
머신러닝과 통계의 파도에 휩쓸려 이번주가 어떻게 지나간 줄 모르겠다.
오늘 한 일은,
- SQL 공부
- [코드카타] SQL
3문제10문제 풀기 (128~137번)
- [코드카타] SQL
- QCC 4회차 응시하기
- [QCC 해설 세션] 수강하기
- [QCC] 오답 정리하기
- 머신러닝 공부하기
- [실무에 쓰는 머신러닝 기초] 1-5 실습 문제 풀기
SQL 공부: [코드카타] SQL 문제 풀기(128~137번)

137. Weather Observation Station 5
Query the two cities in STATION with the shortest and longest CITY names, as well as their respective lengths (i.e.: number of characters in the name). If there is more than one smallest or largest city, choose the one that.
(note: You can write two separate queries to get the desired output. It need not be a single query.)
SELECT city,
LENGTH(city) charlen
FROM station
ORDER BY charlen, city LIMIT 1;
SELECT city,
LENGTH(city) charlen
FROM station
ORDER BY charlen DESC, city LIMIT 1;LENGTH() 함수 기초적인 함수인데도 갑자기 문자열 길이를 세라니까 기억이 안 났다. 문자열을 다뤄도 SUBSTR(), UPPER()/LOWER(), 아니면 LIKE와 %를 함께 쓰는 것만 자주 사용하니까 생각이 안 났다.
- LENGTH() : 문자열의 byte 길이를 반환
- CHAR_LENGTH() : 문자열의 길이를 반환 ← 한글로 입력된 문자열의 길이를 알고 싶을 땐 이걸로!!
그래서 이번에 찾아봤는데 문자열 길이를 셀 때 사용하는 함수는 LENGTH()와 CHAR_LENGTH() 2개가 있는데 한글의 길이를 쓸 때는 LENGTH()를 사용했을 때 원하는 결과값이 나오지 않는다는 것을 알게 됐다(영어는 둘 중 무엇을 쓰든 결과값이 동일함).
[참고] [MySQL] 문자열 길이 조회하는 방법 CHAR_LENGTH(), LENGTH()
SQL 공부: 4회차 QCC 회고

오늘은.. 어려웠다. 서버 문제 이런 건 없었고, 그냥..... 내 지식 수준이 문제였다고 한다🥲
3문제 중에 1문제 풀었다. 오답노트 잘 정리해야지. 근데 오늘 문제 난이도가 대리, 과장급이요..? 저는 신입인데요...
1. 지역별로 매출이 가장 높은 매장 조회하기
지역별로 매출이 가장 높은 매장을 조회하는 SQL문을 작성해주세요.
단, 해당 지역에 매장이 두 개 이상인 경우만 결과에 포함해주세요.
결과는 지역 이름을 기준으로 오름차순 정렬해주세요.
-- 제출한 쿼리
SELECT region_name,
MAX(sales) highest_sales
FROM stores
GROUP BY region_name
HAVING COUNT(store_id) >= 2
ORDER BY region_name-- 튜터님이 올려주신 1번 정답 쿼리
SELECT
region_name,
MAX(SALES) AS highest_sales
FROM qcc.stores
GROUP BY REGION_NAME
HAVING COUNT(DISTINCT STORE_ID) > 1
ORDER BY REGION_NAME오늘 제출한 유일한 문제, 혹시라도 틀렸으면 어쩌나 했는데 튜터님의 쿼리와 비교해보니 다행히도 맞혔다. 소중한 내 100 포인트
2. 서로 다른 두 제품을 주문한 건수 집계하기
데이터 분석팀은 고객이 특정 상품 X를 구매했을 때 상품 Y도 함께 구매할 확률을 분석하고자 합니다. 이를 위해, 쇼핑 카트 데이터에서 서로 다른 두 제품 X와 Y가 같은 주문(cart_id)에 포함된 주문 수를 확인하려고 합니다.
- 제품 X와 Y가 같은 주문에 포함된 경우를 계산합니다.
- 두 제품은 서로 다른 이름이어야 하며 한 쌍의 경우(ex. Cola, Big Mac)는 다른 순서(ex. Big Mac, Cola)로도 포함됩니다.
- 결과는 각 제품 쌍과 해당 제품이 함께 포함된 주문 수를 반환해야 합니다.
- 제품 이름 X와 Y를 기준으로 알파벳 순으로 오름차순 정렬합니다.

이 문제는 보다가 'CROSS JOIN으로 풀어야 하는 것 같은데 그렇게 푸는 것 모르겠는데.. 우선 3번 풀고서 다시 돌아와서 해봐야지!' 이러고 3번으로 넘어갔다. (그렇게 2번으로 돌아오지 못했다고 한다.....)
그런데 해설 세션에서 튜터님이 SELF JOIN으로 푸는 게 아니겠어요..?

이 문제를 SELF JOIN으로도, CROSS JOIN으로도 풀 수 있다고 하니까 두 방식으로 시험이 끝나고서 문제를 풀어보기로 했다.
우선 SELF JOIN으로 문제를 풀어보았다.
-- 1. SELF JOIN으로 작성해 본 쿼리
SELECT cp1.name name_x,
cp2.name name_y,
COUNT(*) orders
FROM (
SELECT cart_id,
name
FROM cart_products
) cp1
LEFT JOIN
(
SELECT cart_id,
name
FROM cart_products
) cp2
ON cp1.cart_id = cp2.cart_id
WHERE cp1.name != cp2.name
GROUP BY cp1.name, cp2.name
ORDER BY cp1.name, cp2.name
셀프 조인은 같은 테이블 내의 데이터를 조인합니다. 즉, 하나의 테이블이 자기 자신을 대상으로 조인하는 것을 말합니다. 왜 본인을 조인하냐고요? 종종 우리는 한 행에 있는 값을 같은 행에 있는 다른 값과 비교해야 할 때가 생기고는 합니다. 이를 해결하려면 자기 자신 테이블을 조인하여 같은 행의 데이터 값을 가지고 비교하는 방법밖에는 없기 때문입니다.
(출처 : SELF JOIN (下) : 셀프 조인의 용례)
SELF JOIN을 몰랐던 것도 아닌데, 왜 CROSS JOIN으로 풀어야 한다고 생각하고 '아, 이 문제는 다시 와서 풀어야겠다..!' 생각하고 넘어갔을까. 바보, 바보야~~

SELF JOIN은 주로 3가지 상황에서 사용하는데, 그 중 오늘 QCC 2번으로 나온 문제는 "1개의 테이블 안에 관계성이 명시되어야 할 데이터가 여러 개 존재할 때"에 해당하는 상황이었다. 앞으로는 잘하자, 미래의 나야.
다음으로 CROSS JOIN으로도 문제를 풀기 위해 해당 문법에 대해서 찾아보았다.
-- CROSS JOIN 기본 문법
SELECT *
FROM table1 CROSS JOIN table2;
/*
아래와 같이 적어도 위와 같은 테이블이 나온다
SELECT *
FROM table1, table2;
*/-- 2. CROSS JOIN으로 작성해 본 쿼리
SELECT cp1.name name_x,
cp2.name name_y,
COUNT(*) orders
FROM (
SELECT cart_id,
name
FROM cart_products
) cp1
CROSS JOIN
(
SELECT cart_id,
name
FROM cart_products
) cp2
WHERE (cp1.name != cp2.name) AND
(cp1.cart_id = cp2.cart_id)
GROUP BY cp1.name, cp2.name
ORDER BY cp1.name, cp2.name
CROSS JOIN의 경우에는 공통 컬럼을 적어줄 필요가 없다. 그래서 WHERE절로 조건을 걸어줘야 한다.
3. 주문-결제 버그 발견하기
최근 특정 사용자들이 결제를 하지 않고 상품을 주문하거나, 결제를 하지 않은 시점에 이미 상품을 주문하는 버그가 발견되었습니다.
해당 버그를 악용한 사용자를 파악하기 위해 SQL문을 작성해주세요.
다음 조건에 해당되는 사용자 수를 출력해주세요 :
- 결제를 하지 않고 상품을 주문한 사용자
- 첫 번째 결제일보다 이전에 상품을 주문한 사용자

-- 쓰다 쓰다가 제출 못한 쿼리..
/* SELECT *
FROM (
SELECT user_id,
order_date
FROM orders
) o
LEFT JOIN (
SELECT user_id,
pay_date
FROM payments
) p
ON o.user_id = p.user_id
WHERE (p.pay_date IS NULL) */
WITH po AS (
SELECT o.user_id,
SUBSTR(o.order_date, 1, 10) order_date,
SUBSTR(p.pay_date, 1, 10) pay_date
FROM (
SELECT user_id,
order_date
FROM orders
) o
LEFT JOIN (
SELECT user_id,
pay_date
FROM payments
) p
ON o.user_id = p.user_id
)
SELECT *
FROM (
SELECT *,
MIN(pay_date) OVER(PARTITION BY user_id) fir_pay
FROM po
) po2
GROUP BY po2.user_id
HAVING po2.fir_pay > po2.order_date
진짜 이 문제만 몇 십 분을 붙들고 있었던 건지.. 나름 이것저것 확인해보겠다고 각주 처리해놓고 다른 거 적어보고, 이러다가 머리가 복잡해져서 '아, 다시 지우고 처음부터 써야겠는데?' 싶었을 때 시계를 확인해보니 시험 종료까지 3분 남은 시점이었다고 한다.. 흑흑
-- 튜터님의 3번 정답 쿼리
WITH first_payment AS (
SELECT
USER_ID,
MIN(PAY_DATE) AS FIRST_PAY_DATE
FROM qcc.payments
GROUP BY USER_ID
)
SELECT
COUNT(DISTINCT o.USER_ID) cnt
FROM qcc.orders o
LEFT JOIN first_payment fp
ON o.USER_ID = fp.USER_ID
WHERE fp.USER_ID IS NULL
OR o.ORDER_DATE < fp.FIRST_PAY_DATE대충 나도 뭘가 생각을 하긴 했는데 하나의 쿼리로 결국 정리가 안 됐다... 확실히 WITH 구문으로 쓰는 게 가독성 면에서 깔끔하다.
머신러닝 공부: [실무에서 쓰는 머신러닝 기초]

우선 오늘치 공부를 시작하기 전에 어제 [머신러닝 1-4. 회귀]의 실습 문제를 풀면서 의문이 생긴 점에 대해서 튜터님께 찾아가 질문을 드렸다.
- ❓규제 모델을 사용하면 일반적으로 예측 성능이 좋아진다는데, 규제 모델(Ridge()나 Lasso())을 쓴 것이 기존의 선형 회귀 모델(LinearRegression())보다 예측 성능이 더 안 좋거나 아니면 별반 차이가 없다. 그러면 이런 상황은,
① 더 나은 규제 모델을 찾기 위해 alpha 매개변수의 값을 계속 바꿔보면서 시도해봐야 하는 것인지
② 아니면 애초에 이 데이터에는 굳이 규제 모델을 쓸 필요가 없다고 해석해야 하는 것인지
- 👨🏻🏫 우선 규제 모델은 과적합을 피하기 위해 쓰는 것이기 때문에 값들의 편차가 클 때에 사용하는 것이다. 그래서 단순한 데이터셋에서 써서 이런 결과가 나온 것일 수도 있다.
- ❓매개변수 alpha의 값을 입력할 때, 어디서부터 시작한다는 기준이 되는 값이 있다거나 아니면 어떤 식으로 alpha 값을 찾아나가는지
- 👨🏻🏫 사실 alpha값을 1.0로 주는 것은 너무 높긴 하다. 보통은 작은 값에서 값을 키워가는 방향으로 조정해나간다.
(+)
[참고] [머신러닝] 릿지ᐧ라쏘모델의 성능비교와 알파값 조정
그리고 alpha 값을 조정하는 것을 찾아보다가 나중에 머신러닝 모델의 결과를 예측할 때 참고하기에 좋은 글을 발견해서 여기에 기록해둔다.
분류 모델 : [실습] Wine 데이터 분류하기

오늘 수업을 듣기 전에 어제 배운 분류 실습 문제부터 풀어보았다.
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.metrics import roc_curve, roc_auc_score
import matplotlib.pyplot as plt
# Wine 데이터셋 로드 및 X와 y 정의하기
wine = load_wine()
X = wine.data
y = wine.target우선 주어진 코드스니펫으로 와인 데이터를 불러왔다.
[참고1] Scikit Learn의 기본 데이터셋 목록들
[참고2] scikit-learn의 데이터셋 활용
[참고3] scikit-learn user guide / 7.1 Toy datasets

sklearn에서 제공하는 데이터셋들은 딕셔너리 형태로 데이터셋에 대한 정보들을 담고 있다고 한다. 그래서 .keys() 메소드로 key들을 볼 수 있다.

데이터를 정보를 보려고 이것저것 출력해봤는데 key 중에서 target_names는 레이블 값을 볼 수 있다. 그래서 출력해봤는데 유형이 3가지다.
# 학습용 데이터와 검증용 데이터 분리하기
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
그리고 train_test_split() 함수를 사용해서 학습에 사용할 데이터와 검증에 사용할 데이터를 나눴다. 그 중에서 분류에 사용할 데이터를 나눌 때는 stratify 매개변수를 입력해줘야 한다. 데이터를 나눌 때, 아래의 그림에서 왼쪽과 같이 나눠지지 않게끔 하는 역할을 하는 것이 stratify다.


Q. Logistic Regression 모델로 분류하기
이제 로지스틱 회귀 모델부터 해보려고 하는데 LogisticRegression() 함수의 파라미터 몇 개에 대해서 좀 알아보고 싶어서 찾아봤다.
[참고1] [sklearn] 파이썬 로지스틱 회귀 모형 / logistic regression 파라미터, 속성, 메서드_사이킷런
[참고2] 로지스틱 회귀(다항 로지스틱) - 인프런 | 커뮤니티 질문&답변
[참고3] [로지스틱 회귀] Solver 종류와 장단점
[참고4] [지도 학습] 로지스틱 회귀 (Logistic Regression)
- LogisticRegression() 주요 매개변수
- penalty : 규제의 종류를 선택함 (기본='l2')
- 선택할 수 있는 옵션은 4개: 'l1', 'l2', 'elasticnet', 'none'
- C : 규제의 강도를 조절함(alpha의 역수!!) (기본=1.0)
- 값이 클수록 규제가 약해지고, 값이 작을수록 규제가 강해짐
- 보통 10배씩 지정함 (0.001, 0.01, 0.1, 1, 10...)
- solver : 최적화 문제를 풀기 위한 알고리즘을 선택함 (기본='lbfgs')
- 선택할 수 있는 옵션은 5개: 'newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga'
- newton-cg, lbfgs는 뉴튼 랩슨 방법을, liblinear, sag, saga는 경사하강법을 사용
경사하강법이 학습 속도가 빨라 뉴튼 랩슨 방법은 잘 사용하지 않으나, 전통적인 통계학에선 모델이 복잡하지 않아서 계속 사용한다고 함. - 작은 데이터셋 → liblinear / 큰 데이터셋 → sag, saga
- multi_class : 다중 분류의 상황에서 어떤 접근 방식을 택할 것인지를 결정 (기본='auto')
- 'ovr' : One Vs Rest 분류 방식으로 각 클래스 레이블에 대해 이진 분류 문제를 품
- 'multinomial' : 각 클래스에 대한 softmax 확률값, 크로스 엔트로피 계산을 통해 원-핫 타겟 벡터를 생성하는 식으로 문제를 품
- 기본값 auto에선 타겟값이 유형에 따라 자동으로 이진 분류 혹은 다중 분류를 적용함
- max_iter : 학습을 반복하는 최대 횟수 (기본=100)
- penalty : 규제의 종류를 선택함 (기본='l2')
...우선 여기까지만 정리해놓고 이제 그만 모델을 생성해보자.
# 로지스틱 회귀 모델 학습시키기
logistic_model = LogisticRegression(solver='liblinear', max_iter=500)
logistic_model.fit(X_train, y_train)
# 학습시킨 모델로 예측해보기
y_pred_logistic = logistic_model.predict(X_test)
y_proba_logistic = logistic_model.predict_proba(X_test)로지스틱 모델을 생성할 때 solver 매개변수를 liblinear를 입력해봤다.
이제 모델의 예측 성능을 확인할 차례인데 문제에서 요구한 것은 정확도, 분류 보고서, 혼동행렬, ROC, AUC이다. 먼저 혼동행렬까지 그려서 구해봤다.
# 모델의 예측 성능 확인하기 (정확도, 분류 보고서, 혼동행렬, ROC, AUC)
print("======== Logistic Regression ========")
print("Accuracy: ", accuracy_score(y_test, y_pred_logistic))
print(classification_report(y_test, y_pred_logistic, target_names=wine.target_names))
print(confusion_matrix(y_test, y_pred_logistic)) # 혼동행렬
그리고 이제 ROC와 AUC를 계산하고 시각화를 해야 할 차례인데,
[참고1] [Scikit-Learn] Multiclass ROC Curve 그리기
[참고2] 스터디 노트🖊️_Day 53(ML/머신러닝)
[참고3] Classification - Metrics (2)

진짜 에러만 몇 번을 뜬 끝에 클래스별로 곡선을 그려야 한다는 것도 알았고, roc_auc_score()에 multi_class 매개변수를 입력해줘야 한다는 것도 알았는데, 또 다른 에러 등장..!

이미 너무 많은 글을 보고 또 보고 하면서 지쳐버린 터라 결국 개인 과외를 받으러 가는데...


그러니까 지금 y_test는 1차원 배열인데 2차원으로 접근하려 한 것이 문제라는 것인데 그를 해결하기 위해 label_binarize()로 2차원으로 바꿔줘야 한다고 했다.
- .predict_proba()를 사용해서 ROC 곡선과 AUC를 계산할 수 있음
- 단, ROC 곡선은 이진 분류 문제에서 주로 쓰임
→ 다중 분류에서 사용하고 싶다면 추가적으로 처리해줘야 함- ① roc_auc_score()에서 multi_class='ovr'로 지정해야 전체적인 AUC를 구할 수 있음
- ② sklearn.preprocessing.label_binarize로 라벨 이진화 해야 함
# 모델의 예측 성능 확인하기2 (ROC, AUC)
# ROC 곡선 계산하기
# AUC 계산하기
# (1)에러 코드 떠서 multi_class 매개변수 입력해 줌: "ValueError: multi_class must be in ('ovo', 'ovr')"
# 일반적으로 ovr을 사용한대서 그렇게 함
auc_score = roc_auc_score(y_test, y_proba_logistic, multi_class='ovr')
# ROC 곡선 시각화하기
# (2) 또 에러 코드 뜸: IndexError: too many indices for array: array is 1-dimensional, but 2 were indexed
# 라벨을 이진화해줘야 한대 (ex. a인 것 vs a 아닌 것)
from sklearn.preprocessing import label_binarize
from sklearn.metrics import auc
y_test_bin = label_binarize(y_test, classes=[0 ,1, 2])
plt.figure()
colors = ['royalblue', 'forestgreen', 'tomato']
for i in range(len(wine.target_names)):
fprs, tprs, _ = roc_curve(y_test_bin[:, i], y_proba_logistic[:, i])
roc_auc = auc(fprs, tprs)
plt.plot(fprs, tprs, color=colors[i], label=f'class {i} (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], 'k--', lw=1)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve(Multiclass OvR)')
plt.legend()
plt.show()
# AUC 점수 출력 (전체 AUC)
overall_auc = roc_auc_score(y_test_bin, y_proba_logistic, multi_class='ovr')
print("Overall ROC-AUC Score: ", overall_auc)
시각화로 하고 하니까 class 0과 class 2는 선이 겹쳐서 하나만 보이길래 한 화면에 3가지를 각각 그려서도 시각화해봤다.
# 클래스 이름과 수
class_names = wine.target_names
n_classes = len(class_names)
fig, axs = plt.subplots(1, 3, figsize=(18, 5))
for i in range(n_classes):
# 클래스 이진화하기
y_test_binary = (y_test == i).astype(int)
y_score = y_proba_logistic[:, i]
fpr, tpr, _ = roc_curve(y_test_binary, y_score)
roc_auc = auc(fpr, tpr)
# 시각화하기
axs[i].plot(fpr, tpr, color=colors[i], lw=2, label=f'ROC curve (AUC = {roc_auc: .2f})')
axs[i].plot([0, 1], [0, 1], color='navy', lw=1, linestyle='--')
axs[i].set_xlabel('False Positive Rate')
axs[i].set_ylabel('True Positive Rate')
axs[i].set_title(f'ROC Curve - Class {i} ({class_names[i]})')
axs[i].legend(loc="lower right")
plt.tight_layout()
plt.show()
Q. SVM 모델로 분류하기
로지스틱 회귀 모델로 할 거 다했으니 이젠 SVM 모델로 넘어가자. (터덜터덜...)
우선 SVC()의 주요 매개변수들을 알아봤다.
[참고1] 서포트 벡터 머신(SVM, Support Vector Machine) [내가 공부한 머신러닝 #21.]
[참고2] [Sklearn] 파이썬 서포트 벡터 머신 분류기(SVM) - SVC 함수 사용법
- SVC() 주요 매개변수
- kernel : 커널 함수 종류를 linear, poly, rbf, sigmoid, precomputed 중에 지정할 수 있음 (기본='rbf')
- gamma : kernel이 'rbf', 'poly', 'sigmoid'인 경우에 유효하고, 영역 구분 시 가까이 있는 데이터들 간의 영향력을 결정함 (기본='auto')
- C : 규제화 정도 (기본=1.0)
- C 값이 낮을수록 강한 제약이 설정됨 (모델이 과적합된 경우에 일반화 성능을 높이기 위해 사용)
- C 값이 높을수록 약한 제약이 설정됨 (모델이 과소적합된 경우에 학습 성능을 높이기 위해 사용)
- degree : kernel='poly'일 때만 유효, 함수를 몇 차로 지정할지
이래저래 찾아보다가 "커널은 사전 지식이 없다면 기본적으로 RBF를 쓰는 것이 좋음"이라길래 커널은 기본값으로 가기로 했다.
# svm 모델 학습시키기
# .predict_proba() 구하려니까 에러 떠서 probability 매개변수 True로 설정함
svm_model = SVC(max_iter=500, probability=True)
svm_model.fit(X_train, y_train)
# 학습시킨 모델로 예측해보기
y_pred_svm = svm_model.predict(X_test)
y_proba_svm = svm_model.predict_proba(X_test)[참고] SVC 모델에서 'probability=True' 설정의 확률 예측에 대한 중요성 이해하기
이따가 ROC, AUC도 계산해야 하니까 .predict_proba()도 적었는데 에러가 떠서 찾아보니 SVM 모델을 생성할 때 SVV()에 probability=True로 설정해야 한다고 한다.
# 모델의 예측 성능 확인하기(1) (정확도, 분류 보고서, 혼동행렬)
print("======== Logistic Regression ========")
print("Accuracy: ", accuracy_score(y_test, y_pred_svm))
print(classification_report(y_test, y_pred_svm, target_names=wine.target_names))
print(confusion_matrix(y_test, y_pred_svm)) # 혼동행렬
...? 근데 정확도가 왜 이러지. class_2는 정밀도도, 재현율도 왜 저러는 거지...?? 혼동행렬을 보면 class 2에 해당하는 것들을 class 2로 나눈 것은 0이라는 충격적인 결과를 확인할 수 있다.

로지스틱 회귀와 SVM 모델의 결과를 확인했을 때를 보면 SVM이 사람 손을 더 탄다는 게 무슨 의미인지 알겠다. 그래서 SVC() 파라미터를 변경하면서 결과를 보기로 했다.
1️⃣ kernel='linear'로 변경하기
# svm 모델 결정하기(1): kernel을 linear로 설정
svm_model_linear = SVC(kernel='linear', max_iter=500, probability=True)
svm_model_linear.fit(X_train, y_train)
# 학습시킨 모델로 예측해보기
y_pred_svm_linear = svm_model_linear.predict(X_test)
# 모델의 예측 성능 확인하기(1) (정확도, 분류 보고서, 혼동행렬)
print("======== SVM(kernel='linear') ========")
print("Accuracy: ", accuracy_score(y_test, y_pred_svm_linear))
print(classification_report(y_test, y_pred_svm_linear, target_names=wine.target_names))
print(confusion_matrix(y_test, y_pred_svm_linear))
kernel 기본이 'rbf'라고 했으니까 이번에는 'linear'로 변경해봤다.
class 2의 결과는 10개 중에 9개를 맞히면서 좋은 성능을 보여줬지만 이번에는 class 1의 결과가 처참하게도 하나도 맞히질 못했다.
사실 c나 gamma 값을 찾아보기 귀찮아서 가장 만만했던 것부터 한 것인데 아무래도 c나 gamma를 건들여보는 일은 피할 수 없는 것 같다. 그런데 일일이 값을 변경해보기에는 대체 몇 번을 시도해봐야 하는지 감도 안 와서 아무래도 Grid Search를 찾아서 그 방법으로 구해봐야 할 것 같다.
2️⃣ C와 gamma 변경하기 (feat. Grid Search로 최적의 값 찾기)
# svm 모델 결정하기(2): c와 gamma 값 찾아보기
# GridSearchCV() 사용해보기
from sklearn.model_selection import GridSearchCV
# grid로 탐색할 값의 범위 설정하기
param_grid = {
'C' : [0.1, 1, 10, 100, 1000],
'gamma' : ['scale', 0.1, 0.01, 0.001]
}
grid = GridSearchCV(
SVC(max_iter=500, probability=True),
param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1)
grid.fit(X_train, y_train)
# 학습시킨 모델 중 최적의 매개변수 값 결과 보기
print("best parameter:", grid.best_params_)
print("best Cross-Validation Score:", grid.best_score_)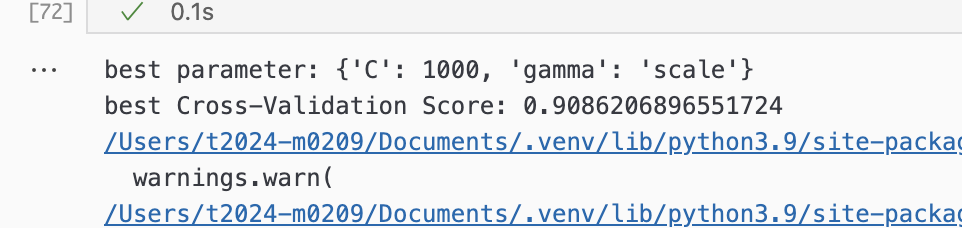
찾은 최적의 값으로 모델을 설정해서 다시 모델 예측 성능을 확인해보면,
# svm 모델 결정하기(2): c=1000, gamma='scale'로 설정
svm_model_2 = SVC(C=1000, gamma='scale', max_iter=500, probability=True)
svm_model_2.fit(X_train, y_train)
# 학습시킨 모델로 예측해보기
y_pred_svm_2 = svm_model_2.predict(X_test)
y_proba_svm_2 = svm_model_2.predict_proba(X_test)
# 모델의 예측 성능 확인하기(2) (정확도, 분류 보고서, 혼동행렬)
print("======== SVM(C=1000, gamma='scale') ========")
print("Accuracy: ", accuracy_score(y_test, y_pred_svm_2))
print(classification_report(y_test, y_pred_svm_2, target_names=wine.target_names))
print(confusion_matrix(y_test, y_pred_svm_2))
C와 gamma를 설정하지 않았을 때보다 많이 괜찮아졌다.
그리고 이제 ROC 곡선과 AUC를 계산해보자.
# 모델의 예측 성능 확인하기2(ROC, AUC)
# AUC 계산하기
auc_score_svm2 = roc_auc_score(y_test, y_proba_svm_2, multi_class='ovr')
# ROC 곡선 시각화하기
fig, axs = plt.subplots(1, 3, figsize=(18, 5))
colors = ['royalblue', 'forestgreen', 'tomato']
for i in range(n_classes):
y_test_binary = (y_test == i).astype(int)
y_score = y_proba_svm_2[:, i]
fpr, tpr, _ = roc_curve(y_test_binary, y_score)
roc_auc = auc(fpr, tpr)
axs[i].plot(fpr, tpr, color=colors[i], lw=2, label=f'ROC curve (AUC = {roc_auc: .2f})')
axs[i].plot([0, 1], [0, 1], color='navy', lw=1, linestyle='--')
axs[i].set_xlabel('False Positive Rate')
axs[i].set_ylabel('True Positive Rate')
axs[i].set_title(f'ROC Curve - Class {i} ({class_names[i]})')
axs[i].legend(loc='lower right')
plt.suptitle("ROC Curves (model: SVM)")
plt.tight_layout()
plt.show()
앙상블 기법(Ensemble)
앙상블 기본 개념
- 여러 개의 모델을 생성하고 그 예측값을 결합함으로써 하나의 모델보다 더 좋은 예측 성능을 내는 방법
- 서로 다른 모델을 결합함으로써 오류를 줄일 수 있음
- 개별 모델의 편향(bias)과 분산(variance)을 상호 보완함
- 앙상블 기법 : ① 배깅, ② 부스팅 그밖에 보팅(voting), 스태킹(stacking)도 있는 것 같음(근데 다른 기법과 섞어서 쓰는 것 같음..?)

앙상블 기법: ① 배깅(bagging, bootstrap aggregation)
- 표본을 여러 번 뽑아(bootstrap) 각 모델을 학습시켜서 결과물을 집계(aggregation)하는 방법
- 각 모델들이 공통된 훈련 데이터셋에서 학습하지만, 중복을 허용하여 다양한 데이터 셋을 사용하기에 개별 모델들이 서로 다른 방향으로 편향되는 현상을 줄일 수 있음 과적합을 줄여줌(= 예측의 분산 감소함)
- 장단점
- [장] 모델들을 병렬적을 학습시키기에 학습 속도가 빠르고 모델 간 독립성이 높기 때문에 확장성 또한 높음
- [단] 많은 수의 모델을 학습시키기에 메모리 사용량이 많아질 수 있음
- 대표 모델 : 랜덤 포레스트
앙상블 기법: ② 부스팅(boosting)
- 순차적으로 모델을 학습시키면서 이전 모델이 만든 예측 오류를 보정하도록 설계함
- 이전 모델이 잘못 예측한 데이터에 가중치를 부여해 다음 모델이 그 표본에 더 집중적으로 보완하도록 함
- 일반적으로 분류 문제에서 많이 사용함
- 장단점
- [장] 각 모델들이 서로 다른 방향으로 편향될 가능성이 적기 때문에 예측 성능이 더욱 뛰어남
- [단] 개별 모델들을 순차적으로 학습시키기에 학습 속도가 느릴 수 있음
- [단] 하이퍼파라미터가 많고 튜닝이 까다로운 편임
- 대표 모델 : XGBoost, LightGBM, CatBoost
과적합(Overfitting) vs 과소적합(Underfitting)
과적합
- 학습 데이터에 지나치게 최적화되어 새로운 데이터에 대한 성능이 떨어지는 현상 일반화가 안 됨
- 원인
- 모델의 매개변수가 너무 많아서 복잡도가 높음 과적합은 모델이 복잡하면 잘 발생함
- 학습 데이터 수가 충분하지 않음
- 너무 많이 학습함 max_iter 매개변수의 값이 너무 높아서일 수도 있기에 이를 낮추는 방향으로 조정해야 할 수도
- 노이즈가 많은 훈련 데이터를 학습함
애초에 데이터에 노이즈가 많은 경우에는 전처리를 통해 이상치 제거, 불필요한 데이터 제거 등 방법을 시도해야 함
- 해결법
- 규제화 기법
- 데이터 증강
- 조기 종료
- 앙상블 기법을 사용
과소적합
- 학습 데이터에 대한 성능이 안 좋은 현상
- 해결법
- 모델의 복잡도를 높임
- 더 많이 학습 시킴
- 모델의 구조를 변경함
하이퍼파라미터(Hyperparameter)
- 사람이 직접 설정해야 하는 값
'[내배캠] 데이터분석 6기 > 본캠프 기록' 카테고리의 다른 글
| [본캠프 41일차] SQL 공부, 머신러닝 공부 (1) | 2025.04.15 |
|---|---|
| [본캠프 40일차] SQL 공부, 머신러닝 공부 (0) | 2025.04.14 |
| [본캠프 38일차] SQL 공부, 머신러닝 공부 (0) | 2025.04.10 |
| [본캠프 37일차] SQL 공부, 머신러닝 공부 (0) | 2025.04.09 |
| [본캠프 36일차] SQL 공부, 머신러닝 공부, 파이썬 공부 (0) | 2025.04.08 |