번 틀림ㅋㅋㅋㅋ) 풀고서 다시 3번으로 돌아와서 풀려고 했는데 시간이 60초인가? 넘어갔다는 둥, 이젠 좀 익숙한 불러오는 데 실패했다는 둥 메시지를 여럿 겪고선 '오늘은 날이 아닌가보다' 하고 나중에 끝나고 다시 풀어보자고 하고 그냥 나왔다.
4. [도전] 광고 성과 Attribution 분석
전환된 사용자 중 최초 방문했을 때 어떤 광고 채널로 유입되었는지 분석하고자 함 (*First-Touch Attribution)
- converted 컬럼이 True인 사용자들만 분석의 대상
- 한 사용자가 여러 세션을 가질 수 있는데, 그 중에서 첫 번째(created_at 기준) 세션 유입 채널을 추출하기
- 결과를 user_id 컬럼 기준 오름차순으로 정렬시키기
-- 제출한 쿼리 (오답 처리됨)
SELECT s.user_id,
a.channel
FROM (
SELECT *
FROM user_sessions
WHERE (user_id, created_at) IN (
SELECT user_id,
MIN(created_at)
FROM user_sessions
GROUP BY user_id)
) s
LEFT JOIN ad_attribution a ON s.session_id = a.session_id
WHERE a.converted = 1
ORDER BY s.user_id

음 결과 테이블의 첫 10행끼리만 비교했을 때는 내 쿼리와 정답 쿼리의 다른 점이 없다. 대체 어디서 문제가 있는 걸까...


이번엔 user_id 개수를 집계해봤을 때 정답 쿼리보다 내가 제출한 쿼리에서 12명을 덜 집계했다고 한다.
'[내배캠] 데이터분석 6기 > 본캠프 기록' 카테고리의 다른 글
| [본캠프 36일차] SQL 공부, 머신러닝 공부, 파이썬 공부 (0) | 2025.04.08 |
|---|---|
| [본캠프 35일차] SQL 공부, 머신러닝 공부 (2) | 2025.04.07 |
| [본캠프 33일차] SQL 공부, 파이썬 공부, 통계학 공부, 아티클 스터디② (0) | 2025.04.03 |
| [본캠프 32일차] SQL 공부, 통계학 공부, 알고리즘 공부, 아티클 스터디① (0) | 2025.04.02 |
| [본캠프 31일차] SQL 공부, 파이썬 공부, 통계학 공부 (0) | 2025.04.01 |