
어제 기준으로 2025년도 벌써 27%가 지나갔고, 오늘이 목요일이고 벌써 내일이 금요일이라는 것도 믿기지 않는다. 시간 왜 이렇게 빨리 가지?
오늘 한 일은,
- SQL 공부
- [코드카타] SQL 3문제 풀기 (125~127번)
- 통계 공부
- [통계 라이브세션] 5회차 수강하기
- 머신러닝 공부
- [실무에 쓰는 머신러닝 기초] 1-4 실습 문제 풀기
- [실무에 쓰는 머신러닝 기초] 1-5 수강하기
- 네 번째 아티클 스터디 진행하기 (누적은 24번째(11+4+5+4))
SQL 공부: [코드카타] SQL 문제 풀기(125~127번)
125. (1327) List the Products Ordered in a Period
Write a solution to get the names of products that have at least 100 units ordered in February 2020 and their amount.
Return the result table in any order.
-- 제출한 쿼리 (정답 처리됨)
SELECT p.product_name,
o.unit
FROM (
SELECT product_id,
SUM(unit) unit
FROM Orders
WHERE order_date LIKE '2020-02%'
GROUP BY product_id
) o
LEFT JOIN
Products p
ON o.product_id = p.product_id
WHERE o.unit >= 100문제가 그렇게 어렵지 않아서 금방 풀었다.
126. (1517) Find Users With Valid E-Mail
Write a solution to find the users who have valid emails.
A valid e-mail has a prefix name and a domain where:
- The prefix name is a string that may contain letters (upper or lower case), digits, underscore '_', period '.', and/or dash '-'. The prefix name muststart with a letter.
- The domain is'@leetcode.com'.
Return the result table in any order.
LIKE를 사용해서 어떻게 일일이 요구하는 조건대로 입력하는 중에 SQL에도 정규표현식이 있지 않을까 싶어서 관련 내용을 찾아봤다.
[참고 1] [SQL] SQL 정규표현식 가이드
[참고 2] [MySQL] 문자열 패턴 매칭 연산자 (REGEXP, LIKE)
[참고 3] [mySQL] 정규식 함수 REGEXP (RLIKE)
[참고 4] MySQL 문법 및 예제 정리 - LIKE, REGEXP, REGEXP_LIKE
[참고 5] MySQL 8.4 Reference Manual /…/ Regular Expressions
- 정규표현식(regular expression) : 문자열 데이터 중에서 원하는 조건과 일치하는 문자열을 찾기 위해 사용하는 일종의 패턴.
- REGEXP_LIKE(expr, pat) : expr이 요구한 pat과 일치하는 확인할 수 있는 함수 REGEXP도 같은 기능을 수행
- 패턴을 입력할 때 사용하는 문법
- ^pat : 문자열이 pat으로 시작하는가
- ^[a-z] : 문자열이 알파벳 소문자로 시작하는가
- ^[a-zA-Z] : 문자열이 알파벳으로 시작하는가
- ^[a-zA-Z0-9] : 문자열이 알파벳이나 숫자로 시작하는가
- pat$ : 문자열이 pat으로 끝나는가
- . : 임의의 한 문자
- pat+ : pat이 1회 이상 반복되는가
- ^Ba+ : 문자열이 B로 시작해서 a가 하나 이상 반복되는가
- ^[a-zA-Z]+ : 문자열이 하나 이상의 알파벳으로 시작하는가
- (pat1 | pat2) : pat1 혹은 pat2 중에서 일치하는 것이 있는가
- \\. : 연산자의 경우에 문법을 사용하기 위함이 아니라 문자 그대로 사용하고 싶으면 역슬래시(\)를 두 개 뒤에 씀
- ^pat : 문자열이 pat으로 시작하는가
- 패턴을 입력할 때 사용하는 문법

...사실 정리하자면 내용이 훨씬 더 많지만, 우선 이 정도 수준에서면 문제는 풀 수 있을 것 같아서 쿼리를 작성해보기로 했다.
-- 첫 번째 작성한 쿼리 (오답 처리, testcase24에서)
SELECT *
FROM Users
WHERE REGEXP_LIKE(mail, '^[a-zA-Z]+[a-zA-Z0-9_.-]+@leetcode.com$')
앞에 오는 이름이 대소문자 하나만 와도 통과되게 수정해야 한다.
-- 두 번째 작성한 쿼리 (오답 처리됨, testcase25에서)
SELECT *
FROM Users
WHERE (REGEXP_LIKE(mail, '^[a-zA-Z]+[a-zA-Z0-9_.-]+@leetcode.com$')) OR
(REGEXP_LIKE(mail, '^[a-zA-Z]+@leetcode.com$'))
수정한 쿼리로 testcase 24는 통과했는데, 바로 다음 사례에서 또 오답 처리가 됐다. 이번에는 도메인에 작성한 .이 문자 그대로의 .이 아니라 임의의 문자 하나로 인식되며 leetcode?com도 통과시킨 것이 문제였다.
-- 세 번째 작성한 쿼리 (정답 처리됨)
SELECT *
FROM Users
WHERE (REGEXP_LIKE(mail, '^[a-zA-Z]+[a-zA-Z0-9_.-]+@leetcode\\.com$')) OR
(REGEXP_LIKE(mail, '^[a-zA-Z]+@leetcode\\.com$'))드디어 통과!
127. Revising the Select Query 1
Query all columns for all American cities in the CITY table with populations larger than 100000. The CountryCode for America is USA.

문제 사이트가 LeetCode에서 다른 곳으로 또 바뀌었다.
-- 작성한 쿼리 (정답 처리됨)
SELECT *
FROM city
WHERE (population > 100000) AND
(countrycode = 'USA')
머신러닝 공부: [실무에서 쓰는 머신러닝 기초] 1-4~1-5 수강하기
회귀 분석 : [실습] Ridge 회귀와 Lasso 회귀 해보기
어제 공부한 회귀 분석 정리한 TIL 보러 가기 :
[본캠프 37일차] SQL 공부, 머신러닝 공부
나 공부하기도 바빠죽겠는데 기계까지 공부시키라는 게 무슨 말인가 싶었는데, 슬슬 기계를 공부시키는 게 낫다는 걸 머신러닝 공부하면서 체감하는 요즘. 통계.. 회귀..... 오늘 한 일은,SQL 공
maandoo.tistory.com

우선 새로운 강의 진도를 나가기 전에 어제 공부한 회귀 분석의 실습 문제를 풀어보려고 한다.
import numpy as np
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.linear_model import Ridge, Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# 데이터 로드 및 X와 y 정의하기
diabetes = load_diabetes()
X, y = diabetes.data, diabetes.target
필요한 라이브러리와 데이터를 불러오고서 독립 변수와 종속 변수를 정의했다.
# 학습용 데이터와 검증용 데이터 분리하기
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
그리고 train_test_split() 함수를 사용해서 학습에 사용할 데이터와 검증에 사용할 데이터를 분리해줬다.
Q. Ridge 회귀 분석해보기
# 회귀 모델 학습시키기
ridge_reg = Ridge(alpha=1.0, random_state=42)
ridge_reg.fit(X_train, y_train)
# 학습시킨 모델로 예측해보기
y_pred_ridge = ridge_reg.predict(X_test)# 모델의 예측 성능 확인하기
mse_ridge = mean_squared_error(y_test, y_pred_ridge)
r2_ridge = r2_score(y_test, y_pred_ridge)
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) *100
print('[Ridge 회귀 결과]')
print(' 가중치(coefficient): ', ridge_reg.coef_)
print(' 절편(intercept): ', ridge_reg.intercept_)
print(' MSE: ', mse_ridge)
print(' R2 점수: ', r2_ridge)
print(' 평균 비율 오차: ', MPE(y_test, y_pred_ridge))
결과를 선형 회귀와 비교해보면 가중치들이 상대적으로 부드럽게 줄어있는 모습을 확인할 수 있다.
그런데 Ridge 회귀를 사용하면 예측 성능을 좋아지게 한다고 했는데(∵과적합을 방지하고 일반성을 가지게 함으로써) 오히려 예측 성능이 더 떨어진 것으로 나와서 Ridge() 함수에서 매개변수 alpha의 값을 0.5로 낮게 조정해서 모델 ridge_reg_2 모델을 만들어 결과값을 비교해봤다.
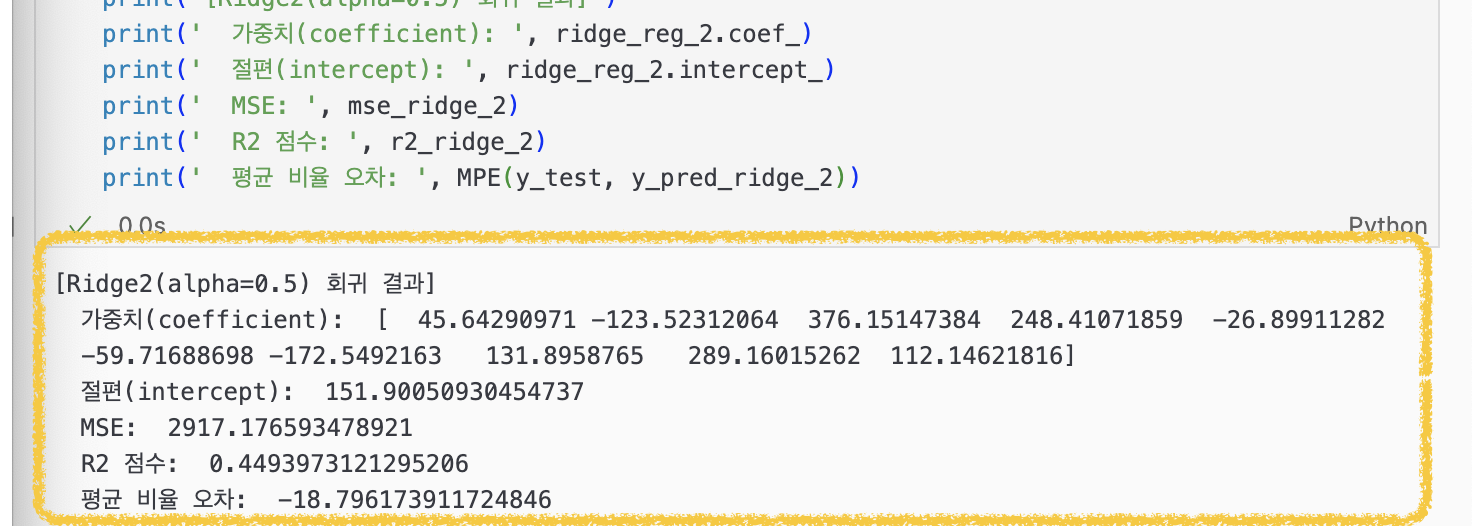
0.5로 규제 세기를 완화시켰더니 [Ridge 회귀 결과]보다 [Ridge2(alpha=0.5) 회귀 결과]가 예측 성능이 더 나아진 결과를 보였다.
Q. Lasso로 회귀 분석해보기
# 회귀 모델 학습시키기
lasso_reg = Lasso(alpha=1.0, random_state=42)
lasso_reg.fit(X_train, y_train)
# 학습시킨 모델로 예측해보기
y_pred_lasso = lasso_reg.predict(X_test)# 모델의 예측 성능 확인하기
mse_lasso = mean_squared_error(y_test, y_pred_lasso)
r2_lasso = r2_score(y_test, y_pred_lasso)
print("[Lasso 회귀 결과]")
print(" 가중치(coefficient): ", lasso_reg.coef_)
print(" 절편(intercept): ", lasso_reg.intercept_)
print(" MSE: ", mse_lasso)
print(" r2 점수: ", r2_lasso)
print(" 평균 비율 오차: ", MPE(y_test, y_pred_lasso))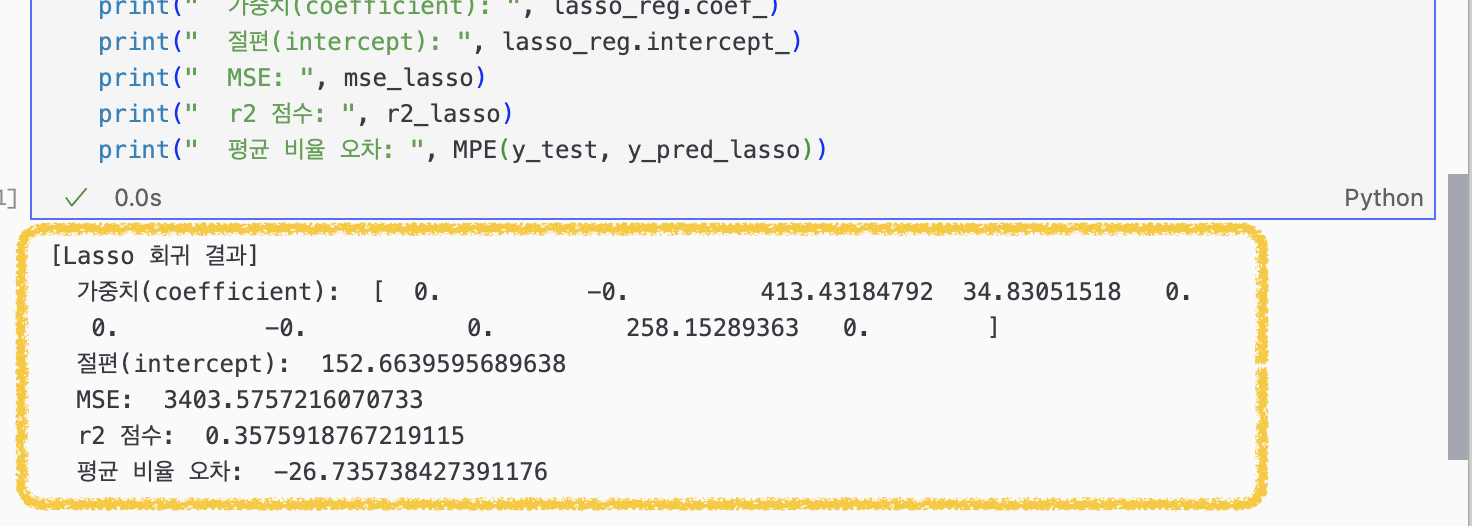
이번엔 Lasso 회귀 모델로 분석해보았는데 컬럼이 10개 있었는데 3개(순서대로 'bmi', 'bp', 's5')밖에 남지 않았다. alpha 값을 1.0 준 게 문제인가. R² 점수도 지금까지 본 것 중에 제일 안 좋다.
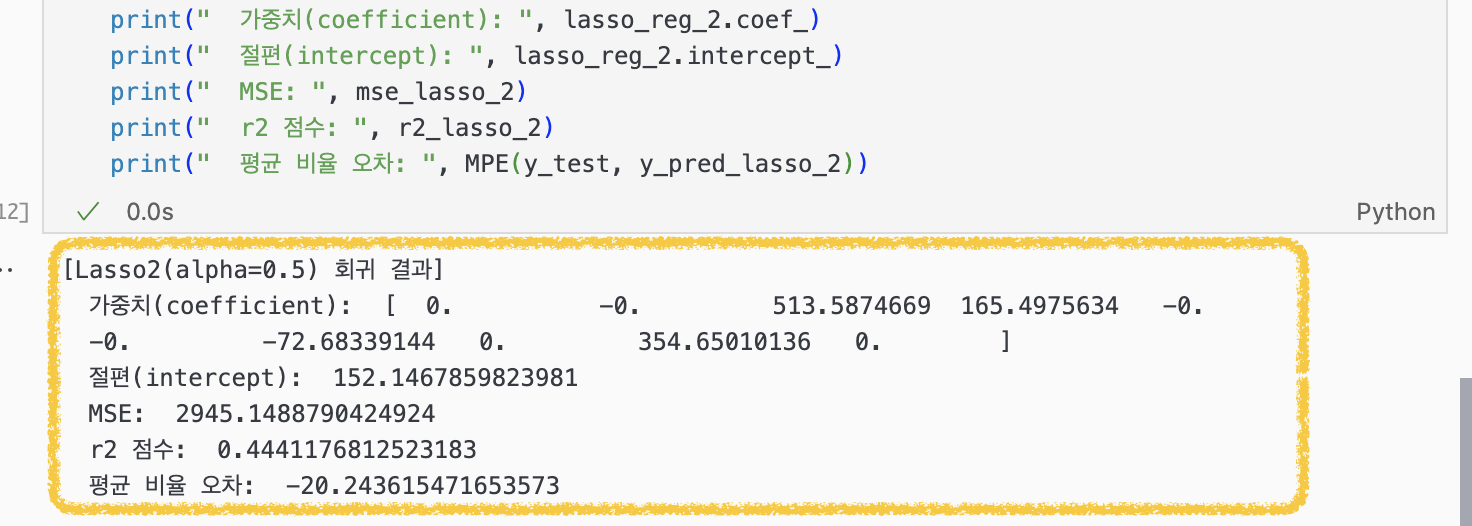
그래서 아까 ridge 회귀에서 그랬듯이, Lasso 회귀에서도 alpha 값을 0.5로 낮춰서 다시 돌려봤더니 0으로 날라가지 않은 컬럼이 하나 더 늘었다(순서대로 'bmi', 'bp', 's3', 's5').
...
근데 지금의 데이터셋에선 규제를 굳이 적용할 필요가 없다고 해석해도 되는 걸까, 아니면 더 나은 규제 모델을 찾아 alpha값을 계속 조정해봐야 하는 걸까.

분류 모델
- 머신러닝의 지도 학습 중 대표적인 유형 중 하나
- 주어진 데이터를 유형별로 구별해내는 과정으로 데이터와 데이터의 레이블 값을 학습시키고 모델을 생성함.
→ 데이터가 주어졌을 때 학습된 모델로 어느 범주에 속한 데이터인지 판단하고 예측하게 됨- ex. 스팸 메일 분류(스팸/정상), 질병 여부(양성/음성), 제조 공정 품질(불량/정상) 등
분류할 유형이 2개 → "이진 분류" / 분류할 유형이 3개 이상 → "다중 분류"
- ex. 스팸 메일 분류(스팸/정상), 질병 여부(양성/음성), 제조 공정 품질(불량/정상) 등
- 자주 사용하는 알고리즘 : 로지스틱 회귀, SVM
사실 이 2개 보다 뒤에서 배울 앙상블 모델을 많이 씀. 그래도 이 중에서 SVM도 많이 쓰긴 함 - 산업별 적용 사례 (마케팅 위주)
- 이탈 고객 예측, 캠페인 반응 예측
- 모델 : 로지스틱 회귀, 랜덤 포레스트, 나이브 베이즈
통계학적 근거를 들어서 과정을 보고 싶다면 나이브 베이즈로
주요 분류 모델 : ① 로지스틱 회귀(Logistic Regression)

- 이름에 회귀를 달고 있지만 최종적으로 예측하는 것은 부류이기 때문에 분류에 속함 (회귀 아님, 분류 모델임)
- 데이터가 어떤 범주에 속할 확률을 0~1 사이의 값으로 예측하고 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 지도 학습 알고리즘
선형회귀분석과 비슷한데, Y값이 확률로 되어 있어 하한과 상한이 0과 1 사이로 정해져 있음 - 특정 경계(threshold) 값을 기준으로 삼아 예측된 확률 값이 지정한 경계 이상인 것, 경계 미만인 것으로 분류하는 식
- 주로 이진 분류(binary classification)를 하고자 할 때 많이 사용
- 장단점
- 장점 : 계산이 빠르고 구현이 간단함, 결과 해석에 용이함(가중치로 각 변수의 영향도 해석 가능)
- 단점 : 복잡한 비선형 패턴을 학습하기엔 한계가 있음
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 1. 데이터 로드 그리고 X와 Y 선언하기 ----------------------------
iris = load_iris()
X = iris.data # 특징(feature) 데이터
y = iris.target # 타깃(target) 데이터
# 2. 학습용/검증용 데이터 분리하기 ----------------------------
# stratify=y : 클래스 비율을 train, test가 유사하게끔 맞춤 (분류 땐 해당 매개변수의 값을 설정해주는 것이 반드시 필요함)
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=42,
stratify=y)
# 3. 로지스틱 회귀 모델 학습시키기 ----------------------------
# LogisticRegression() 함수로 모델 생성
logistic_model = LogisticRegression(max_iter=200)
logistic_model.fit(X_train, y_train)
# 4. 학습시킨 모델로 예측해보기 ----------------------------
y_pred_logistic = logistic_model.predict(X_test)
# 5. 모델의 예측 성능 검증하기 ----------------------------
# accuracy_score() : 실제 데이터에서 예측 데이터가 얼마나 같은가 (정답을 맞힌 예측 데이터 건수 / 전체 예측 데이터 건수)
# classification_report()
### 매개변수 target_names : report에서 보여줄 target의 이름을 입력 (입력 안 하면 그냥 숫자 0, 1, 2 이런 식으로 뜸)
print("=== Logistic Regression ===")
print("Accuracy:", accuracy_score(y_test, y_pred_logistic))
print(classification_report(y_test, y_pred_logistic, target_names=iris.target_names))- [참고1] [Machine Learning] train_test_split() - stratify 매개변수 stratify에 대한 자세한 설명
- [참고2] sklearn classification_report를 이용한 모델 검증 나중에 report 해석할 때 보기
주요 분류 모델 : ② SVM(Support Vector Machine)
- 데이터를 가장 잘(안전 여유공간을 크게) 구분하는 경계를 찾는 알고리즘
- 두 유형을 잘 구분하는 경계를 찾는데, 두 유형이 최대한 멀리 떨어지도록(안전 여유공간이 넓도록) 찾는 방식
- 장단점
- 장점
- 차원이 높은 데이터에서도 좋은 성능을 보일 수 있음
데이터에 변수가 많아도 예측 성능이 괜찮은 편 - 결정 경계를 명확하게 찾는 경우, 예측 성능이 우수함
결정경계란? → SVM이 찾은 최적의 분류선(또는 초평면)
- 차원이 높은 데이터에서도 좋은 성능을 보일 수 있음
- 단점
- 파라미터(C, 커널 종류 등)를 적절히 찾아야 해서 튜닝 비용이 큰 편
잘 쓰기 위해선 조금 설정할 부분들이 많이 있음. 사람의 손을 탄다는 의미 - 대규모 데이터 세트에 대해서는 학습 속도가 느릴 수 있음
- 파라미터(C, 커널 종류 등)를 적절히 찾아야 해서 튜닝 비용이 큰 편
- 장점
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
# 1. 데이터 로드 그리고 X와 Y 선언하기 ----------------------------
iris = load_iris()
X = iris.data # 특징(feature) 데이터
y = iris.target # 타깃(target) 데이터
print(X.shape)
print(y.shape)
# 2. 학습용/검증용 데이터 분리하기 ----------------------------
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=42,
stratify=y)
# 3. SVM(Support Vector Machine) 모델 학습시키기 ----------------------------
# C, gamma 등의 하이퍼파라미터를 설정해서 더 최적화할 수도 있습니다.
svm_model = SVC()
svm_model.fit(X_train, y_train)
# 4. 학습시킨 모델로 예측해보기 ----------------------------
y_pred_svm = svm_model.predict(X_test)
# 5. 모델의 예측 성능 검증하기 ----------------------------
# Accuracy(정확도)와 정밀 평가(classification_report)를 이용해 비교해봅니다.
print("=== SVM ===")
print("Accuracy:", accuracy_score(y_test, y_pred_svm))
print(classification_report(y_test, y_pred_svm, target_names=iris.target_names))추가적으로 알아두면 좋은 분류 모델
- K-NN
- 나이브 베이즈
- 신경망(MLP) / 딥러닝 모델
- [참고] [머신러닝] 분류(Classification) 알고리즘
모델 평가 방법
- Cross Entropy, Hinge Loss
'[내배캠] 데이터분석 6기 > 본캠프 기록' 카테고리의 다른 글
| [본캠프 40일차] SQL 공부, 머신러닝 공부 (0) | 2025.04.14 |
|---|---|
| [본캠프 39일차] SQL 공부, QCC ④, 머신러닝 공부 (0) | 2025.04.11 |
| [본캠프 37일차] SQL 공부, 머신러닝 공부 (0) | 2025.04.09 |
| [본캠프 36일차] SQL 공부, 머신러닝 공부, 파이썬 공부 (0) | 2025.04.08 |
| [본캠프 35일차] SQL 공부, 머신러닝 공부 (2) | 2025.04.07 |