
월요일..이네....
오늘 한 일은,
- SQL 공부
- [코드카타] SQL 3문제 풀기 (116~118번)
- 통계학 공부
- [통계 라이브 세션] 3회차 수강하기
- 머신러닝 공부
- [실무에 쓰는 머신러닝 기초] 1-1 ~ 1-2 수강하기
SQL 공부: [코드카타] SQL 문제 풀기 (116~118번)
116. (1321) Restaurant Growth
You are the restaurant owner and you want to analyze a possible expansion (there will be at least one customer every day).
Compute the moving average of how much the customer paid in a seven days window (i.e., current day + 6 days before). average_amount should be rounded to two decimal places.
Return the result table ordered by visited_on in ascending order.
우선 윈도우 함수로 계산할 행의 범위를 지정해줘야 한다는 것은 알겠는데, 정확한 문법을 모르겠어서 이와 관련해서 먼저 찾아봤다.
[참고1] [SQL] WINDOW 함수 ROWS BETWEEN
[참고2] [MYSQL] 윈도우 함수 총정리 2 (범위지정 ROWS/RANGE)
- ROWS BETWEEN / RANGE BETWEEN
- ROWS BETWEEN : 실제 행의 물리적 위치에 따라 범위를 지정함
- RANGE BETWEEN : 데이터 값의 범위 기준으로 범위를 지정함. 동일한 값이 있을 경우 값이 포함되는 모든 행이 포함됨
- n PRECEDING : 현재 행 기준으로 n행 선행하는 행
- UNBOUNDED PRECEDING : 첫 행을 시작으로 모든 선행하는 행
- n FOLLOWING : 현재 행 기준으로 n행 후행하는 행
- CURRENT ROW : 현재 행
- n FOLLOWING : 현재 행 기준으로 n행 후행하는 행
- UNBOUNDED FOLLLOWING : 현재 행 기준으로 마지막 행까지 모든 후행하는 행
-- 첫 번째 작성한 쿼리 (오답 처리됨)
SELECT *
FROM (
SELECT DISTINCT visited_on,
SUM(amount) OVER (ORDER BY visited_on RANGE BETWEEN INTERVAL '6' DAY PRECEDING AND CURRENT ROW) amount,
ROUND(AVG(amount) OVER (ORDER BY visited_on RANGE BETWEEN INTERVAL '6' DAY PRECEDING AND CURRENT ROW), 2) average_amount
FROM Customer
) s
WHERE visited_on >= (
SELECT ADDDATE(MIN(visited_on), INTERVAL 6 DAY)
FROM Customer)
윈도우 함수에서 범위 지정하는 문법에 대해 찾아보고서 해당 내용을 참고해 첫 번째 쿼리를 작성했는데 왜인지 amount 컬럼은 7일치 계산이 잘 됐는데, average_amount 컬럼은 계산이 요구한 대로 되지 않았다.

애초에 쿼리를 작성할 때 ROWS가 아니라 RANGE BETWEEN으로 준 것도 같은 날짜가 여러 행인 것도 있어서 RANGE를 사용했는데, 평균을 보니 일자 기준(7일)으로 나눈 것이 아니라 행 기준(8행)으로 평균을 구한 것이다.
-- 두 번째 작성한 쿼리 (정답 처리됨)
SELECT *
FROM (
SELECT DISTINCT visited_on,
SUM(amount) OVER (ORDER BY visited_on RANGE BETWEEN INTERVAL '6' DAY PRECEDING AND CURRENT ROW) amount,
ROUND((SUM(amount) OVER (ORDER BY visited_on RANGE BETWEEN INTERVAL '6' DAY PRECEDING AND CURRENT ROW)/7), 2) average_amount
FROM Customer
) s
WHERE visited_on >= (
SELECT ADDDATE(MIN(visited_on), INTERVAL 6 DAY)
FROM Customer)그래서 average_amount를 계산할 때에 amount를 분자로, 분모를 7로 두어 구하는 방식으로 수정했다.
117. (602) Friend Requests 2: Who Has the Most Friends
Write a solution to find the people who have the most friends and the most friends number.
The test cases are generated so that only one person has the most friends.
-- 첫 번째 작성한 쿼리 (오답 처리됨, testcase11에서)
SELECT DISTINCT s.id,
SUM(s.cnt) OVER (PARTITION BY s.id) num
FROM (
SELECT requester_id id,
COUNT(requester_id) OVER(PARTITION BY requester_id) cnt
FROM RequestAccepted r
UNION
SELECT accepter_id id,
COUNT(accepter_id) OVER(PARTITION BY accepter_id) cnt
FROM RequestAccepted a
) s
ORDER BY num DESC LIMIT 1
사실 이 쿼리는 친구가 가장 많은 id만 조회하는 조건 생각해내기 귀찮아서(..) '혹시 ORDER BY로 내림차순 정렬해서 1행만 조회해서도 통과하려나..?'를 보려고 제출해봤던 것이지만 예상치도 못하게 예상한 결과 테이블과 완전 다른 결과 테이블이 출력되면서 어안이 벙벙해진 상태가 되고 말았다.
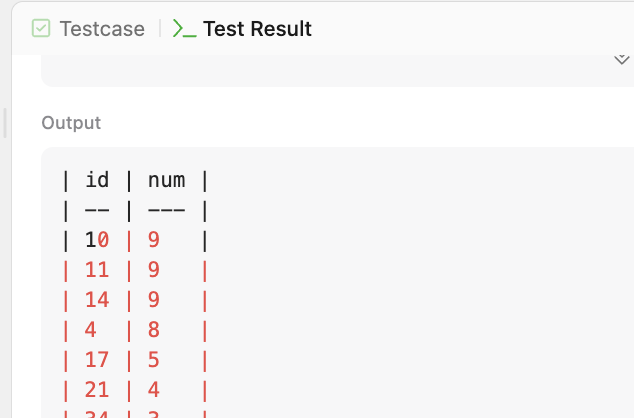
대체 왜 id 17은 5번밖에 집계되지 않은 것일까.

첫 번째 작성한 쿼리에서 id에서 중복 허용해서 출력하고, num 컬럼을 계산하는 부분을 삭제하고 WHERE절에 id가 17인 것만 조회하도록 실행해보니 또 여기선 id 17이 10번 뜨는 것을 보니 뭔가 이상하다 싶어서 SELECT절을 고쳐봤다. 그런데 아무리 수정해봐도 지금 작성한 SELECT절이 맞는 것 같은 기분이 들었다. (고치면 고칠수록 이상해지는)
-- 두 번째 제출한 쿼리 (정답 처리됨)
SELECT DISTINCT s.id,
SUM(s.cnt) OVER (PARTITION BY s.id) num
FROM (
SELECT DISTINCT requester_id id,
COUNT(requester_id) OVER(PARTITION BY requester_id) cnt
FROM RequestAccepted r
UNION ALL
SELECT DISTINCT accepter_id id,
COUNT(accepter_id) OVER(PARTITION BY accepter_id) cnt
FROM RequestAccepted a
) s
ORDER BY num DESC LIMIT 1그러다가 인라인뷰에 requester의 id를 집계한 부분만 따로 조회해봤는데 id별로 중복 없이 조회하는 방법으로 수정하는 것이 좋을 것 같아서 requester와 accepter 모두 그렇게 수정하고 두 테이블을 합칠 때 중복 허용한 UNION ALL로 합쳤다.
그렇게 수정해주니 문제 없이 통과됐다...!
그리고 통과된 결과를 보니 내가 작성한 쿼리보다 더 나은 쿼리가 있는 것 같아서 다른 사람들이 제출한 쿼리도 둘러봤다.
-- 다른 사람이 제출한 쿼리 (추천 수 1위)
WITH base AS(
SELECT requester_id id FROM RequestAccepted
UNION ALL
SELECT accepter_id id FROM RequestAccepted)
)
SELECT id, COUNT(*) num
FROM base
GROUP BY id
ORDER BY num DESC LIMIT 1그냥 애초에 requester_id 컬럼과 accepter_id 컬럼을 한 컬럼으로 합치고, 그 상태에서 id별로 COUNT()를 하면 간단한 일이구나..
118. (585) Investments in 2016
Write a solution to report the sum of all total investment values in 2016 tiv_2016, for all policyholders who:
- have the same tiv_2015 value as one or more other policyholders, and
- are not located in the same city as any other policyholder (i.e., the (lat, lon) attribute pairs must be unique)
Round tiv_2016 to two decimal places.
-- 첫 번째 작성한 쿼리 (오답 처리됨)
SELECT ROUND(SUM(tiv_2016), 2) tiv_2016
FROM Insurance
WHERE tiv_2015 IN (
SELECT tiv_2015
FROM Insurance) AND
(lat, lon) NOT IN (
SELECT lat, lon
FROM Insurance)처음엔 위와 같이 적었는데 아무것도 조회가 안 됐다. 그래서 SELECT *로 수정해서 WHERE절의 조건들이 어떻게 돌아가는지 확인하는 과정에서 이렇게 작성하면 자기자신을 제외하고서 서브쿼리 안에 있는지, 없는지를 판단해야 하는데 그럴 수 없다는 것을 알아차렸다.
-- 두 번째 작성한 쿼리 (정답 처리됨)
SELECT ROUND(SUM(tiv_2016), 2) tiv_2016
FROM (
SELECT *,
COUNT(latlon) OVER (PARTITION BY latlon) latlon_num 2-2. latlon의 수를 집계
FROM (
SELECT *,
COUNT(tiv_2015) OVER (PARTITION BY tiv_2015) tiv_2015_num, --1-1. tiv_2015의 수를 집계
CONCAT(lat,lon) latlon -- 2-1. lat과 lon을 CONCAT()으로 합침
FROM Insurance) s
) s2
WHERE (s2.tiv_2015_num > 1) AND -- 1-2. tiv_2015가 2개 이상일 것
(s2.latlon_num < 2) -- 2-3. latlon이 1개일 것고민하다가 각각의 수를 집계해서 tiv_2015는 값이 2 이상일 것(=자신 말고도 같은 값이 하나 이상 있어야 함), lat과 lon 쌍은 1개일 것(=그 쌍이 오직 한 개여야 함)으로 조건을 주는 방식으로 문제를 풀었다.
그리고 이 문제도 제출하고 결과를 보니 더 나은 쿼리들이 있길래 다른 사람들의 제출 쿼리를 확인해봤다.
-- 다른 사람의 정답 쿼리 (추천 수 1위)
SELECT ROUND(SUM(tiv_2016), 2) AS tiv_2016
FROM Insurance
WHERE tiv_2015 IN (
SELECT tiv_2015
FROM Insurance
GROUP BY tiv_2015
HAVING COUNT(*) > 1)AND
(lat, lon) IN (
SELECT lat, lon
FROM Insurance
GROUP BY lat, lon
HAVING COUNT(*) = 1)WHERE절로 그냥 처리할 수 있었다니.. 나 왜 저렇게 복잡하게 풀었니.
머신러닝 공부: [실무에 쓰는 머신러닝 기초] 1-1~1-2 수강하기
머신러닝(Machine Learning)
머신러닝 (인공지능과 딥러닝의 관계 속에서 알아보기)

- 인공지능(AI, Artificial Intelligence)
- 사람의 지적 능력을 컴퓨터를 통해 구현하는 기술 머신러닝을 포함하는 가장 큰 개념
- 머신러닝(Machine Learning)
- 인공지능을 구현하기 위해 데이터로부터 특징 및 규칙을 발견하게끔 기계를 학습시키는 방법
- ex. 스팸 메일 분류 : 스팸 메일에는 특정 단어가 자주 등장하는 패턴이 있다면 이런 메일의 경우 자동으로 스팸 메일로 분류함
- 딥러닝(Deep Learning)
- 머신러닝의 하위 분야로, 사람의 뇌신경을 본 떠 만든 인공신경망을 여러 겹 쌓아 복잡한 정보를 학습시키는 방법
- 오늘날 유명한 AI 모델들이 이에 속함 (ex. ChatGPT, 알파고, 알파스타, DALL-E)
머신러닝의 3대 요소
- ① 데이터
- ② 알고리즘 ≒ 머신러닝의 모델
- 문제를 해결하기 위해 순서대로 처리하는 방법이나 규칙
- ③ 컴퓨팅 파워
- 컴퓨터가 얼마나 빠르고 많이 일(연산)을 할 수 있는지 나타내는 능력 이는 특히 딥러닝의 경우 중요한 요소
머신러닝을 현업에서 사용하는 사례
- 제조업
- 센서 데이터를 수집 → 설비의 이상 징후를 예측 / 품질 불량을 예측
- 자동화 공정을 제어 및 유지ᐧ보수 비용을 절감
- 생산 설비의 센서에서 데이터를 수집해 그를 바탕으로 장비 고장 시점을 예측하거나
- 공정 단계별 데이터를 수집해 병목 현상, 자원 활용 비율 등을 분석하여 전체 공정 효율을 최대화하도록 설계 및 제어하거나
- 과거 판매량, 계절성, 프로모션, 경제 지표 등 데이터를 종합적으로 분석해 미래 수요량을 정확히 예측하거나
- 공장에서 전기ᐧ가스 등 소비량을 실시간으로 파악해 낭비를 줄이고 필요한 곳에만 적절히 에너지를 공급하도록 조절하거나
- 금융업
- 과거의 금융 거래 데이터를 기반으로 신용카드 사기 거래를 탐지해내거나 대출 리스크를 평가
- 대출이나 신용카드 발급을 원하는 고객을 대상으로 그 사람에 대한 신용도를 평가하거나
- 대출, 주식, 채권 등에 투자할 때 발생할 수 있는 손실 위험을 계산하여 위험 관리 하거나
- 투자할 때 금융 상품을 알고리즘을 통한 자동 매매나 로보어드바이저를 통한 투자 종목 추천을 이용하거나
- 고객 응대를 챗봇으로 자동화하거나
- 과거의 금융 거래 데이터를 기반으로 신용카드 사기 거래를 탐지해내거나 대출 리스크를 평가
- 마케팅
- 거래 데이터를 바탕으로 고객 세분화, 고객의 구매 패턴 분석, 타겟 마케팅을 수립
- 고객 데이터를 기반으로 인구통계학적 정보(나이, 지역, 직업 등), 구매 이력, 선호 카테고리 등을 고려하여 유사한 행동양식을 보이는 집단을 군집화하거나 고객 세분화
- 그룹을 대표하는 가상 인물을 설정해, ‘우리 고객은 이런 특징을 가진 사람’이라고 구체적으로 이해하려 시도하거나 페르소나 마케팅
- 해당 고객의 이전 이력을 바탕으로 사용자가 좋아하거나 흥미로워할 만한 상품·콘텐츠를 자동으로 골라주거나
(ex. 유튜브의 '다음에 볼 만한 영상') - 과거 캠페인 데이터(노출 수, 클릭 수, 전환율 등)와 고객 반응 데이터를 바탕으로, 향후 캠페인의 성과(전환율, 매출 기여도)를 예측하거나
- 한 명의 고객이 우리 회사와 거래하는 동안 얼마나 많은 수익을 가져다줄지를 예상하는 고객 생애 가치(LTV)를 예측하거나
- 거래 데이터를 바탕으로 고객 세분화, 고객의 구매 패턴 분석, 타겟 마케팅을 수립
- 헬스케어(질병 진단, 환자 상태 예측), 자율주행(카메라, 라이다 등을 통해 실시간 도로 상황을 분석해 의사결정) 등
머신러닝 vs 기존의 통계 분석
- 통계 분석
- 주로 '왜?'라는 질문에 집중해 그에 영향을 미치는 요인들을 찾아내는 과정
- 데이터의 분포와 그 속에서 찾을 수 있는 관계를 이해하고 해석하는 데 중점을 둠
- 통계 분석을 하든 머신러닝을 하든 둘 다 데이터가 많을수록 좋지만, 데이터가 얼마 되지 않는 상황이라면 통계 분석을 하는 편이 나음
- 머신러닝
- 주로 '얼마나 잘?'이라는 질문에 집중해 데이터를 넣어서 도출된 결과값이 얼마나 잘 맞아떨어지는지를 따짐
- 대규모의 데이터셋에서 복잡한 패턴을 학습하고 그를 기반으로 예측하는 데 중점을 둠
- 데이터가 많으면 많을수록 좋음
(데이터가 적은 상황에서 머신러닝을 활용하고자 한다면 데이터 증강(augmentation), 전이 학습(transfer learning) 등의 방법을 시도해 볼 수도 있음)
머신러닝의 3가지 종류
- ① 지도 학습(Supervised Learning)
- 정답값(레이블)이 있는 데이터를 학습하는 방식
- 분류(classification) : 어느 그룹에 속하는지를 결정 (ex. 스팸 메일일지 아닌지, 대출 상환 가능 여부 등)
- 회귀(regression) : 숫자로 된 결과값을 예측 (ex. 주택 가격 예측, 주가 예측)
- 정답값(레이블)이 있는 데이터를 학습하는 방식
- ② 비지도 학습(Unsupervised Learning)
- 레이블이 없는 데이터에서 스스로 데이터 패턴을 찾아내는 방식
- 군집화(clustering) : 성향이 비슷한 것들끼리 자동으로 묶음(ex. 고객 군집 분석, 문서 주제 분석)
- 차원 축소(dimensionality reduction) : 데이터의 특징(변수)가 너무 많아 복잡한 데이터를 핵심 정보만 남기고 압축
전처리에서도 자주 사용하고, 혹은 복잡한 데이터를 시각화할 때도 사용함
- 레이블이 없는 데이터에서 스스로 데이터 패턴을 찾아내는 방식
- ③ 강화 학습(Reinforcement Learning)
- 에이전트가 환경과 상호작용하며 보상을 최대화하도록 학습 게임, 전략 등에서 자주 활용
- 시뮬레이션 환경에서 시도-오류를 반복하며 가장 높은 보상을 보장해주는 행동 규칙(전략)을 학습
- 에이전트 : 학습을 수행하는 주인공 (게임 → 플레이어, 로봇 → 로봇 자체)
- 환경 : 에이전트가 움직이고 상호작용하는 무대
- 보상 : 에이전트가 잘했을 때 얻는 점수(칭찬)나, 잘못했을 때 받는 벌점 같은 개념
머신러닝 모델링 프로세스
- 데이터 수집
- 웹 크롤링, 센서 측정, 설문조사, DB 추출 등 다양한 방법
- 양질의 데이터 확보가 프로젝트의 성패를 좌우
- 데이터 전처리
- 결측치 처리
- 빈 칸을 평균이나 최빈값으로 채우거나, 필요하면 빼고(삭제) 분석
무조건 제거하진 않음. 예를 들어 나이에서 결측치가 발생했는데 해당 부분을 제외하고는 데이터가 잘 채워져 있어서 아까울 수도 있음. 그런 상황에선 결측치라 바로 제거하지 않고 나이의 평균을 임으로 채워넣는다든지 다른 처리를 할 수도 있음(평균 말고도 최빈값을 넣는다든지, 중앙값을 넣는다든지도 가능)
- 빈 칸을 평균이나 최빈값으로 채우거나, 필요하면 빼고(삭제) 분석
- 이상치 처리
- 대부분의 데이터 범위에서 심하게 벗어난 값을 해결
- 스케일링
- 각각 다른 단위를 쓰는 데이터(ex : 키는 cm, 몸무게는 kg)를 비슷한 수준으로 맞춰주는 작업
대표적인 것이 정규화(0 ~ 1 사이로 범위를 맞춰줌. 즉 최솟값을 0으로 최댓값을 1로 두고 그 값들 간의 간격을 맞춰서 바꿔주는 것(데이터 왜곡 X))
[추가] 정규화와 표준화를 정리한 글
머신러닝 모델 중 일부(ex. 트리 기반의 모델)는 스케일링 과정이 필요하지 않음
- 각각 다른 단위를 쓰는 데이터(ex : 키는 cm, 몸무게는 kg)를 비슷한 수준으로 맞춰주는 작업
- 범주형 변환
- 글자로 된 정보를 숫자로 바꾸는 작업
일부 머신러닝 모델(ex. catboost)의 경우 해당 작업이 필요없기도 함
- 원-핫 인코딩 : 순서가 없는 범주형의 경우에 0과 1을 사용해 숫자를 부여
- 레이블 인코딩 : 순서가 있는 범주형의 경우에 순서대로 숫자를 부여
- 글자로 된 정보를 숫자로 바꾸는 작업
- 결측치 처리
- 모델링
- 지도학습 → 분류/회귀 알고리즘 선택(ex. 로지스틱 회귀, 랜덤 포레스트, XGBoost 등)
- 비지도학습 → 군집화/차원 축소 알고리즘 선택(ex. K-Means, PCA 등)
- 성능 평가
- 분류 : Accuracy, Precision, Recall, F1-score, ROC-AUC 등
- 회귀 : MAE, RMSE, R² 등 실제값과 예측값의 차이를 계산
- 비지도(군집화) : 실루엣 계수 등
머신러닝 활용 시 주의할 점
- 학습 데이터에 편향된 샘플이 많으면, 모델도 그 편향을 그대로 학습하기에 데이터 균형화 작업이 필요
- 또한 민감 정보 보호를 위해 개인정보 비식별화 , GDPR 등 법적 규제를 준수해야 함
데이터 전처리
데이터 전처리
- 원시(raw) 데이터에서 불필요하거나 손실(노이즈)이 있는 부분을 처리하고, 분석 목적에 맞게 가공하는 과정
- 사례①: 제조업
- 센서가 간헐적으로 측정에 실패할 경우에 결측치가 발생하기도
- 센서 오작동으로 인해 극단적으로 이상치가 기록되기도
- 정상 제품과 불량 제품의 데이터 분포가 매우 다름(불균형 데이터 imbalanced data, class imbalance)
- 사례②: 금융업
- 증권사나 은행에서 고객 정보 일부가 유실되거나, 특정 시점의 주가나 거래량 데이터가 취합되지 않은 경우 결측치가 발생하기도
- 특정 종목에 대해 드물게 발생하는 급등락(‘Flash Crash’), 단일 대량 거래에 따른 비정상적 가격 변동으로 이상치가 기록되기도
- 카드사 사기(부정 거래) 데이터(정상 거래에 비해 ‘부정 거래’는 비율이 극도로 작음)나 대출 연체(default) 사례 데이터의 경우 정상 데이터에 비해 극소수이기에 나타나는 불균형 데이터
- 사례③: 마케팅
- 온라인 설문이나 쿠폰 사용 정보가 중간에 누락되거나, 특정 채널(이메일·SNS·오프라인)에서 전송된 쿠폰 수 확인 불가한 경우에 결측치가 발생하기도
- 광고 클릭률 중 특정 상품의 노출수/클릭수가 월등히 높아 평균을 왜곡, 혹은 이벤트가 끝나자마자 조회수가 급감하는 경우에 이상치가 기록되기도
- 고객 이탈 예측 시 ‘이탈 고객’ 비율이 매우 적은 경우, 특정 광고 캠페인 전환 성공/실패 비율의 극단적 차이가 발생하는 경우 불균형 발생하기도
- 사례①: 제조업
데이터 전처리: ①결측치 처리
- 결측치 처리 기법
- 삭제
- 결측치가 있는 행(row) 또는 열(column)을 제거
- 간단하지만 데이터 손실이 발생
- 결측치가 전체 데이터에서 매우 소수일 때 적합
- 결측치가 있는 행(row) 또는 열(column)을 제거
- 대체
- 평균/중앙값으로 대체
- 수치형 데이터에서 사용
- 데이터의 분포를 왜곡하는 정도가 비교적 적음
- 최빈값으로 대체
- 범주형 데이터에서 사용
- 예측 모델로 대체 회귀/분류 모델을 이용해 결측치를 예측해 대체함
- 평균/중앙값으로 대체
- 삭제
- 결측치 처리 사례(마케팅 위주로)
- 캠페인 반응(클릭률, 전환율) 데이터의 경우
- 일시적으로 데이터가 누락된 경우엔 인접 기간(ex. 전일, 전주 동일 요일) 데이터 기반으로 보정
- 시점별로 전환 흐름이 비교적 일정하거나 특정 패턴(요일 효과 등)이 있다면 이동평균으로 추정 가능
- 고객 설문/프로필 정보의 경우
- 나이, 지역, 성별 등의 간단한 인구통계학적 정보는 최빈값·중앙값으로 대체
- 그룹(클러스터)의 대표값으로 대체 (결측값이 속한 클러스터의 평균, 중앙값 등을 사용)
돈과 관련된 데이터(ex. 구매 이력)에선 극단적인 값들이 존재하는데, 이땐 평균보단 중앙값을 사용하는 것이 더 안정적임
- 정기적으로 누락되는 채널/시점 데이터의 경우
- 특정 채널 또는 시간대에 반복적으로 누락된다면, 시스템(로그 수집, 쿠폰 트래킹 등)을 개선해 재발을 방지
- 결측이 반복되는 구간은 유사 채널 지표로 추정 (ex. 11번가의 데이터가 특정 시점에서 계속 결측이 생긴다면 해당 시간대의 네이버 스마트스토어의 지표로 대체한다든지)
- 캠페인 반응(클릭률, 전환율) 데이터의 경우
# 결측치 처리하기
# 1. 결측치 제거 (결측이 하나라도 있으면 해당 행을 제거)
df_drop = df.dropna() #어떤 옵션도 입력하지 않으면 결측값을 포함한 행을 제거함(axis=1로 하면 결측치를 포함한 열을 제거함)
df_drop
# 2. 결측치 대치: (1) 평균값으로
df_mean = df.copy()
df_mean = df_mean.fillna(df_mean.mean(numeric_only=True)) # numeric_only=True로 입력할 시에는 숫자형 데이터만 계산을 하겠다는 의미
df_mean
# 2. 결측치 대치: (2) 중앙값으로
df_median = df.copy()
df_median = df_median.fillna(df_median.median(numeric_only=True))
df_median
# 2. 결측치 대치: (3) 최빈값으로
# - DataFrame의 mode()는 각 열별로 최빈값을 반환합니다.
# - mode() 결과가 여러 개(동률)일 경우 첫 번째 행의 값을 취합니다.
df_mode = df.copy()
print(df_mode.mode()) # 확인용
mode_values = df_mode.mode().iloc[0] # 첫 번째 행(가장 상위 mode)만 취함
df_mode = df_mode.fillna(mode_values)
df_mode
데이터 전처리: ②이상치 탐지 및 처리
- 이상치 탐지 기법
- 통계적 기법 (3σ Rule)
- 데이터가 정규 분포를 따른다는 가정 하에
- 평균에서 ±3σ 범위를 벗어나는 값을 이상치로 간주
σ(sigma) : 표준편차 - 직관적이고 간단함
- [참고] 3시그마(sigma)의 의미 - 표준편차를 통한 모니터링
- 박스플롯
- 사분위수(IQR = Q3-Q1)를 이용해 'Q1 - 1.5×IQR' ~ 'Q3 + 1.5×IQR' 범위를 벗어나는 데이터를 이상치로 간주
- 데이터 분포의 특성에 영향을 적게 받음
- 머신러닝 기반 (Isolation Forest, DBSCAN 등)
- 통계적 기법 (3σ Rule)
- 이상치 처리 기법
- 단순히 제거하거나
- 이상치 값을 조정하거나
- 별도로 구분하여 모델에서 제외해 다른 모델(이상치 예측 모델)을 사용하거나
- 이상치 탐지 및 처리 사례 (마케팅 위주로)
- 어떤 광고 캠페인에서 클릭률(CTR)이 다른 캠페인에 비해 극단적으로 높아서 평균 분석을 왜곡하는 경우에 그 값들을 이상치로 분류
- 고객 구매 이력에서 특정 기간에 평소와 전혀 다른 과도한 소비(장바구니 금액 폭증)가 포착되면 마케팅 분석에서 이상치로 분류
- 이상치 처리의 경우엔 '이상치가 잘 나타나는 환경인지', '이상치가 나타난다면 어떤 식으로 나타나는지' 등 잘 알고 있어야 하기에 도메인 지식이 중요함
# 이상치 제거
# 박스플롯을 적용할 경우
Q1 = df['sensor_value'].quantile(0.25)
Q3 = df['sensor_value'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
df = df[(df['sensor_value'] >= lower_bound) & (df['sensor_value'] <= upper_bound)]
df
데이터 전처리: ③스케일링 (정규화/표준화)
- 스케일링 처리 기법
- 정규화 (→ MinMaxScaler) : 모든 값을 0과 1로 매핑
- 값의 스케일이 달라도 공통 범위로 맞출 수 있음
- 각 특성이 동일한 범위 내 있어야 하는 경우에 주로 사용함
- 최소값·최대값이 극단값(Outlier)에 민감함 그래서 극단값이 최솟값/최댓값인 경우엔 해당 방법을 잘 쓰지 않음
- 표준화 (→ StandardScaler) : 평균을 0, 표준편차를 1로 만듦
- 정규분포 가정을 사용하는 알고리즘(선형회귀, 로지스틱회귀, SVM 등)에 자주 쓰임
- 변환된 값들이 이론적으로 -∞ ~ +∞ 범위를 가질 수 있음 그러나 대부분의 값은 -3 ~ +3 사이로 나옴
- 데이터가 특정 구간([0, 1] 등)에 고정되지는 않음 이상치에 민감하지 않음
- 데이터 분포가 심하게 치우쳐 있으면 사용하기 적절하진 않음
즉 롱테일 분포처럼 정규 분포를 가정할 수 없는 상황에선 StandardScaler를 사용하기 어려움
- 정규화 (→ MinMaxScaler) : 모든 값을 0과 1로 매핑
# 1. 정규화
from sklearn.preprocessing import MinMaxScaler
# 스케일링을 적용할 컬럼만 선정
cols_to_scale = ['impressions', 'clicks', 'conversions', 'cost', 'revenue']
# MinMaxScaler 객체 생성(기본 스케일: [0,1])
minmax_scaler = MinMaxScaler()
# fit_transform을 통해 스케일링된 결과를 데이터프레임으로 변환
df_minmax_scaled = pd.DataFrame(minmax_scaler.fit_transform(df[cols_to_scale]),
columns=cols_to_scale)
print(df_minmax_scaled.max())
print(df_minmax_scaled.min())
df_minmax_scaled
# 2. 표준화
from sklearn.preprocessing import StandardScaler
# StandardScaler 객체 생성
standard_scaler = StandardScaler()
# fit_transform을 통해 스케일링된 결과를 데이터프레임으로 변환
df_standard_scaled = pd.DataFrame(standard_scaler.fit_transform(df[cols_to_scale]),
columns=cols_to_scale)
print(df_standard_scaled.mean())
print(df_standard_scaled.std())
df_standard_scaled
데이터 전처리: ④ 데이터 불균형 처리
- 데이터 불균형 처리 기법
- Oversampling
- Random Oversampling : 소수 클래스의 데이터를 단순 복제하여 개수를 늘림
- SMOTE(Synthetic Minority Over-sampling Technique)
- 소수 클래스를 "무작정 복사"만 하는 게 아니라, “비슷한” 데이터들을 서로 섞어서(Interpolation) 새로운 데이터 생성
- 소수 클래스(ex: 스팸) 안에서 가까운 데이터 둘(혹은 몇 개)을 고르고, 그 사이에 새 데이터 포인트를 만들어내어, 소수 클래스의 다양한 예시를 가상으로 늘리는 기법
- Undersampling
- 다수 클래스의 데이터를 줄임
- 데이터 손실 위험이 있지만, 전체 데이터 균형을 맞출 수 있음
- 혼합 기법
- Oversampling
# 데이터 불균형 처리
from imblearn.over_sampling import SMOTE
# 불균형 데이터 처리 (SMOTE)
X = df.drop('defect', axis=1) # 결측치 처리, 이상치 제거, 인코딩 등 사전 처리 후
y = df['defect']
smote = SMOTE(random_state=42)
X_res, y_res = smote.fit_resample(X, y)데이터 전처리: ⑤ 범주형 데이터 변환
- 범주형 데이터 처리 기법
- 원-핫 인코딩
- 범주형 변수를 각각의 범주별로 새로운 열로 표현하는 방식으로, 해당 범주에 해당하면 1, 아니면 0
(ex. 색상: 빨강, 파랑, 초록 → 빨강=1, 파랑=0, 초록=0 / 빨강=0, 파랑=1, 초록=0 / 빨강=0, 파랑=0, 초록=1) - 범주 간 서열 관계가 없을 때 사용하기 좋음
- 범주가 매우 많으면 차원이 커짐
색상이 100개면 컬럼 수가 예시 속 색상 3개와는 비교도 안 되게 많아짐
→ 이런 경우에는 중요한 것만 몇 가지 뽑고 나머지는 ‘기타’로 한 데 몰아넣는다든가, 아니면 ‘A인지, A가 아닌지’로 처리한다든가
→ Feature Hashing 같은 기법을 고려해 볼 수도 있음
- 범주형 변수를 각각의 범주별로 새로운 열로 표현하는 방식으로, 해당 범주에 해당하면 1, 아니면 0
- 레이블 인코딩
- 범주를 숫자로 직접 맵핑
(ex. ‘M’=0, ‘L’=1, ‘XL’=2 등) - 단순하지만, 모델이 숫자의 크기를 서열 정보로 잘못 해석할 수 있음 즉 순서가 없을 때는 쓰면 안 됨
- 범주를 숫자로 직접 맵핑
- 원-핫 인코딩
# 범주형 변수 변환
# 1. 원-핫 인코딩 예시
df = pd.get_dummies(df, columns=['label'])
# 2. 레이블 인코딩 예시
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df["label"] = encoder.fit_transform(df["label"])
df
피처 엔지니어링(Feature Engineering)
- 모델 성능 향상을 위해 기존의 데이터를 변형, 조합하여 새로운 특성(피처)을 만드는 작업
- 우리가 해결하고자 하는 문제를 컴퓨터가 잘 이해할 수 있도록 피처(변수)들의 형태를 변형하거나 적절하게 처리하는 과정
- 피처 엔지니어링 사례 예시 (마케팅 위주)
- 고객 행동 데이터(클릭, 구매 기록, 웹사이트 체류 시간 등)와 고객 특성 데이터(나이, 지역, 관심 분야 등)를 통합해 피처를 만들어야 효과적인 캠페인 타깃팅, 고객 세분화, 개인화 추천이 가능한 경우가 많음
- 피처 엔지니어링 실습
- 파생 변수를 생성하기
- 변수를 선택하기
- 다중공선성 문제를 피하기 위해서 상관관계수나 VIF를 고려해서 하나만 남기거나 혹은 둘 다 제거하는 처리를 함
- 트리 기반 모델(ex. 랜덤 포레스트, XGBoost 등)을 훈련 후 중요도가 낮은 변수를 제거함
'[내배캠] 데이터분석 6기 > 본캠프 기록' 카테고리의 다른 글
| [본캠프 37일차] SQL 공부, 머신러닝 공부 (0) | 2025.04.09 |
|---|---|
| [본캠프 36일차] SQL 공부, 머신러닝 공부, 파이썬 공부 (0) | 2025.04.08 |
| [본캠프 34일차] 통계학 공부, QCC ③, 파이썬 공부 (2) | 2025.04.04 |
| [본캠프 33일차] SQL 공부, 파이썬 공부, 통계학 공부, 아티클 스터디② (0) | 2025.04.03 |
| [본캠프 32일차] SQL 공부, 통계학 공부, 알고리즘 공부, 아티클 스터디① (0) | 2025.04.02 |